
Hello everybody! 
You’ve most likely heard of FastAPI, Strawberry, GraphQL, and the like. Now, we’ll be displaying you the best way to put them collectively in a Subsequent.js app. We will likely be specializing in getting an excellent developer expertise (DX) with typed code. Loads of articles can educate you the best way to use every individually, however there aren’t many assets on the market on placing them collectively, notably with Strawberry.
There are a number of Python-based GraphQL libraries and so they all fluctuate barely from one another. For the longest time, Graphene was a pure alternative because it was the oldest and was utilized in manufacturing at totally different firms, however now different newer libraries have additionally began gaining some traction.
We will likely be specializing in one such library referred to as Strawberry. It’s comparatively new and requires Python 3.7+ as a result of it makes use of Python options that weren’t obtainable in earlier variations of the language. It makes heavy use of dataclasses and is totally typed utilizing mypy.
N .B., you could find the entire code from this text on GitHub.
The ultimate product: A ebook database
We could have a fundamental challenge construction in place that may reveal how one can efficiently begin writing SQLAlchemy + Strawberry + FastAPI functions whereas making use of varieties and robotically producing typed React Hooks to utilize your GraphQL queries and mutations in your Typescript code. The React Hooks will make use of urql, however you’ll be able to simply swap it out for Apollo.
I’ll create the DB schema based mostly on the concept of a bookstore. We are going to retailer details about authors and their books. We is not going to create a full software utilizing React/Subsequent.js however could have all the required items in place to take action if required.
The objective is to have a greater developer expertise by utilizing varieties all over the place and automating as a lot of the code era as potential. It will assist catch much more bugs in growth.
This put up is impressed by this GitHub repo.
Getting began
We first want to put in the next libraries/packages earlier than we are able to begin working:
- Strawberry — That is our GraphQL library that may present GraphQL help on the Python facet
- FastAPI — That is our net framework for serving our Strawberry-based GraphQL API
- Uvicorn — That is an ASGI net server that may serve our FastAPI software in manufacturing
- Aiosqlite — This gives async help for SQLite
- SQLAlchemy — That is our ORM for working with SQLite DB
Let’s create a brand new folder and set up these libraries utilizing pip. As an alternative of making the brand new folder manually, I’ll use the create-next-app command to make it. We are going to deal with the folder created by this command as the foundation folder for our complete challenge. This simply makes the reason simpler. I’ll talk about the required JS/TS libraries in a while. For now, we’ll solely deal with the Python facet.
Ensure you have create-next-app obtainable as a sound command in your system. When you do, run the next command within the terminal:
$ npx [email protected] --typescript strawberry_nextjs
The above command ought to create a strawberry_nextjs folder. Now go into that folder and set up the required Python-based dependencies:
$ cd strawberry_nextjs $ python -m venv virtualenv $ supply virtualenv/bin/activate $ pip set up 'strawberry-graphql[fastapi]' fastapi 'uvicorn[standard]' aiosqlite sqlalchemy
Strawberry + FastAPI: Good day, world!
Let’s begin with a “Good day, world!” instance and it’ll present us the bits and items that make up a Strawberry software. Create a brand new file named app.py and add the next code to it:
import strawberry from fastapi import FastAPI from strawberry.fastapi import GraphQLRouter authors: record[str] = [] @strawberry.kind class Question: @strawberry.subject def all_authors(self) -> record[str]: return authors @strawberry.kind class Mutation: @strawberry.subject def add_author(self, title: str) -> str: authors.append(title) return title schema = strawberry.Schema(question=Question, mutation=Mutation) graphql_app = GraphQLRouter(schema) app = FastAPI() app.include_router(graphql_app, prefix="/graphql")
Let’s have a look at this code in chunks. We begin by importing the required libraries and packages. We create an authors record that acts as our momentary database and holds the writer names (we’ll create an precise database briefly).
We then create the Question class and beautify it with the strawberry.kind decorator. This converts it right into a GraphQL kind. Inside this class, we outline an all_authors resolver that returns all of the authors from the record. A resolver must state its return kind as nicely. We are going to have a look at defining barely advanced varieties within the subsequent part, however for now, a listing of strings would suffice.
