
Trie information construction is outlined as a Tree primarily based information construction that’s used for storing some assortment of strings and performing environment friendly search operations on them. The phrase Trie is derived from reTRIEval, which implies discovering one thing or acquiring it.
Trie follows some property that If two strings have a typical prefix then they may have the identical ancestor within the trie. A trie can be utilized to type a group of strings alphabetically in addition to search whether or not a string with a given prefix is current within the trie or not.

Trie Information Construction
Want for Trie Information Construction?
A Trie information construction is used for storing and retrieval of information and the identical operations could possibly be completed utilizing one other information construction which is Hash Desk however Trie can carry out these operations extra effectively than a Hash Desk. Furthermore, Trie has its personal benefit over the Hash desk. A Trie information construction can be utilized for prefix-based looking whereas a Hash desk can’t be utilized in the identical means.
Benefits of Trie Information Construction over a Hash Desk:
The A trie information construction has the next benefits over a hash desk:
- We are able to effectively do prefix search (or auto-complete) with Trie.
- We are able to simply print all phrases in alphabetical order which isn’t simply attainable with hashing.
- There isn’t any overhead of Hash capabilities in a Trie information construction.
- Looking for a String even within the massive assortment of strings in a Trie information construction will be completed in O(L) Time complexity, The place L is the variety of phrases within the question string. This looking time could possibly be even lower than O(L) if the question string doesn’t exist within the trie.
Properties of a Trie Information Construction
Now we already know that Trie has a tree-like construction. So, it is vitally essential to know its properties.
Under are some essential properties of the Trie information construction:
- There’s one root node in every Trie.
- Every node of a Trie represents a string and every edge represents a personality.
- Each node consists of hashmaps or an array of pointers, with every index representing a personality and a flag to point if any string ends on the present node.
- Trie information construction can include any variety of characters together with alphabets, numbers, and particular characters. However for this text, we are going to focus on strings with characters a-z. Subsequently, solely 26 pointers want for each node, the place the 0th index represents ‘a’ and the twenty fifth index represents ‘z’ characters.
- Every path from the basis to any node represents a phrase or string.
Under is an easy instance of Trie information construction.
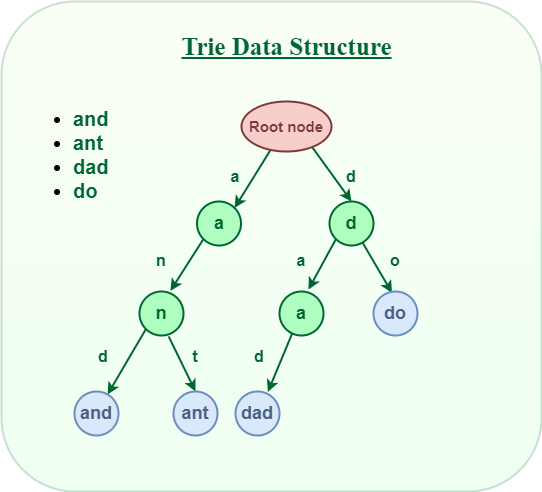
Trie Information Construction
How does Trie Information Construction work?
We already know that the Trie information construction can include any variety of characters together with alphabets, numbers, and particular characters. However for this text, we are going to focus on strings with characters a-z. Subsequently, solely 26 pointers want for each node, the place the 0th index represents ‘a’ and the twenty fifth index represents ‘z’ characters.
Any lowercase English phrase can begin with a-z, then the following letter of the phrase could possibly be a-z, the third letter of the phrase once more could possibly be a-z, and so forth. So for storing a phrase, we have to take an array (container) of measurement 26 and initially, all of the characters are empty as there are not any phrases and it’ll look as proven under.
