
Constructing a distributed database is difficult and desires to think about many components. Beforehand, I mentioned two vital strategies, sharding and partitioning, for gaining better throughput and efficiency from databases. On this publish, I’ll talk about one other vital approach, deduplication, that can be utilized to switch transactions for ultimately constant use instances with outlined main keys.
Time sequence databases resembling InfluxDB present ease of use for purchasers and settle for ingesting the identical information greater than as soon as. For instance, edge gadgets can simply ship their information on reconnection with out having to recollect which components have been efficiently transmitted beforehand. To return right leads to such situations, time sequence databases typically apply deduplication to reach at an ultimately constant view of the information. For traditional transactional methods, the deduplication approach is probably not clearly relevant but it surely really is. Allow us to step via some examples to grasp how this works.
Understanding transactions
Knowledge inserts and updates are often carried out in an atomic commit, which is an operation that applies a set of distinct adjustments as a single operation. The adjustments are both all profitable or all aborted, there is no such thing as a center floor. The atomic commit within the database is named a transaction.
Implementing a transaction wants to incorporate restoration actions that redo and/or undo adjustments to make sure the transaction is both accomplished or utterly aborted in case of incidents in the course of the transaction. A typical instance of a transaction is a cash switch between two accounts, by which both cash is withdrawn from one account and deposited to a different account efficiently or no cash adjustments arms in any respect.
In a distributed database, implementing transactions is much more difficult as a result of want to speak between nodes and tolerate varied communication issues. Paxos and Raft are frequent strategies used to implement transactions in distributed methods and are well-known for his or her complexity.
