Sequential and Parallel Architectures All in One
XGBoost (eXtreme Gradient Increase) is a robust studying algorithm which had outperformed many standard Machine Studying algos in lots of competitions prior to now.
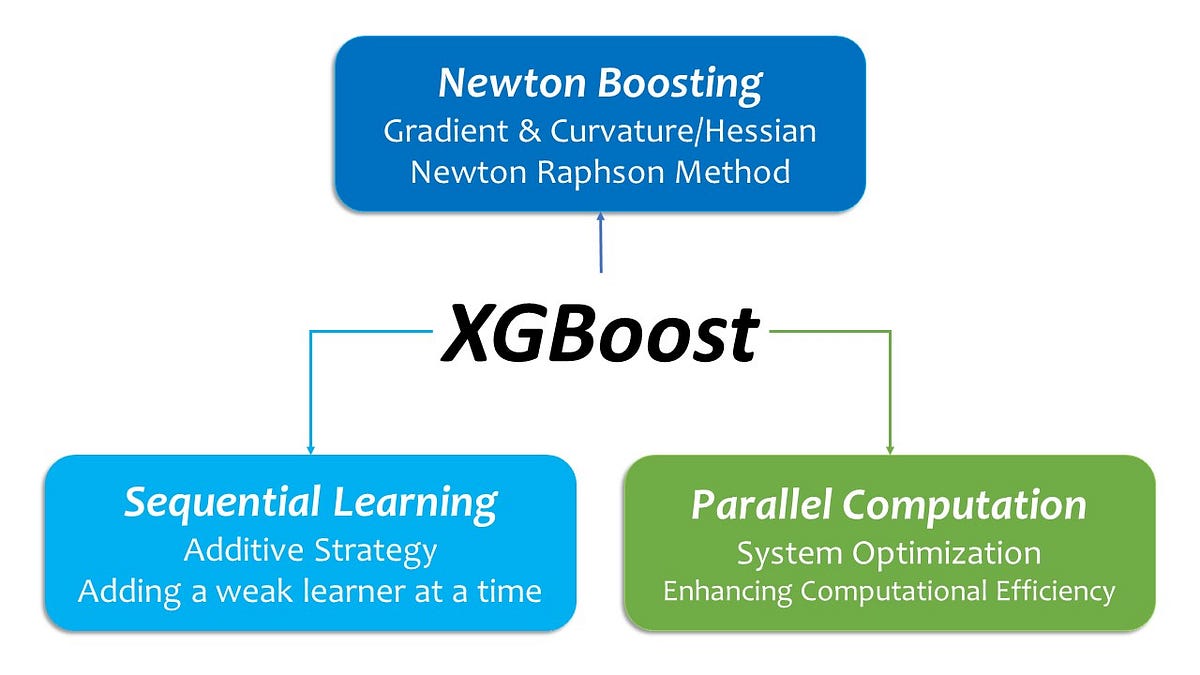
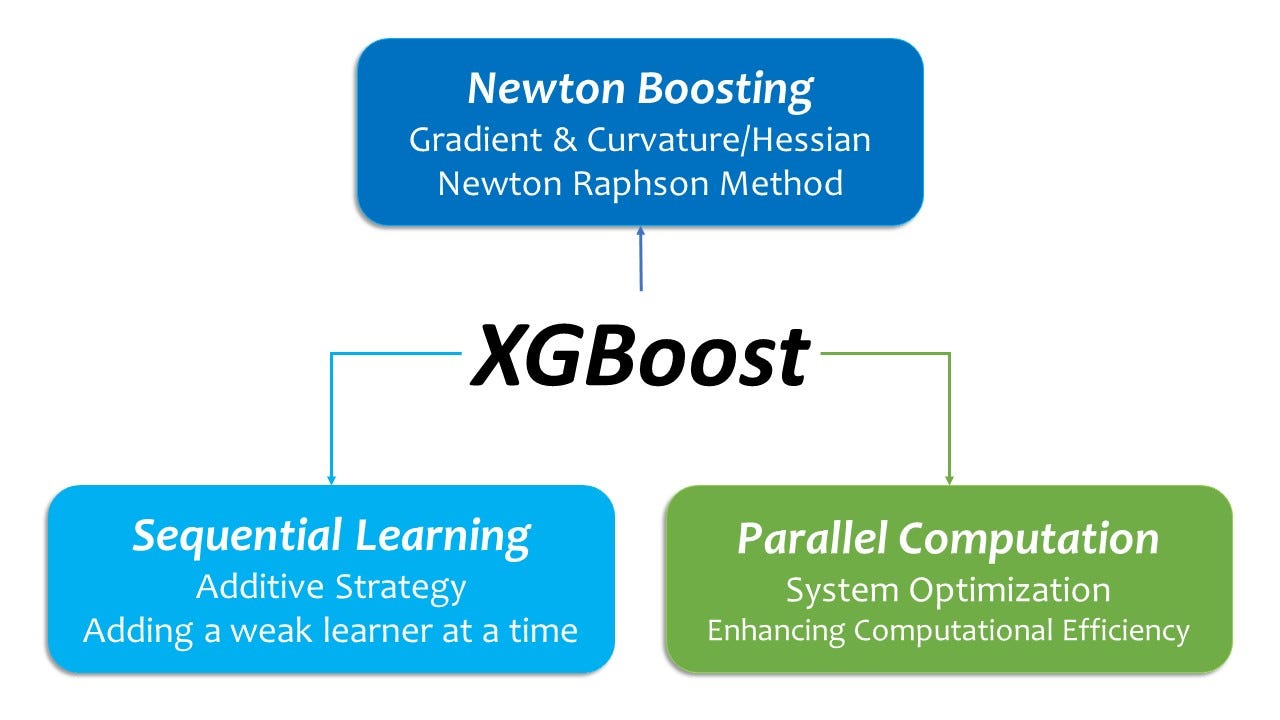
In a nutshell, XGBoost is supplied with each sequential and parallel architectures multi function: whereas it’s a sequential studying algorithm (additive technique), it incorporates parallel computation into its structure so as to improve the system effectivity.
This submit is an introductory overview of XGBoost for newbies and serves a one-stop article that will offer you a giant image, if not particulars, about XGBoost — its family tree, its architectural options, and its modern options. On the finish I will even recommend a brief record of supplemental assets in order that the readers can discover extra particulars of the subjects lined within the submit.
Now, let’s begin.
With a purpose to perceive the options of XGBoost, we will begin with a fast overview of its family tree.
From a top-down perspective, XGBoost is a sub-class of Supervised Machine Studying. And, as its title suggests, XGBoost is a complicated variant of Boosting Machine, which is a sub-class of Tree-based Ensemble algorithm, like Random Forest.
However, Boosting Machine is essentially totally different from Random Forest in the best way the way it operates its studying processes.
Boosting Machine
Random Forest runs a number of impartial determination bushes in parallel and combines their outcomes by averaging all the outcomes. This strategy makes use of random bootstrapping sampling and is commonly referred to as bagging. On this sense, Random Forest is a parallel studying algorithm.
Quite the opposite, Boosting Machine makes use of an additive technique: that’s to “add one new tree at a time” (xgboost developpers, 2022). Boosting Machine runs particular person weak/easy determination bushes referred to as the bottom learner in sequence. Merely put, conceptually Boosting Machine is constructed on a sequential studying structure.