Subsequent, we create a brand new Mutation class that incorporates all of the GraphQL mutations. For now, we solely have a easy add_author mutation that takes in a reputation and provides it to the authors record.
Then we cross the question and mutation lessons to strawberry.Schema to create a GraphQL schema after which cross that on to GraphQLRouter. Lastly, we plug within the GraphQLRouter to FastAPI and let GraphQLRouter deal with all incoming requests to /graphql endpoint.
Should you don’t know what these phrases imply, then let me provide you with a fast refresher:
- Queries — A kind of request despatched to the server to retrieve information/information
- Mutations — A kind of request despatched to the server to create/replace/delete information/file
- Varieties — The objects we work together with in GraphQL. These signify the information/information/errors and all the things in between
- Resolver — A perform that populates the information for a single subject in our schema
You possibly can learn extra concerning the schema fundamentals in Strawberry on the official docs web page.
To run this code, hop on over to the terminal and execute the next command:
$ uvicorn app:app --reload --host '::'
This could print one thing like the next as output:
INFO: Will look ahead to adjustments in these directories: [‘/Users/yasoob/Desktop/strawberry_nextjs’]
INFO: Uvicorn working on http://[::]:8000 (Press CTRL+C to give up)
INFO: Began reloader course of [56427] utilizing watchgod
INFO: Began server course of [56429]
INFO: Ready for software startup.
INFO: Software startup full.
Now go to https://127.0.0.1:8000/graphql and you ought to be greeted by the interactive GraphiQL playground:

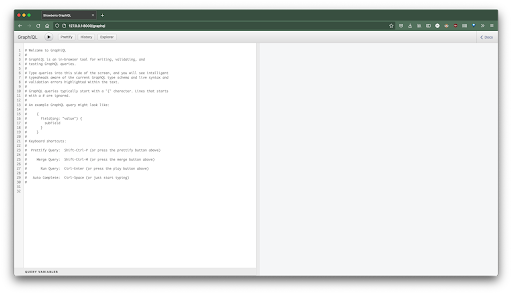
Attempt executing this question:
question MyQuery {
allAuthors
}
This could output an empty record. That is anticipated as a result of we don’t have any authors in our record. Nonetheless, we are able to repair this by working a mutation first after which working the above question.
To create a brand new writer, run the addAuthor mutation:
mutation MyMutation {
addAuthor(title: "Yasoob")
}
And now in the event you run the allAuthors question, you need to see Yasoob within the output record:
{
"information": {
"allAuthors": [
"Yasoob"
]
}
}
You may need already realized this by now, however Strawberry robotically converts our camel_case fields into PascalCase fields internally in order that we are able to observe the conference of utilizing PascalCase in our GraphQL API calls and camel_case in our Python code.
With the fundamentals down, let’s go forward and begin engaged on our bookstore-type software.
Defining the schema
The very very first thing we have to determine is what our schema goes to be. What queries, mutations, and kinds do we have to outline for our software.
I can’t be specializing in GraphQL fundamentals however relatively solely on the Strawberry-specific elements on this article. As I already talked about, we will likely be following the concept of a bookstore. We are going to retailer the information for authors and their books. That is what our database will seem like on the finish:

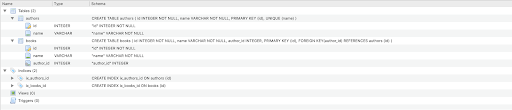
Defining SQLAlchemy fashions
We will likely be working with SQLAlchemy, so let’s outline each of our fashions as lessons. We will likely be utilizing async SQLAlchemy. Create a brand new fashions.py file within the strawberry_nextjs folder and add the next imports to it:
import asyncio from contextlib import asynccontextmanager from typing import AsyncGenerator, Optionally available from sqlalchemy import Column, ForeignKey, Integer, String from sqlalchemy.ext.asyncio import AsyncSession, create_async_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import relationship, sessionmaker
These imports will make sense in only a bit. We will likely be defining our fashions declaratively utilizing lessons that may inherit from the declarative base mannequin from SQLAlchemy. SQLAlchemy gives us with declarative_base() perform to get the declarative base mannequin. Let’s use that and outline our fashions:
Base = declarative_base()
class Writer(Base):
__tablename__ ="authors"
id: int = Column(Integer, primary_key=True, index=True)
title: str = Column(String, nullable=False, distinctive=True)
books: record["Book"] = relationship("E-book", lazy="joined", back_populates="writer")
class E-book(Base):
__tablename__ ="books"
id: int = Column(Integer, primary_key=True, index=True)
title: str = Column(String, nullable=False)
author_id: Optionally available[int] = Column(Integer, ForeignKey(Writer.id), nullable=True)
writer: Optionally available[Author] = relationship(Writer, lazy="joined", back_populates="books")
Our Writer class defines two columns: id and title. books is only a relationship attribute that helps us navigate the relationships between fashions however is just not saved within the authors desk as a separate column. We again populate the books attribute as writer. Because of this we are able to entry ebook.writer to entry the linked writer for a ebook.
