
Among the many improvements that energy the favored open supply TensorFlow machine studying platform are computerized differentiation (Autograd) and the XLA (Accelerated Linear Algebra) optimizing compiler for deep studying.
Google JAX is one other venture that brings collectively these two applied sciences, and it affords appreciable advantages for pace and efficiency. When run on GPUs or TPUs, JAX can substitute different packages that decision NumPy, however its packages run a lot sooner. Moreover, utilizing JAX for neural networks could make including new performance a lot simpler than increasing a bigger framework like TensorFlow.
This text introduces Google JAX, together with an summary of its advantages and limitations, set up directions, and a primary take a look at the Google JAX quickstart on Colab.
What’s Autograd?
Autograd is an computerized differentiation engine that started off as a analysis venture in Ryan Adams’ Harvard Clever Probabilistic Techniques Group. As of this writing, the engine is being maintained however not actively developed. As a substitute, its builders are engaged on Google JAX, which mixes Autograd with further options akin to XLA JIT compilation. The Autograd engine can robotically differentiate native Python and NumPy code. Its main supposed utility is gradient-based optimization.
TensorFlow’s tf.GradientTape API is predicated on comparable concepts to Autograd, however its implementation will not be equivalent. Autograd is written completely in Python and computes the gradient straight from the perform, whereas TensorFlow’s gradient tape performance is written in C++ with a skinny Python wrapper. TensorFlow makes use of back-propagation to compute variations in loss, estimate the gradient of the loss, and predict one of the best subsequent step.
What’s XLA?
XLA is a domain-specific compiler for linear algebra developed by TensorFlow. Based on the TensorFlow documentation, XLA can speed up TensorFlow fashions with probably no supply code adjustments, enhancing pace and reminiscence utilization. One instance is a 2020 Google BERT MLPerf benchmark submission, the place 8 Volta V100 GPUs utilizing XLA achieved a ~7x efficiency enchancment and ~5x batch measurement enchancment.
XLA compiles a TensorFlow graph right into a sequence of computation kernels generated particularly for the given mannequin. As a result of these kernels are distinctive to the mannequin, they’ll exploit model-specific data for optimization. Inside TensorFlow, XLA can be referred to as the JIT (just-in-time) compiler. You may allow it with a flag within the @tf.perform Python decorator, like so:
@tf.perform(jit_compile=True)
You may as well allow XLA in TensorFlow by setting the TF_XLA_FLAGS surroundings variable or by operating the standalone tfcompile software.
Aside from TensorFlow, XLA packages will be generated by:
Get began with Google JAX
I went via the JAX Quickstart on Colab, which makes use of a GPU by default. You may elect to make use of a TPU when you want, however month-to-month free TPU utilization is proscribed. You additionally must run a particular initialization to make use of a Colab TPU for Google JAX.
To get to the quickstart, press the Open in Colab button on the high of the Parallel Analysis in JAX documentation web page. It will swap you to the reside pocket book surroundings. Then, drop down the Join button within the pocket book to connect with a hosted runtime.
Working the quickstart with a GPU made it clear how a lot JAX can speed up matrix and linear algebra operations. Later within the pocket book, I noticed JIT-accelerated occasions measured in microseconds. If you learn the code, a lot of it could jog your reminiscence as expressing widespread features utilized in deep studying.
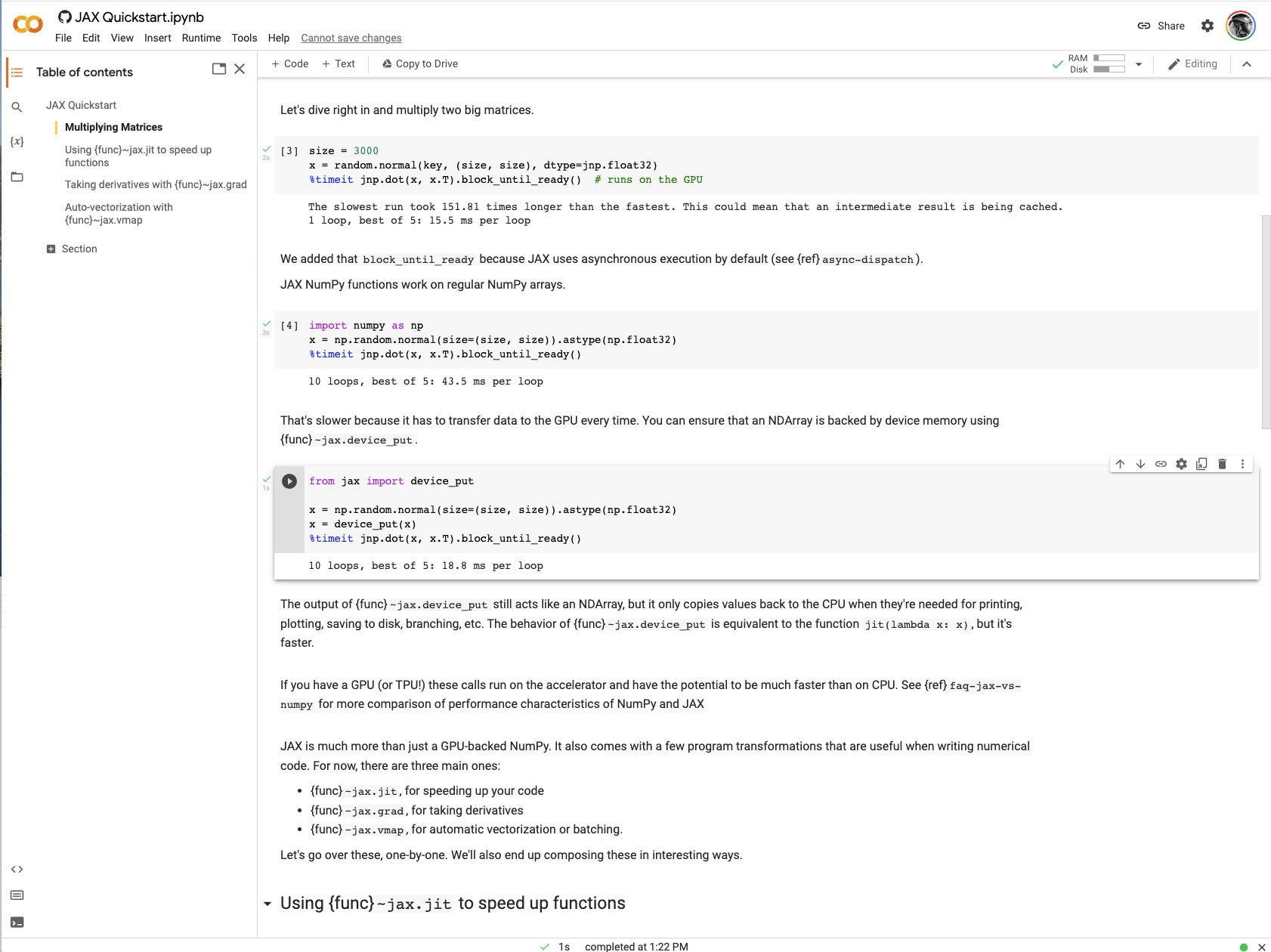 IDG
IDGDetermine 1. A matrix math instance within the Google JAX quickstart.
Find out how to set up JAX