On this sense, Boosting Machine learns in sequence, whereas Random Forest does in parallel.
As a reference on Boosting Machine, here’s a MIT lecture on Boosting: https://www.youtube.com/watch?v=UHBmv7qCey4
That stated, to keep away from confusion I ought to make a footnote right here from the attitude of system optimization. XGBoost can be designed to function parallel computation to reinforce an environment friendly use of computational assets(xgboost builders, n.d.). General, XGBoost, whereas inheriting a sequential studying structure from Boosting Machine, operates parallel computations for System Optimization.
Gradient Boosting Machine
As its title suggests, XGBoost (eXtreme Gradient Increase) is a complicated variant of Gradient Boosting Machine (GBM), a member of the family of Boosting Machine.
As part of its additive technique, Gradient Boosting Machine (GBM) makes use of Gradient Descent for optimization. With a purpose to scale back the computational burden, GBM approximates the Goal Perform through the use of the primary order time period of the Taylor growth and ignores any greater order phrases for its studying optimization. In different phrases, it makes use of the primary spinoff (Gradient) of the Goal Perform (Loss Perform) to find out the subsequent weak learner predictor. On this method, Gradient Boosting, whereas retaining the prevailing weak predictors, provides a brand new predictor on high of them to cut back the present error so as to incrementally enhance the efficiency.(Friedman, 2000)
Newton Boosting Machine
XGBoost extends the thought of Gradient Boosting within the sense that it additionally makes use of the second spinoff (Hessian: Curvature) of the Goal Perform along with its first spinoff (Gradient) to additional optimize its studying course of. The tactic known as the Newton Raphson Technique. And Boosting Machine utilizing the Newton Raphson Technique known as Newton Boosting. For additional discussions on the distinction between the Gradient Descent and the Newton Boosting, you’ll be able to learn a paper, Gradient and Newton Boosting for Classification and Regression, by Fabio Sigrist.