The E-book class is similar to the Writer class. We outline a further author_idcolumn that hyperlinks authors and books. That is saved within the ebook desk, in contrast to the relationships. And we additionally again populate the writer attribute as books. This manner we are able to entry the books of a selected writer like this: writer.books.
Now we have to inform SQLAlchemy which DB to make use of and the place to seek out it:
engine = create_async_engine(
"sqlite+aiosqlite:///./database.db", connect_args={"check_same_thread": False}
)
We use aiosqlite as a part of the connection string as aiosqlite permits SQLAlchemy to use theSQLiteDBin an async method. And we cross the check_same_thread argument to verify we are able to use the identical connection throughout a number of threads.
It’s not secure to make use of SQLite in a multithreaded trend with out taking additional care to verify information doesn’t get corrupted on concurrent write operations, so it’s endorsed to make use of PostgreSQL or an identical high-performance DB in manufacturing.
Subsequent, we have to create a session:
async_session = sessionmaker( bind=engine, class_=AsyncSession, expire_on_commit=False, autocommit=False, autoflush=False, )
And to verify we correctly shut the session on every interplay, we’ll create a brand new context supervisor:
@asynccontextmanager async def get_session() -> AsyncGenerator[AsyncSession, None]: async with async_session() as session: async with session.start(): attempt : yield session lastly : await session.shut()
We will use the session with out the context supervisor too, however it’ll imply that we should shut the session manually after every session utilization.
Lastly, we want to verify we now have the brand new DB created. We will add some code to the fashions.py file that may create a brand new DB file utilizing our declared fashions if we attempt to execute the fashions.py file immediately:
async def _async_main():
async with engine.start() as conn:
await conn.run_sync(Base.metadata.drop_all)
await conn.run_sync(Base.metadata.create_all)
await engine.dispose()
if __name__=="__main__":
print("Dropping and re/creating tables")
asyncio.run(_async_main())
print("Completed.")
It will drop all the prevailing tables in our DB and recreate them based mostly on the fashions outlined on this file. We will add safeguards and ensure we don’t delete our information unintentionally, however that’s past the scope of this text. I’m simply making an attempt to point out you ways all the things ties collectively.
Now our fashions.py file is full and we’re able to outline our Strawberry Writer and E-book varieties that may map onto the SQLAlchemy fashions.
Defining Strawberry varieties
By the point you learn this text, Strawberry may need secure inbuilt help for immediately utilizing SQLAlchemy fashions, however for now, we now have to outline customized Strawberry varieties that may map on to SQLAlchemy fashions. Let’s outline these first after which perceive how they work. Put this code within the app.py file:
import fashions
@strawberry.kind
class Writer:
id: strawberry.ID
title: str
@classmethod
def marshal(cls, mannequin: fashions.Writer) ->”Writer”:
return cls(id=strawberry.ID(str(mannequin.id)), title=mannequin.title)
@strawberry.kind
class E-book:
id: strawberry.ID
title: str
writer: Optionally available[Author] =None
@classmethod
def marshal(cls, mannequin: fashions.E-book) ->”E-book”:
return cls(
id=strawberry.ID(str(mannequin.id)),
title=mannequin.title,
writer=Writer.marshal(mannequin.writer) if mannequin.writer else None,
)
To outline a brand new kind, we merely create a category and beautify it with the strawberry.kind decorator. That is similar to how we outlined the Mutation and Question varieties. The one distinction is that this time, we is not going to cross these varieties on to strawberry.Schema so Strawberry gained’t deal with them as Mutation or Question varieties.