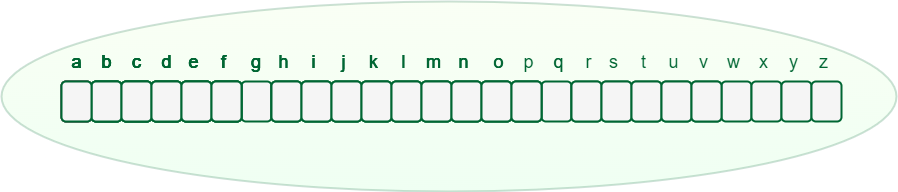
An array of pointers inside each Trie node
Let’s see how a phrase “and” and “ant” is saved within the Trie information construction:
- Retailer “and” in Trie information construction:
- The phrase “and” begins with “a“, So we are going to mark the place “a” as crammed within the Trie node, which represents using “a”.
- After inserting the primary character, for the second character once more there are 26 potentialities, So from “a“, once more there’s an array of measurement 26, for storing the 2nd character.
- The second character is “n“, So from “a“, we are going to transfer to “n” and mark “n” within the 2nd array as used.
- After “n“, the third character is “d“, So mark the place “d” as used within the respective array.
- Retailer “any” within the Trie information construction:
- The phrase “any” begins with “a” and the place of “a” within the root node has already been crammed. So, no must fill it once more, simply transfer to the node ‘a‘ in Trie.
- For the second character ‘n‘ we are able to observe that the place of ‘n’ within the ‘a’ node has already been crammed. So, no must fill it once more, simply transfer to node ‘n’ in Trie.
- For the final character ‘t‘ of the phrase, The place for ‘t‘ within the ‘n‘ node will not be crammed. So, crammed the place of ‘t‘ in ‘n‘ node and transfer to ‘t‘ node.
After storing the phrase “and” and “any” the Trie will appear to be this:
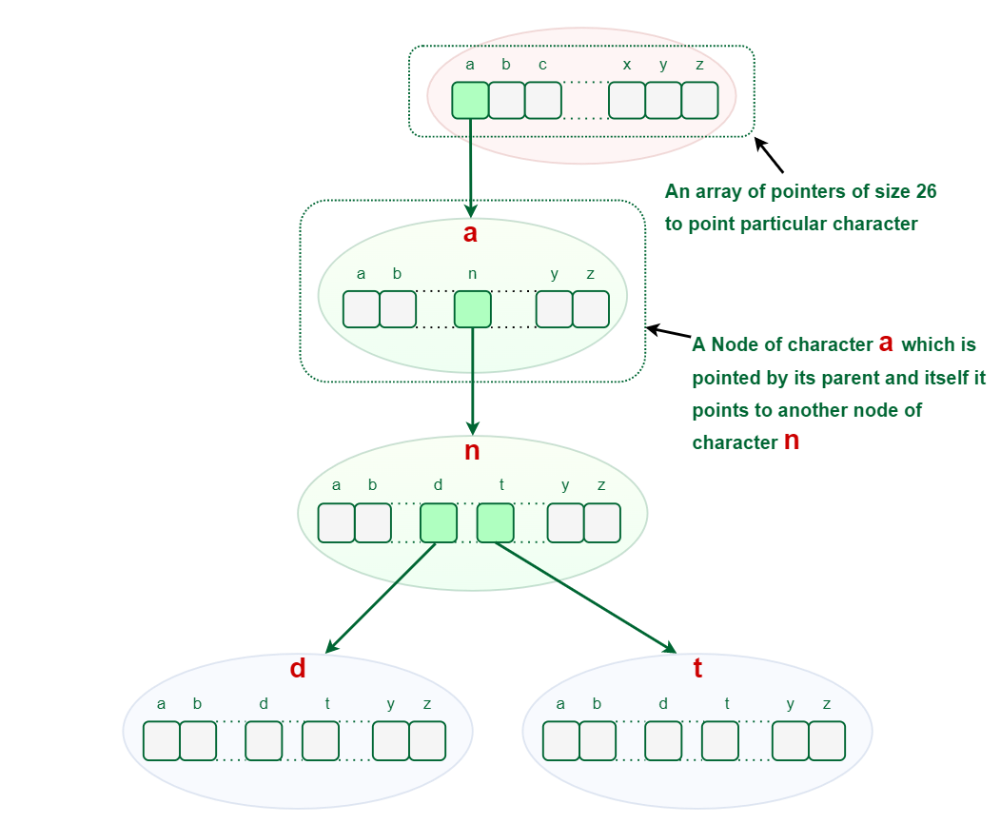
Illustration of Trie Node:
Each Trie node consists of a personality pointer array or hashmap and a flag to symbolize if the phrase is ending at that node or not. But when the phrases include solely lower-case letters (i.e. a-z), then we are able to outline Trie Node with an array as an alternative of a hashmap.