Due to the particular structure of the additive technique, the second order approximation yields a number of useful mathematical properties to streamline the algorithm for additional computational effectivity. (Guestrin & Chen, 2016)
Regularization: to deal with Variance-Bias Commerce-off
Jerome Friedman, the architect of Gradient Boosting Machine (Friedman, 2000), articulated the significance of regularization to deal with bias-variance trade-off, the issue of underfitting-overfitting trade-off, particularly recommending the customers to tune three meta-parameters of Gradient Boosting Machine: the variety of iterations, the educational fee, and the variety of terminal nodes/leaves. (Friedman, 2000, pp. 1203, 1214–1215)
On this context, XGBoost inherited the regularization focus of Gradient Boosting Machine and prolonged it additional.
- First, XGBoost permits the customers to tune the assorted hyperparameters to constrain the bushes: e.g. the variety of bushes, the depth of a person tree, the minimal sum of occasion weights for partition, the utmost variety of boosting rounds, and the variety of the nodes/leaves.
- Second, it permits the customers to use a studying fee, shrinkage, in the course of the studying course of. (Guestrin & Chen, 2016, p. 3)
- Third, it permits the customers to make use of random sampling methods reminiscent of column sub-sampling. (Guestrin & Chen, 2016, p. 3)
- Fourth, it permits the customers to tune L1 and L2 regularization phrases.
Sparsity-aware Algorithm and Weighted Quantile Sketch
Extra importantly, XGBoost launched two improvements: Sparsity-aware Algorithm and Weighted Quantile Sketch. (Chen & Guestrin, 2016, p10)
First, XGBoost has a built-in function referred to as default path. This function captures the sample of the sparse knowledge construction and determines the path of the cut up at every node primarily based on the sample. Guestrin & Chen current three typical causes for sparsity:
“1) presence of lacking values within the knowledge; 2) frequent zero entries within the statistics; and, 3) artifacts of function engineering reminiscent of one-hot encoding.” (Guestrin & Chen, 2016)
In precept, this function makes XGBoost sparsity-aware algorithm that may deal with lacking knowledge: the person doesn’t have to impute lacking knowledge.
Whereas default path determines the path of the cut up, weighted quantile sketch proposes candidate cut up factors. The next excerpt from Chen and Guestrin’s paper summarizes what it’s.
“a novel distributed weighted quantile sketch algorithm … can deal with weighted knowledge with a provable theoretical assure. The final thought is to suggest a knowledge construction that helps merge and prune operations, with every operation confirmed to keep up a sure accuracy stage.” (Guestrin & Chen, 2016)
System Optimization: Effectivity and Scalability
Up to now, we noticed the framework of XGBoost from the attitude of the educational algorithm structure. Now, we will view it from the attitude of System Optimization.
The native XGBoost API can be modern in pursuing the computational effectivity, or the system optimization. The API known as eXtreme (X) since XGBoost goals at enabling the customers to use an eXtreme restrict of the given system’s computational capability, by effectively allocating computation duties among the many given computational assets — processors (CPU, GPU), reminiscence, and out-of-core (disk area): cache entry, block knowledge compression and sharding. (databricks, 2017)
On extra in regards to the modern features of the native XGBoost API, right here is a superb piece outlined by the inventors of XGBoost (Chen & Guestrin) , XGBoost: A Scalable Tree Boosting System.
This fast overview of XGBoost went over its family tree, its architectural options, and its innovation with out moving into particulars.
In a nutshell, XGBoost has a sequential-parallel hybrid structure in a way that it inherits its sequential studying structure from its Boosting Machine family tree, on the identical time, incorporates parallel computation into its structure so as to improve the system effectivity.
Since Boosting Machine tends of overfitting, the native XGBoost API has an intense deal with addressing bias-variance trade-off and facilitates the customers to use a wide range of regularization methods by means of hyperparameter tuning.
If you’re focused on an implementation instance of the native XGBoost API, you’ll be able to learn my one other submit, Pair-Clever Hyperparameter Tuning with the Native XGBoost API.
Thanks for studying this submit.
Recommended Exterior Sources
For individuals who need to discover extra particulars of XGBoost, here’s a brief record of my favourite assets in regards to the algorithm:

{kind=link}