Two examples of the weak factors of SHAP values and an summary of doable options
SHAP values appear to take away the trade-off between the complexity of machine studying fashions and the problem of interpretation, encouraging researchers and knowledge scientists to design algorithms with out worrying about tips on how to perceive the prediction given by any black field. However is it at all times case that SHAP can clarify every little thing property?
On this publish, we wish to focus on one vital weak level of SHAP values by illustrating some examples. An summary of doable options can be shortly offered as effectively.
SHAP values, based mostly on cooperative recreation idea, quantify the interactions between options that result in a prediction by pretty distributing the “payout” among the many options.
Nonetheless, Frye et al. [1] argue that SHAP values undergo from a big limitation as their ignorance of all causal buildings within the knowledge. Extra exactly, such a framework locations all options on equal footing within the mannequin rationalization, by requiring attributions to be equally distributed over identically informative options.
For instance, take into account a mannequin taking the seniority and the wage as enter and predicting if the particular person can get a mortgage from his financial institution. A picture that the SHAP values inform that each his seniority and wage have massive SHAP values, contributing to his success in software. Nonetheless, his wage outcomes primarily from his seniority and there’s no cause to assign an enormous SHAP worth to his wage with the presence of his seniority on this case.
The absence of the causal construction within the framework of SHAP values may be critical, resulting in false selections in some use circumstances by contemplating bettering a function with massive SHAP values whereas such values may solely be the impact of different options. Again to the instance of the mortgage, picture SHAP tells an individual that you simply fail to get a mortgage due to your low wage and he tempts you to alter a job with a better wage. Nonetheless, the appliance may nonetheless be rejected as a result of a brand new job would result in smaller seniority.
We would supply some extra detailed examples within the coming sections.
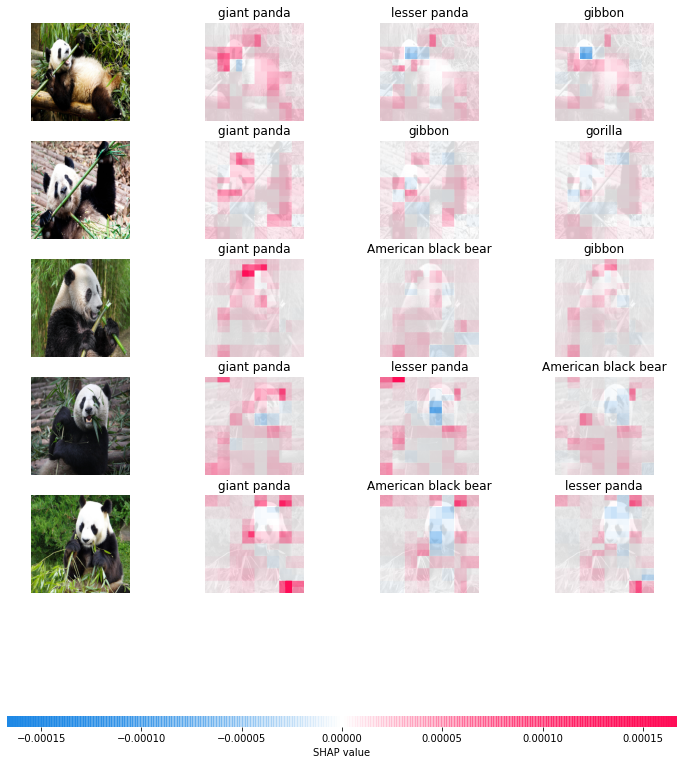
This part considers an instance of a pre-trained deep studying mannequin for picture classifications, Inception V1 with 1001 class labels together with the large panda, tree frog, and many others. obtainable on the TensorFlow hub. Detailed implementation is offered within the pocket book.
The next experiment considers the next set containing 5 photographs of big pandas, every preprocessed as an array with the scale of (500,500,3) starting from 0 to 255 and we want the compute SHAP values of the primary third probably courses of the photographs given by the Inception V1 mannequin to know which pixels contribute extra to the ultimate classification outcomes.