Every class has a marshal methodology. This methodology is what permits us to soak up an SQLAlchemy mannequin and create a Strawberry kind class occasion from it. Strawberry makes use of strawberry.ID to signify a singular identifier to an object. Strawberry gives a couple of scalar varieties by default that work identical to strawberry.ID. It’s as much as us how we use these to map our SQLAlchemy information to this practice kind class attribute. We typically attempt to discover the perfect and carefully resembling various to the SQLAlchemy column kind and use that.
Within the E-book class, I additionally present you how one can mark a kind attribute as elective and supply a default worth. We mark the writer as elective. That is simply to point out you ways it’s completed and in a while; I’ll mark this as required.
One other factor to notice is that we are able to additionally outline a listing of return varieties for our mutation and question calls. This makes positive our GraphQL API client can course of the output appropriately based mostly on the return kind it receives. If you realize about GraphQL, then that is how we outline fragments. Let’s first outline the kinds after which I’ll present you the best way to use them as soon as we begin defining our new mutation and question lessons:
@strawberry.kind
class AuthorExists:
message: str ="Writer with this title already exists"
@strawberry.kind
class AuthorNotFound:
message: str ="Could not discover an writer with the provided title"
@strawberry.kind
class AuthorNameMissing:
message: str ="Please provide an writer title"
AddBookResponse = strawberry.union("AddBookResponse", (E-book, AuthorNotFound, AuthorNameMissing))
AddAuthorResponse = strawberry.union("AddAuthorResponse", (Writer, AuthorExists))
We’re principally saying that our AddBookResponse and AddAuthorResponse varieties are union varieties and may be both of the three (or two) varieties listed within the tuple.
Defining queries and mutations
Let’s outline our queries now. We could have solely two queries. One to record all of the books and one to record all of the authors:
from sqlalchemy import choose # ... @strawberry.kind class Question: @strawberry.subject async* def* books(self) -> record[Book]: async* with* fashions.get_session() as s: sql = choose(fashions.E-book).order_by(fashions.E-book.title) db_books = ( await s.execute(sql)).scalars().distinctive().all() return [Book.marshal(book) for book in db_books] @strawberry.subject async* def* authors(self) -> record[Author]: async* with* fashions.get_session() as s: sql = choose(fashions.Writer).order_by(fashions.Writer.title) db_authors = ( await s.execute(sql)).scalars().distinctive().all() return [Author.marshal(loc) for loc in db_authors]
There appears to be rather a lot occurring right here, so let’s break it down.
Firstly, have a look at the books resolver. We use the get_session context supervisor to create a brand new session. Then we create a brand new SQL assertion that selects E-book fashions and orders them based mostly on the ebook title. Afterward, we execute the SQL assertion utilizing the session we created earlier and put the leads to the db_books variable. Lastly, we marshal every ebook right into a Strawberry E-book kind and return that as an output. We additionally mark the return kind of books resolver as a record of Books.
The authors resolver is similar to the books resolver, so I don’t want to elucidate that.
Let’s write our mutations now:
@strawberry.kind class Mutation: @strawberry.mutation async* def* add_book(self, title: str, author_name: Optionally available[str]) -> AddBookResponse: async* with* fashions.get_session() as s: db_author =None if author_name: sql = choose(fashions.Writer).the place(fashions.Writer.title == author_name) db_author = ( await s.execute(sql)).scalars().first() if* not* db_author: return AuthorNotFound() else : return AuthorNameMissing() db_book = fashions.E-book(title=title, writer=db_author) s.add(db_book) await s.commit() return E-book.marshal(db_book) @strawberry.mutation async* def* add_author(self, title: str) -> AddAuthorResponse: async* with* fashions.get_session() as s: sql = choose(fashions.Writer).the place(fashions.Writer.title == title) existing_db_author = ( await s.execute(sql)).first() if existing_db_author is* notNone: *return AuthorExists() db_author = fashions.Writer(title=title) s.add(db_author) await s.commit() return Writer.marshal(db_author)
Mutations are pretty easy. Let’s begin with the add_book mutation.
add_book takes within the title of the ebook and the title of the writer as inputs. I’m defining the author_name as elective simply to point out you how one can outline elective arguments, however within the methodology physique, I implement the presence of author_name by returning AuthorNameMissing if the author_name is just not handed in.