C++
|
|
Java
|
|
Primary Operations on Trie Information Construction:
- Insertion
- Search
- Deletion
1. Insertion in Trie Information Construction:
This operation is used to insert new strings into the Trie information construction. Allow us to see how this works:
Allow us to attempt to Insert “and” & “ant” on this Trie:
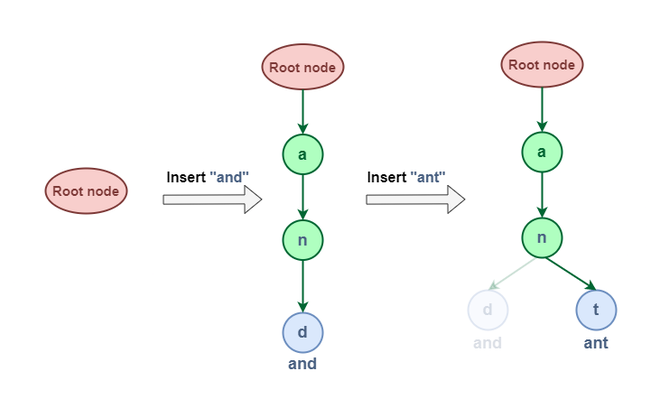
Insert “and” & “ant”
From the above illustration of insertion, we are able to see that the phrase “and” & “ant” have shared some widespread node (i.e “an”) that is due to the property of the Trie information construction that If two strings have a typical prefix then they may have the identical ancestor within the trie.
Now allow us to attempt to Insert “dad” & “do”:
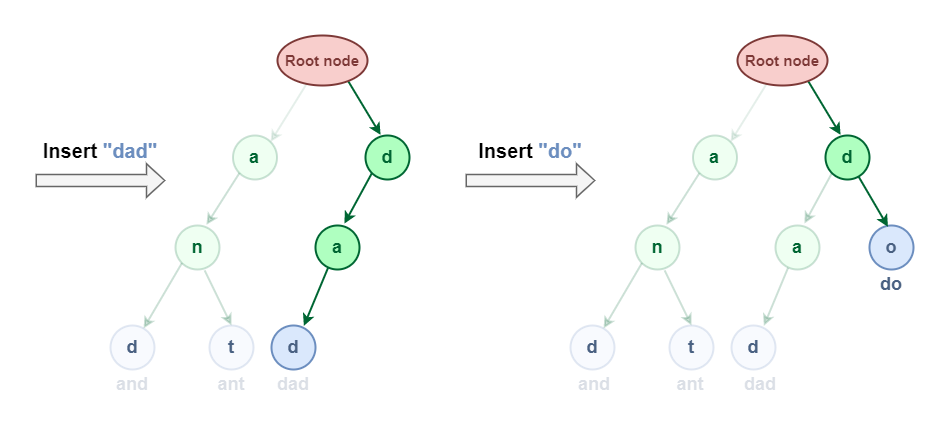
Insertion in Trie Information Construction
Implementation of Insertion in Trie information construction:
Algorithm:
- Outline a perform insert(TrieNode *root, string &phrase) which can take two parameters one for the basis and the opposite for the string that we need to insert within the Trie information construction.
- Now take one other pointer currentNode and initialize it with the root node.
- Iterate over the size of the given string and verify if the worth is NULL or not within the array of pointers on the present character of the string.
- If It’s NULL then, make a brand new node and level the present character to this newly created node.
- Transfer the curr to the newly created node.
- Lastly, increment the wordCount of the final currentNode, this means that there’s a string ending currentNode.
Under is the implementation of the above algorithm:
C++
|
|
Java
|
|
2. Looking out in Trie Information Construction:
Search operation in Trie is carried out in the same means because the insertion operation however the one distinction is that every time we discover that the array of pointers in curr node doesn’t level to the present character of the phrase then return false as an alternative of making a brand new node for that present character of the phrase.