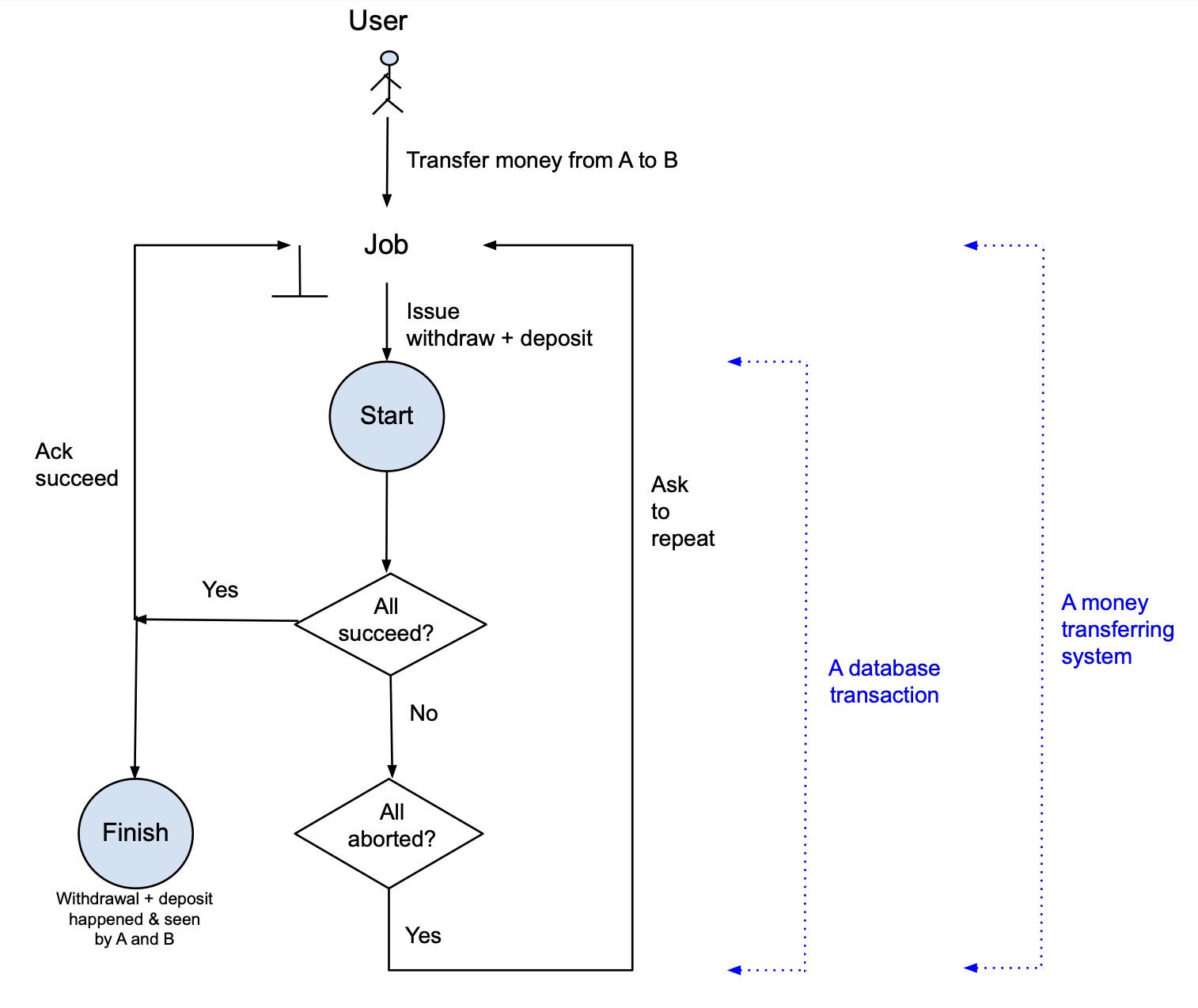
Determine 1 reveals an instance of a cash transferring system that makes use of a transactional database. When a buyer makes use of a financial institution system to switch $100 from account A to account B, the financial institution initiates a transferring job that begins a transaction of two adjustments: withdraw $100 from A and deposit $100 to B. If the 2 adjustments each succeed, the method will end and the job is completed. If for some motive the withdrawal and/or deposit can’t be carried out, all adjustments within the system will likely be aborted and a sign will likely be despatched again to the job telling it to re-start the transaction. A and B solely see the withdrawal and deposit respectively if the method is accomplished efficiently. In any other case, there will likely be no adjustments to their accounts.
 InfluxData
InfluxDataDetermine 1. Transactional movement.
Non-transactional course of
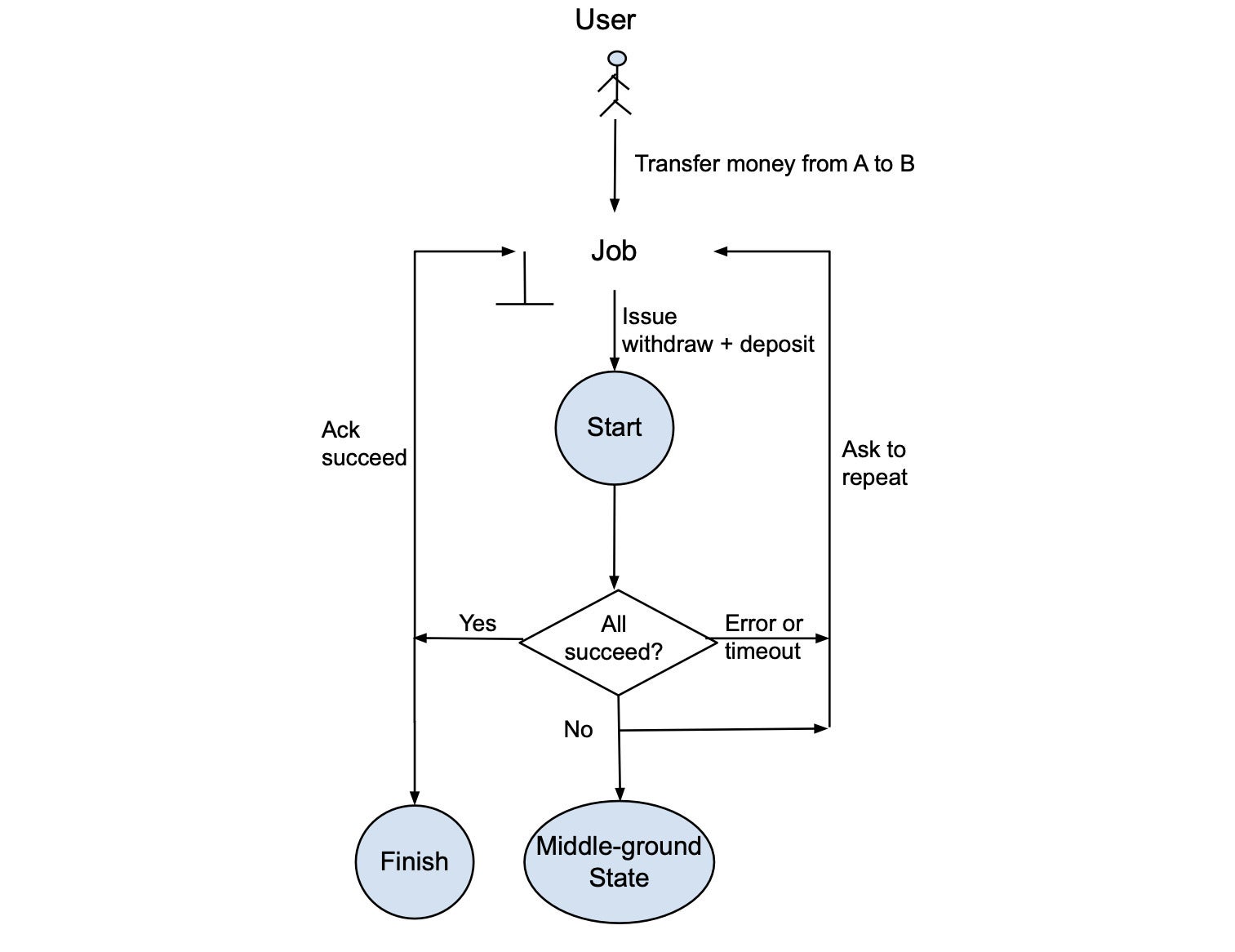
Clearly, the transactional course of is difficult to construct and keep. Nevertheless, the system might be simplified as illustrated in Determine 2. Right here, within the “non-transactional course of,” the job additionally points a withdrawal and a deposit. If the 2 adjustments succeed, the job completes. If neither or solely one of many two adjustments succeeds, or if an error or timeout occurs, the info will likely be in a “center floor” state and the job will likely be requested to repeat the withdrawal and deposit.
 InfluxData
InfluxDataDetermine 2. Non-transactional movement.
The information outcomes within the “center floor” state might be totally different for varied restarts on the identical switch however they’re acceptable to be within the system so long as the proper end state will ultimately occur. Allow us to go over an instance to indicate these outcomes and clarify why they’re acceptable. Desk 1 reveals two anticipated adjustments if the transaction is profitable. Every change contains 4 fields:
- AccountID that uniquely identifies an account.
- Exercise that’s both a withdrawal or a deposit.
- Quantity that’s the amount of cash to withdraw or deposit.
- BankJobID that uniquely identifies a job in a system.
|
AccountID |
Exercise |
Quantity |
BankJobID |
|
A |
Withdrawal |
100 |
543 |
|
B |
Deposit |
100 |
543 |
At every repetition of issuing the withdrawal and deposit illustrated in Determine 2, there are 4 potential outcomes:
- No adjustments.
- Solely A is withdrawn.
- Solely B is deposited.
- Each A is withdrawn and B is deposited.
To proceed our instance, allow us to say it takes 4 tries earlier than the job succeeds and an acknowledgement of success is distributed. The primary strive produces “solely B is deposited,” therefore the system has just one change as proven in Desk 2. The second strive produces nothing. The third strive produces “solely A is withdrawn,” therefore the system now has two rows as proven in Desk 3. The fourth strive produces “each A is withdrawn and B is deposited,” therefore the info within the completed state seems to be like that proven in Desk 4.
|
AccountID |
Exercise |
Quantity |
BankJobID |
|
B |
Deposit |
100 |
543 |
–
|
AccountID |
Exercise |
Quantity |
BankJobID |
|
B |
Deposit |
100 |
543 |
|
A |
Withdrawal |
100 |
543 |
–
|
AccountID |
Exercise |
Quantity |
BankJobID |
|
B |
Deposit |
100 |
543 |
|
A |
Withdrawal |
100 |
543 |
|
A |
Withdrawal |
100 |
543 |
|
B |
Deposit |
100 |
543 |
Knowledge deduplication for eventual consistency
The four-try instance above creates three totally different information units within the system, as proven in Tables 2, 3, and 4. Why do we are saying that is acceptable? The reply is that information within the system is allowed to be redundant so long as we are able to handle it successfully. If we are able to establish the redundant information and remove that information at learn time, we will produce the anticipated outcome.
