
The case in opposition to utilizing Pandas for one sizzling encoding

The Pandas library is well-known for its utility in machine studying initiatives.
Nonetheless, there are some instruments in Pandas that simply aren’t perfect for coaching fashions. Among the finest examples of such a instrument is the get_dummies perform, which is used for one sizzling encoding.
Right here, we offer a fast rundown of the one sizzling encoding function in Pandas and clarify why it isn’t suited to machine studying duties.
One Scorching Encoding With Pandas
Let’s begin with a fast refresher on learn how to one sizzling encode variables with Pandas.
Suppose we’re working with the next information:

We will create dummy variables from this dataset by figuring out the explicit options after which reworking them utilizing the get_dummies perform.
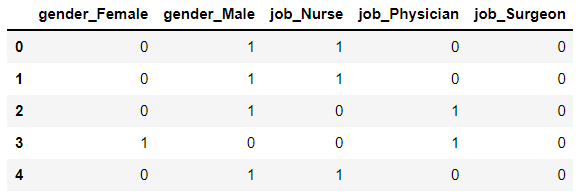
We will then substitute the present categorical options within the dataset with the dummy variables.

All in all, the get_dummies perform allows customers to encode their options with minimal code, befitting a Pandas instrument.
Shortcomings of pandas.get_dummies
The get_dummies perform is a fast and straightforward solution to encode variables, which can be utilized for any subsequent evaluation. Nonetheless, utilizing this technique of encoding for machine studying functions is a mistake for two causes.
- The get_dummies perform doesn’t account for unseen information
Any machine studying mannequin should account for unseen information. Subsequently, the dummy variables generated with the testing information should match the dummy variables generated with the coaching information.
With this in thoughts, it’s straightforward to see how utilizing Pandas for one sizzling encoding could cause issues.
The Pandas library’s get_dummies technique encodes options primarily based on the current values. Nonetheless, there’s all the time an opportunity that the variety of distinctive values within the testing information does not match the variety of distinctive values in coaching information.
Within the dataset from the earlier instance, the job function consists of three distinctive values: “Physician”, “Nurse”, and “Surgeon”. Performing one sizzling encoding on this column yields 3 dummy variables.
Nonetheless, what would occur if the check information’s job function had extra distinctive values than that of the coaching set? Such information would yield dummy variables that wouldn’t match the info used to coach the mannequin.
As an instance this, let’s practice a linear regression mannequin with this information with earnings because the goal label.
Suppose that we want to consider this mannequin with a check dataset. To take action, we have to one sizzling encode the brand new dataset as effectively. Nonetheless, this dataset’s job function has 4 distinctive values: ‘Physician’, ‘Nurse’, ‘Surgeon’, and ‘Pharmacist’.
Because of this, after performing one sizzling encoding on the testing set, the variety of enter options within the coaching set and testing set don’t match.

The one sizzling encoded check dataset has 8 enter options.
Sadly, the linear regression mannequin, which was skilled with information comprising 7 enter options, will be unable to make predictions utilizing information with totally different dimensionality.
To showcase this, let’s attempt utilizing the predict technique on the testing set to generate predictions.

As anticipated, the mannequin is unable to make predictions with this testing information.
2. The get_dummies technique will not be suitable with different machine studying instruments.
Information preprocessing typically entails executing a collection of operations.
Sadly, the Pandas library’s one sizzling encoding technique is troublesome to make use of at the side of operations like standardization and precept element evaluation in a seamless method.
Whereas the get_dummies perform can actually be integrated into preprocessing procedures, it might require an strategy that’s suboptimal by way of code readability and effectivity.
The Superior Various
Fortuitously, there are superior strategies for encoding categorical variables that tackle the aforementioned points.
The preferred of those strategies can be the Scikit Study’s OneHotEncoder, which is way more suited to machine studying duties.
Let’s reveal the OneHotEncoder utilizing the present dataset.
First, we create a OneHotEncoder object, with ‘ignore’ assigned to the handle_unknown parameter. This ensures that the skilled mannequin will be capable of cope with unseen information.
Subsequent, we create a Pipeline object that shops the OneHotEncoder object.
After that, we create a ColumnTransformer object, which we will use to specify the options that must be encoded.
A ColumnTransformer object is required as a result of with out it, each column will likely be encoded, together with the numeric options. When utilizing this object, it’s essential to assign the ‘passthrough’ worth to the the rest parameter. This ensures that the columns not specified within the transformer usually are not dropped.
With this new column transformer object, we will now encode the coaching dataset with the fit_transform technique.
Lastly, we will encode the testing information with the rework technique.
This time, there must be no bother with producing predictions because the coaching set and testing set have the identical variety of enter options.

Why The OneHotEncoder Works
There are quite a few the reason why the Scikit Study’s OneHotEncoder is superior to the Pandas library’s get_dummies technique in a machine studying context.
Firstly, it allows customers to coach fashions with out worrying concerning the distinction in distinctive values in categorical options between the coaching and testing units.
Secondly, due to the opposite instruments supplied by the Scikit Study library, customers can now streamline different operations extra successfully.
For the reason that standard courses just like the StandardScaler and the PCA are from the identical Scikit Study package deal, it’s a lot simpler to make use of them cohesively and course of datasets effectively. Regardless of the quite a few operations required for a given job, customers will discover it straightforward to carry out them with readable code.
The one disadvantage with utilizing the OneHotEncoder is that it comes with a barely steep studying curve. Customers that want to be taught to make use of this Scikit Study instrument may also should turn out to be accustomed to different Scikit Study instruments such because the Pipeline and the ColumnTransformer.
Conclusion
Utilizing Pandas to encode options for machine studying duties was one in all my greatest blunders once I began coaching fashions, so I believed it was price highlighting this problem to spare others from making the identical mistake.
Even should you’ve been getting away with utilizing Pandas for one sizzling encoding, I strongly encourage you to modify to the Scikit Study library’s OneHotEncoder in your future initiatives.
I want you the perfect of luck in your information science endeavors!

{kind=link}