This operation is used to go looking whether or not a string is current within the Trie information construction or not. There are two search approaches within the Trie information construction.
- Discover whether or not the given phrase exists in Trie.
- Discover whether or not any phrase that begins with the given prefix exists in Trie.
There’s a comparable search sample in each approaches. Step one in looking a given phrase in Trie is to transform the phrase to characters after which evaluate each character with the trie node from the basis node. If the present character is current within the node, transfer ahead to its kids. Repeat this course of till all characters are discovered.
2.1 Looking out Prefix in Trie Information Construction:
Seek for the prefix “an” within the Trie Information Construction.
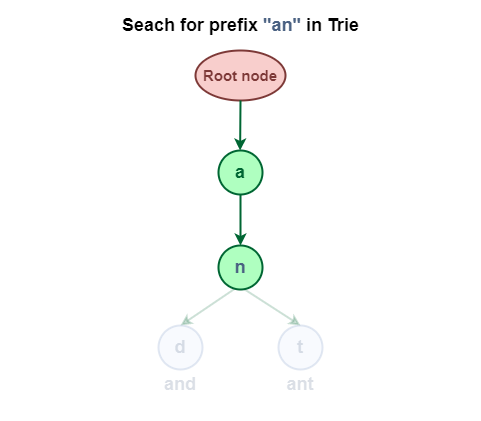
Seek for the prefix “an” in Trie
Implementation of Prefix Search in Trie information construction:
C++
|
|
2.2 Looking out Full phrase in Trie Information Construction:
It’s much like prefix search however moreover, we’ve got to verify if the phrase is ending on the final character of the phrase or not.
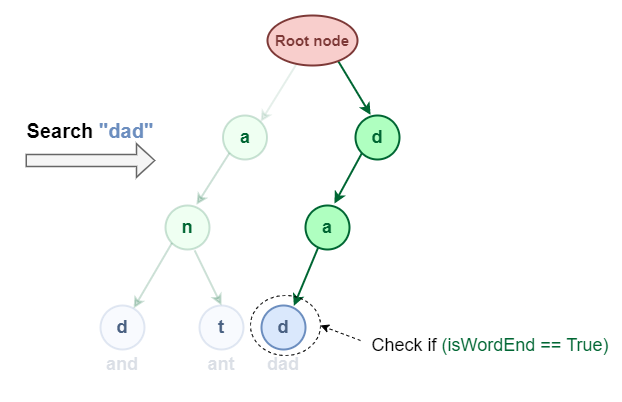
Search “dad” within the Trie information construction
Implementation of Search in Trie information construction:
C++
|
|
Java
|
|
3. Deletion in Trie Information Construction
This operation is used to delete strings from the Trie information construction. There are three instances when deleting a phrase from Trie.
- The deleted phrase is a prefix of different phrases in Trie.
- The deleted phrase shares a typical prefix with different phrases in Trie.
- The deleted phrase doesn’t share any widespread prefix with different phrases in Trie.
3.1 The deleted phrase is a prefix of different phrases in Trie.
As proven within the following determine, the deleted phrase “an” share an entire prefix with one other phrase “and” and “ant“.
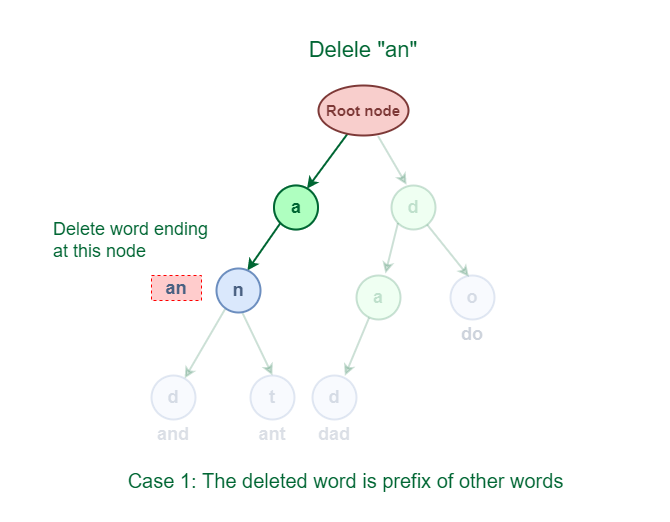
Deletion of phrase which is a prefix of different phrases in Trie
A simple resolution to carry out a delete operation for this case is to only decrement the wordCount by 1 on the ending node of the phrase.