I filter Authors in db based mostly on the handed in author_name and be sure that an writer with the required title exists. In any other case, I return AuthorNotFound. If each of those checks cross, I create a brand new fashions.E-book occasion, add it to the db by way of the session, and commit it. Lastly, I return a marshaled ebook because the return worth.
add_author is nearly the identical as add_book, so no purpose to go over the code once more.
We’re nearly completed on the Strawberry facet, however I’ve one bonus factor to share, and that’s information loaders.
One other (not at all times) enjoyable characteristic of GraphQL is recursive resolvers. You noticed above that within the marshal methodology of E-book I additionally outline writer. This manner we are able to run a GraphQL question like this:
question {
ebook {
writer {
title
}
}
}
However what if we need to run a question like this:
question {
writer {
books {
title
}
}
}
This is not going to work as a result of we haven’t outlined a books attribute on our Strawberry kind. Let’s rewrite our Writer class and add a DataLoader to the default context Strawberry gives us in our class strategies:
from strawberry.dataloader import DataLoader
# ...
@strawberry.kind
class Writer:
id: strawberry.ID
title: str
@strawberry.subject
async* def* books(self, data: Data) -> record["Book"]:
books = await data.context["books_by_author"].load(self.id)
return [Book.marshal(book) for book in books]
@classmethod
def marshal(cls, mannequin: fashions.Writer) ->"Writer":
return cls(id=strawberry.ID(str(mannequin.id)), title=mannequin.title)
# ...
async* def* load_books_by_author(keys: record) -> record[Book]:
async* with* fashions.get_session() as s:
all_queries = [select(models.Book).where(models.Book.author_id == key) for key in keys]
information = [( await s.execute(sql)).scalars().unique().all() for sql in all_queries]
print(keys, information)
return information
async* def* get_context() -> dict:
return {
"books_by_author": DataLoader(load_fn=load_books_by_author),
}
# ...
graphql_app = GraphQLRouter(schema, context_getter=get_context)
Let’s perceive this from the underside up. Strawberry permits us to cross customized capabilities to our class (these wrapped with @strawberry.kind) strategies by way of a context. This context is shared throughout a single request.
DataLoader permits us to batch a number of requests in order that we are able to cut back backwards and forwards calls to the db. We create a DataLoader occasion and inform it the best way to load books from the db for the passed-in writer. We put this DataLoader in a dictionary and cross that because the context_getter argument to GraphQLRouter. This makes the dictionary obtainable to our class strategies by way of data.context. We use that to load the books for every writer.
On this instance, DataLoader isn’t tremendous helpful. Its principal advantages shine by once we name the DataLoader with a listing of arguments. That reduces the database calls significantly. And DataLoaders additionally cache output and they’re shared in a single request. Due to this fact, in the event you had been to cross the identical arguments to the information loader in a single request a number of instances, it is not going to lead to further database hits. Tremendous highly effective!
Testing out Strawberry
The uvicorn occasion ought to robotically reload when you make these code adjustments and save them. Go over to http://127.0.0.1:8000/graphql and check out the most recent code.