A JAX set up should be matched to your working system and selection of CPU, GPU, or TPU model. It’s easy for CPUs; for instance, if you wish to run JAX in your laptop computer, enter:
pip set up --upgrade pip
pip set up --upgrade "jax[cpu]"
For GPUs, you should have CUDA and CuDNN put in, together with a suitable NVIDIA driver. You may want pretty new variations of each. On Linux with current variations of CUDA and CuDNN, you’ll be able to set up pre-built CUDA-compatible wheels; in any other case, it is advisable construct from supply.
JAX additionally supplies pre-built wheels for Google Cloud TPUs. Cloud TPUs are newer than Colab TPUs and never backward suitable, however Colab environments already embody JAX and the proper TPU help.
The JAX API
There are three layers to the JAX API. On the highest stage, JAX implements a mirror of the NumPy API, jax.numpy. Virtually something that may be finished with numpy will be finished with jax.numpy. The limitation of jax.numpy is that, in contrast to NumPy arrays, JAX arrays are immutable, that means that when created their contents can’t be modified.
The center layer of the JAX API is jax.lax, which is stricter and infrequently extra highly effective than the NumPy layer. All of the operations in jax.numpy are finally expressed by way of features outlined in jax.lax. Whereas jax.numpy will implicitly promote arguments to permit operations between blended information sorts, jax.lax is not going to; as a substitute, it provides express promotion features.
The bottom layer of the API is XLA. All jax.lax operations are Python wrappers for operations in XLA. Each JAX operation is finally expressed by way of these elementary XLA operations, which is what permits JIT compilation.
Limitations of JAX
JAX transformations and compilation are designed to work solely on Python features which might be functionally pure. If a perform has a facet impact, even one thing so simple as a print() assertion, a number of runs via the code may have completely different unwanted side effects. A print() would print various things or nothing in any respect on later runs.
Different limitations of JAX embody disallowing in-place mutations (as a result of arrays are immutable). This limitation is mitigated by permitting out-of-place array updates:
updated_array = jax_array.at[1, :].set(1.0)
As well as, JAX defaults to single precision numbers (float32), whereas NumPy defaults to double precision (float64). If you actually need double precision, you’ll be able to set JAX to jax_enable_x64 mode. On the whole, single-precision calculations run sooner and require much less GPU reminiscence.
Utilizing JAX for accelerated neural networking
At this level, it needs to be clear that you simply may implement accelerated neural networks in JAX. Alternatively, why reinvent the wheel? Google Analysis teams and DeepMind have open-sourced a number of neural community libraries primarily based on JAX: Flax is a totally featured library for neural community coaching with examples and how-to guides. Haiku is for neural community modules, Optax is for gradient processing and optimization, RLax is for RL (reinforcement studying) algorithms, and chex is for dependable code and testing.
Study extra about JAX
Along with the JAX Quickstart, JAX has a collection of tutorials that you could (and will) run on Colab. The primary tutorial exhibits you the way to use the jax.numpy features, the grad and value_and_grad features, and the @jit decorator. The subsequent tutorial goes into extra depth about JIT compilation. By the final tutorial, you’re studying the way to compile and robotically partition features in each single and multi-host environments.
You may (and will) additionally learn via the JAX reference documentation (beginning with the FAQ) and run the superior tutorials (beginning with the Autodiff Cookbook) on Colab. Lastly, you need to learn the API documentation, beginning with the essential JAX bundle.
Copyright © 2022 IDG Communications, Inc.

{kind=link}