3.2 The deleted phrase shares a typical prefix with different phrases in Trie.
As proven within the following determine, the deleted phrase “and” has some widespread prefixes with different phrases ‘ant’. They share the prefix ‘an’.
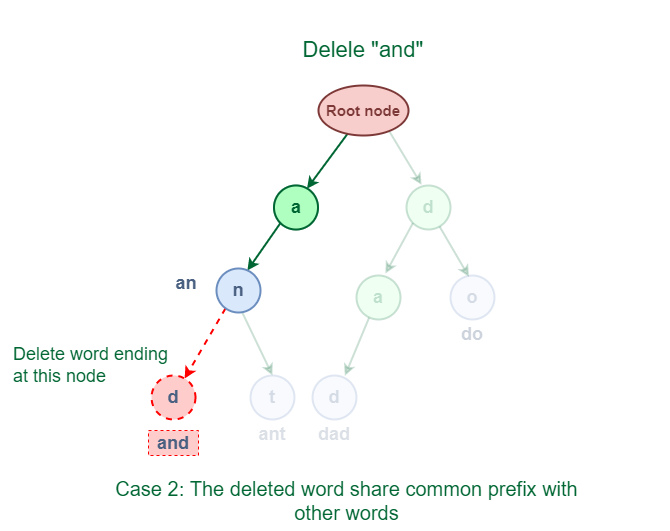
Deletion of phrase which shares a typical prefix with different phrases in Trie
The answer for this case is to delete all of the nodes ranging from the top of the prefix to the final character of the given phrase.
3.3 The deleted phrase doesn’t share any widespread prefix with different phrases in Trie.
As proven within the following determine, the phrase “geek” doesn’t share any widespread prefix with every other phrases.
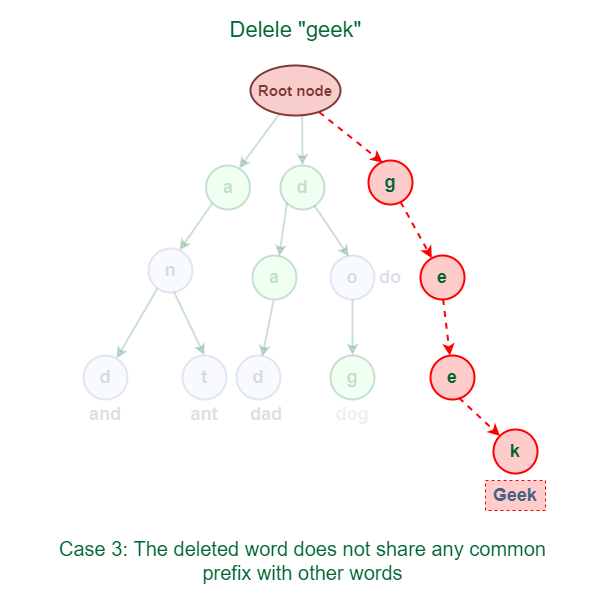
Deletion of a phrase that doesn’t share any widespread prefix with different phrases in Trie
The answer for this case is simply to delete all of the nodes.
Under is the implementation that handles all of the above instances:
C++
|
|
The way to implement Trie Information Construction?
- Create a root node with the assistance of TrieNode() constructor.
- Retailer a group of strings that we’ve got to insert within the trie in a vector of strings say, arr.
- Inserting all strings in Trie with the assistance of the insertkey() perform,
- Search strings from searchQueryStrings with the assistance of search_key() perform.
- Delete the strings current within the deleteQueryStrings with the assistance of delete_key.