Attempt executing the next mutation twice:
mutation Writer {
addAuthor(title: "Yasoob") {
... on Writer {
id
title
}
... on AuthorExists{
message
}
}
}
The primary time it ought to output this:
{
"information": {
"addAuthor": {
"id": "1",
"title": "Yasoob"
}
}
}
And the second time it ought to output this:
{
"information": {
"addAuthor": {
"message": "Writer with this title exist already"
}
}
}

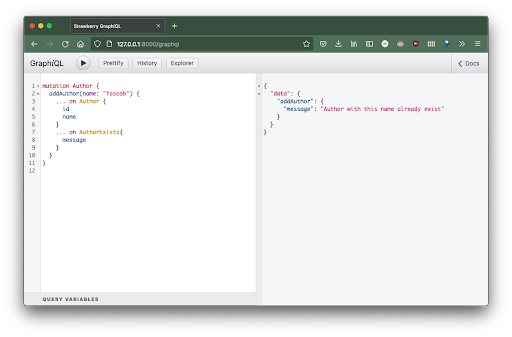
Now let’s attempt including new books:
mutation E-book {
addBook(title: "Sensible Python Tasks", authorName: "Yasoob") {
... on E-book {
id
title
}
}
}

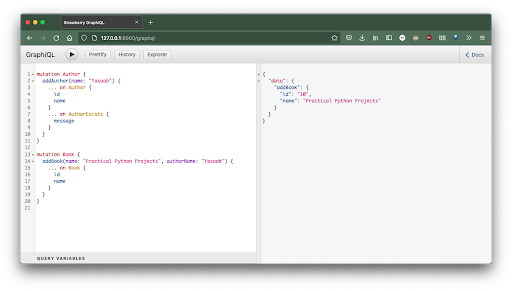
Candy! Our Python/Strawberry facet is working completely advantageous. However now we have to tie this up on the Node/Subsequent.js facet.
Organising Node dependencies
We will likely be utilizing graphql-codegen to robotically create typed hooks for us. So the fundamental workflow will likely be that earlier than we are able to use a GraphQL question, mutation, or fragment in our Typescript code, we’ll outline that in a GraphQL file. Then graphql-codegen will introspect our Strawberry GraphQL API and create varieties and use our customized outlined GraphQL Question/Mutations/Fragments to create customized urql hooks.
urql is a reasonably full-featured GraphQL library for React that makes interacting with GraphQL APIs rather a lot less complicated. By doing all this, we’ll cut back loads of effort in coding typed hooks ourselves earlier than we are able to use our GraphQL API in our Subsequent.js/React app.
Earlier than we are able to transfer on, we have to set up a couple of dependencies:
$ npm set up graphql $ npm set up @graphql-codegen/cli $ npm set up @graphql-codegen/typescript $ npm set up @graphql-codegen/typescript-operations $ npm set up @graphql-codegen/typescript-urql $ npm set up urql
Right here we’re putting in urql and some plugins for @graphql-codegen.
Organising graphql-codegen
Now we’ll create a codegen.yml file within the root of our challenge that may inform graphql-codegen what to do:
overwrite: true schema: "http://127.0.0.1:8000/graphql" paperwork: './graphql/**/*.graphql' generates: graphql/graphql.ts: plugins:
-
- “typescript-operations”
We’re informing graphql-codegen that it may possibly discover the schema for our GraphQL API at http://127.0.0.1:8000/graphql. We additionally inform it (by way of the paperwork key) that we now have outlined our customized fragments, queries, and mutations in graphql information positioned within the graphql folder. Then we instruct it to generate graphql/graphql.ts file by working the schema and paperwork by three plugins.
Now make a graphql folder in our challenge listing and create a brand new operations.graphql file inside it. We are going to outline all of the fragments, queries, and mutations we plan on utilizing in our app. We will create separate information for all three and graphql-codegen will robotically merge them whereas processing, however we’ll hold it easy and put all the things in a single file for now. Let’s add the next GraphQL to operations.graphql:
question Books {
books {
...BookFields
}
}
question Authors {
authors {
...AuthorFields
}
}
fragment BookFields on E-book {
id
title
writer {
title
}
}
fragment AuthorFields on Writer {
id
title
}
mutation AddBook($title: String!, $authorName: String!) {
addBook(title: $title, authorName: $authorName) {
__typename
... on E-book {
__typename
...BookFields
}
}
}
mutation AddAuthor($title: String!) {
addAuthor(title: $title) {
__typename
... on AuthorExists {
__typename
message
}
... on Writer {
__typename
...AuthorFields
}
}
}
That is similar to the code we had been executing within the GraphiQL on-line interface. This GraphQL code will inform graphql-codegen which urql mutation and question hooks it wants to supply for us.