For such a function, we write the next strains of code:
The primary two strains do nothing however rescale the picture array to adapt the mannequin’s enter. We use a masker with the identical measurement because the enter picture because the background for SHAP values calculation. The image_plot operate provides a visible illustration of the outcomes:
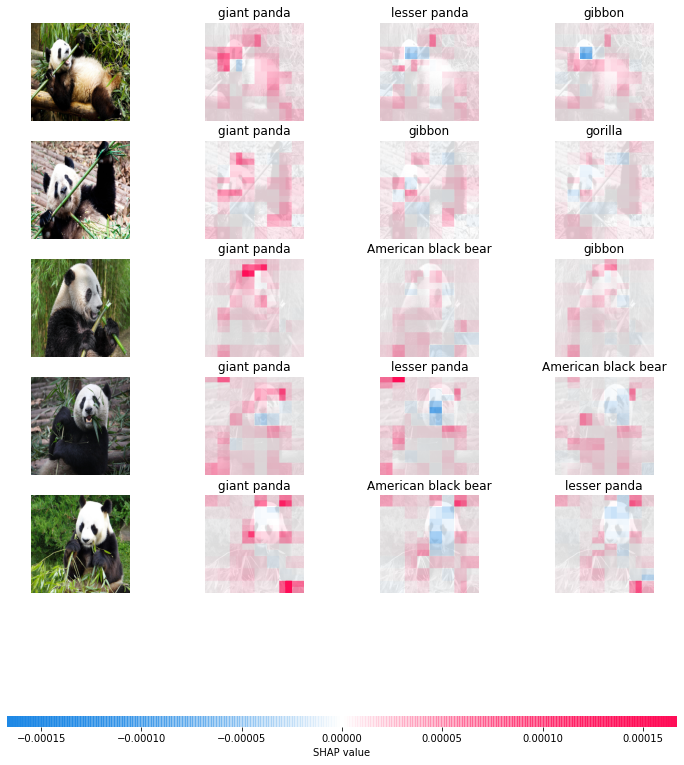
Taking a deeper take a look at the outcomes, particularly the 2 final photographs, we observed without delay that there are pixels out of the panda our bodies with massive SHAP values, i.e. the place we marked a circle:

Such attribution might need a direct rationalization: noticing that these pixels kind bamboos that are the favourite of pandas and we argue that their frequent existence brings such biased significance. If we all know that the existence of pandas is the causal ancestor of that of bamboos, it in fact makes extra sense to attribute the bamboos’ significance to the panda our bodies whereas SHAP values are sadly unable to seize such vital info by assuming that each one function are unbiased.
The excellent news is that researchers have already observed the absence of such causal construction within the present framework of SHAP values. We give right here two strategies: uneven SHAP values [1] and informal SHAP values[2].
The uneven SHAP values (ASVs) primarily take away the symmetry property of the present SHAP values framework, i.e. the contributions of two function values must be the identical in the event that they contribute equally to all doable coalitions. Within the distinction, weights incorporating the causality of the options as chance measures are launched when summing all of the “payoffs”s collectively. Such a design emphasizes extra explanations when it comes to root causes, relatively than explanations of rapid causes.
Then again, Heskes et al. [2] level out that there’s “no have to resort to uneven Shapley values to include causal data” and proposes a causal SHAP values (CSVs) framework. The definition has nothing extra however the incorporation of the intervention expectation by a do-calculus of Pearl’s [3]. Such a design certainly decomposes the significance of 1 function into two elements: direct and oblique and would result in higher decision-making by making an allowance for these two various kinds of results on the ultimate prediction.
I invite the reader to comply with my future posts for extra detailed explanations and implementations of concrete examples of the CSVs.
[1] C. Frye, C. Rowat, and I. Feige, “Uneven shapley values: incorporating causal data into model-agnostic explainability,” in Advances in Neural Data Processing Techniques 33: Annual Convention on Neural Data Processing Techniques 2020, NeurIPS 2020, December 6–12, 2020, digital, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., 2020.
[2] D. Janzing, L. Minorics, and P. Blöbaum, “Characteristic relevance quantification in explainable AI: A causal drawback,” in The twenty third Worldwide Convention on Synthetic Intelligence and Statistics, AISTATS 2020, 26–28 August 2020, On-line [Palermo, Sicily, Italy], ser. Proceedings of Machine Studying Analysis, S. Chiappa and R. Calandra, Eds., vol. 108.
[3] The Do-Calculus Revisited Judea Pearl Keynote Lecture, August 17, 2012 UAI-2012 Convention, Catalina, CA. https://ftp.cs.ucla.edu/pub/stat_ser/r402.pdf

{kind=link}