C++
|
|
Question String : do The question string is current within the Trie Question String : geek The question string is current within the Trie Question String : bat The question string will not be current within the Trie Question String : geek The question string is efficiently deleted Question String : tea The question string will not be current within the Trie
Complexity Evaluation of Trie Information Construction
| Operation | Time Complexity | Auxiliary Area |
|---|---|---|
| Insertion | O(n) | O(n*m) |
| Looking out | O(n) | O(1) |
| Deletion | O(n) | O(1) |
Word: Within the above complexity desk ‘n’, ‘m’ represents the dimensions of the string and the variety of strings which might be saved within the trie.
1. Autocomplete Characteristic: Autocomplete supplies recommendations primarily based on what you kind within the search field. Trie information construction is used to implement autocomplete performance.
Autocomplete characteristic of Trie Information Construction
2. Spell Checkers: If the phrase typed doesn’t seem within the dictionary, then it exhibits recommendations primarily based on what you typed.
It’s a 3-step course of that features :
- Checking for the phrase within the information dictionary.
- Producing potential recommendations.
- Sorting the recommendations with increased precedence on high.
Trie shops the info dictionary and makes it simpler to construct an algorithm for looking the phrase from the dictionary and supplies the checklist of legitimate phrases for the suggestion.
3. Longest Prefix Matching Algorithm(Most Prefix Size Match): This algorithm is utilized in networking by the routing units in IP networking. Optimization of community routes requires contiguous masking that certain the complexity of lookup a time to O(n), the place n is the size of the URL deal with in bits.
To hurry up the lookup course of, A number of Bit trie schemes had been developed that carry out the lookups of a number of bits quicker.
- Trie permits us to enter and finds strings in O(l) time, the place l is the size of a single phrase. It’s quicker as in comparison with each hash tables and binary search bushes.
- It supplies alphabetical filtering of entries by the important thing of the node and therefore makes it simpler to print all phrases in alphabetical order.
- Trie takes much less house when in comparison with BST as a result of the keys are usually not explicitly saved as an alternative every key requires simply an amortized fastened quantity of house to be saved.
- Prefix search/Longest prefix matching will be effectively completed with the assistance of trie information construction.
- Since trie doesn’t want any hash perform for its implementation so they’re typically quicker than hash tables for small keys like integers and pointers.
- Tries help ordered iteration whereas iteration in a hash desk will end in pseudorandom order given by the hash perform which is often extra cumbersome.
- Deletion can be a simple algorithm with O(l) as its time complexity, the place l is the size of the phrase to be deleted.
Disadvantages of Trie information construction:
- The primary drawback of the trie is that it takes plenty of reminiscence to retailer all of the strings. For every node, we’ve got too many node pointers that are equal to the no of characters within the worst case.
- An effectively constructed hash desk(i.e. hash perform and an inexpensive load issue) has O(1) as lookup time which is means quicker than O(l) within the case of a trie, the place l is the size of the string.
High Interview issues on Trie information construction:
Often requested questions (FAQs) about Trie Information Construction:
1. Is trie a complicated information construction?
A Trie is a complicated information construction that’s generally also referred to as a prefix tree
2. What’s the distinction between trie and tree information construction?
A tree is a common construction of recursive nodes. There are lots of forms of bushes. Standard ones are the binary tree and balanced tree. A Trie is a type of tree, recognized by many names together with prefix tree, digital search tree, and retrieval tree (therefore the title ‘trie’).
3. What are some functions of Trie?
The longest widespread prefix, sample looking, autocomplete and implementation of the dictionary are among the widespread functions of a Trie Information Construction.
4. Does Google use trie?
Google even shops every phrase/sentence within the type of a trie.
5. What’s the benefit of trie?
The primary drawback of Trie is that it takes plenty of reminiscence to retailer all of the Strings. For every node, we’ve got too many node pointers (equal to the variety of characters of the alphabet).
Conclusion:
Our dialogue thus far has led us to the conclusion that the Trie information construction is a Tree primarily based information construction that’s used for storing some assortment of strings and performing environment friendly search operations on them and we’ve got additionally mentioned the varied benefit and functions of trie information construction.
Associated articles:

{kind=link}