There has been dialogue to make graphql-codegen generate all mutations and queries by introspecting our on-line GraphQL API, however up to now it’s not potential to try this utilizing solely graphql-codegen. There do exist instruments that will let you try this, however I’m not going to make use of them on this article. You possibly can discover them by yourself.
Let’s edit package deal.json file subsequent and add a command to run graphql-codegen by way of npm. Add this code within the scripts part:
"codegen": "graphql-codegen --config codegen.yml"
Now we are able to go to the terminal and run graphql-codegen:
$ npm run codegen
If the command succeeds, you need to have a graphql.ts file in graphql folder. We will go forward and use the generated urql hooks in our Subsequent code like so:
import {
useAuthorsQuery,
} from "../graphql/graphql";
// ....
const [result] = useAuthorsQuery(...);
You possibly can learn extra concerning the graphql-codegen urql plugin right here.
Resolve CORS situation
In a manufacturing setting, you’ll be able to serve the GraphQL API and the Subsequent.js/React app from the identical area+PORT and that may be sure you don’t encounter CORS points. For the event setting, we are able to add some proxy code to subsequent.config.js file to instruct NextJS to proxy all calls to /graphql to uvicorn that’s working on a special port:
/** _ @kind _ {import('subsequent').NextConfig} */
module.exports= {
reactStrictMode: true ,
async rewrites() {
return {
beforeFiles: [
{
source:"/graphql",
destination:"http://localhost:8000/graphql",
},
],
};
},
};
It will be sure you don’t encounter any CORS points on native growth both.
Conclusion
I hope you realized a factor or two from this text. I intentionally didn’t go into an excessive amount of element on any single matter as such articles exist already on-line, however it is vitally onerous to seek out an article that exhibits you ways all the things connects collectively.
You will discover all of the code for this text on my GitHub. Sooner or later, I’d create a full challenge to point out you amore concrete instance of how one can make use of the generated code in your apps. Within the meantime, you’ll be able to check out this repo, which was inspiration for this text. Jokull was most likely the primary individual to publicly host a challenge combining all of those totally different instruments. Thanks, Jokull!
Additionally, if in case you have any Python or net growth tasks in thoughts, attain out to me at [email protected] and share your concepts. I do fairly quite a lot of tasks so nearly nothing is out of the unusual. Let’s create one thing superior collectively. 
Goodbye! 
Monitor failed and sluggish GraphQL requests in manufacturing
Whereas GraphQL has some options for debugging requests and responses, ensuring GraphQL reliably serves assets to your manufacturing app is the place issues get harder. Should you’re taken with making certain community requests to the backend or third occasion companies are profitable, attempt LogRocket.
 https://logrocket.com/signup/
https://logrocket.com/signup/
LogRocket is sort of a DVR for net and cellular apps, recording actually all the things that occurs in your website. As an alternative of guessing why issues occur, you’ll be able to combination and report on problematic GraphQL requests to rapidly perceive the foundation trigger. As well as, you’ll be able to monitor Apollo consumer state and examine GraphQL queries’ key-value pairs.
LogRocket: Full visibility into manufacturing Subsequent.js apps
Debugging Subsequent functions may be troublesome, particularly when customers expertise points which can be troublesome to breed. Should you’re taken with monitoring and monitoring state, robotically surfacing JavaScript errors, and monitoring sluggish community requests and part load time, attempt LogRocket. 
LogRocket is sort of a DVR for net and cellular apps, recording actually all the things that occurs in your Subsequent app. As an alternative of guessing why issues occur, you’ll be able to combination and report on what state your software was in when a difficulty occurred. LogRocket additionally displays your app’s efficiency, reporting with metrics like consumer CPU load, consumer reminiscence utilization, and extra.
The LogRocket Redux middleware package deal provides an additional layer of visibility into your consumer classes. LogRocket logs all actions and state out of your Redux shops.
Modernize the way you debug your Subsequent.js apps — begin monitoring without spending a dime.
LogRocket devices your app to file baseline efficiency timings comparable to web page load time, time to first byte, sluggish community requests, and likewise logs Redux, NgRx, and Vuex actions/state. Begin monitoring without spending a dime.

{kind=link}