On this instance, we are saying that the mixture of AccountID, Exercise, and BankJobID uniquely identifies a change and is named a key. If there are numerous adjustments related to the identical key, then solely one in all them is returned throughout learn time. The method to remove redundant info is named deduplication. Due to this fact, once we learn and deduplicate information from Tables 3 and 4, we are going to get the identical returned values that comprise the anticipated final result proven in Desk 1.
Within the case of Desk 2, which incorporates just one change, the returned worth will likely be solely part of the anticipated final result of Desk 1. This implies we don’t get robust transactional ensures, but when we’re prepared to attend to reconcile the accounts, we are going to ultimately get the anticipated final result. In actual life, banks don’t launch transferred cash for us to make use of instantly even when we see it in our account. In different phrases, the partial change represented by Desk 2 is appropriate if the financial institution makes the transferred cash out there to make use of solely after a day or two. As a result of the method of our transaction is repeated till it’s profitable, a day is greater than sufficient time for the accounts to be reconciled.
The mix of the non-transactional insert course of proven in Determine 2 and information deduplication at learn time doesn’t present the anticipated outcomes instantly however ultimately the outcomes would be the similar as anticipated. That is known as an ultimately constant system. In contrast, the transactional system illustrated in Determine 1 all the time produces constant outcomes. Nevertheless, as a result of difficult communications requited to ensure that consistency, a transaction does take time to complete and the variety of transactions per second will consequently be restricted.
Deduplication in observe
These days, most databases implement an replace as a delete after which an insert to keep away from the costly in-place information modification. Nevertheless, if the system helps deduplication, the replace can simply be executed as an insert if we add a “Sequence” subject within the desk to establish the order by which the info has entered the system.
For instance, after making the cash switch efficiently as proven in Desk 5, let’s say we discovered the quantity needs to be $200 as an alternative. This may very well be mounted by making a brand new switch with the identical BankJobID however the next Sequence quantity as proven in Desk 6. At learn time, the deduplication would return solely the rows with the best sequence quantity. Thus, the rows with quantity $100 would by no means be returned.
|
AccountID |
Exercise |
Quantity |
BankJobID |
Sequence |
|
B |
Deposit |
100 |
543 |
1 |
|
A |
Withdrawal |
100 |
543 |
1 |
–
|
AccountID |
Exercise |
Quantity |
BankJobID |
Sequence |
|
B |
Deposit |
100 |
543 |
1 |
|
A |
Withdrawal |
100 |
543 |
1 |
|
A |
Withdrawal |
200 |
543 |
2 |
|
B |
Deposit |
200 |
543 |
2 |
–
As a result of deduplication should evaluate information to search for rows with the identical key, organizing information correctly and implementing the proper deduplication algorithms are essential. The frequent approach is sorting information inserts on their keys and utilizing a merge algorithm to search out duplicates and deduplicate them. The small print of how information is organized and merged will rely upon the character of the info, their measurement, and the out there reminiscence within the system. For instance, Apache Arrow implements a multi-column kind merge that’s essential to carry out efficient deduplication.
Performing deduplication throughout learn time will improve the time wanted to question information. To enhance question efficiency, deduplication might be executed as a background job to take away redundant information forward of time. Most methods already run background jobs to reorganize information, resembling eradicating information that was beforehand marked to be deleted. Deduplication matches very properly in that mannequin that reads information, deduplicates or removes redundant information, and writes the outcome again.
With a purpose to keep away from sharing CPU and reminiscence sources with information loading and studying, these background jobs are often carried out in a separate server known as a compactor, which is one other massive subject that deserves its personal publish.
Nga Tran is a employees software program engineer at InfluxData and a member of the corporate’s IOx group, which is constructing the next-generation time sequence storage engine for InfluxDB. Earlier than InfluxData, Nga labored at Vertica Techniques the place she was one of many key engineers who constructed the question optimizer for Vertica and later ran Vertica’s engineering group. In her spare time, Nga enjoys writing and posting supplies for constructing distributed databases on her weblog.
—
New Tech Discussion board supplies a venue to discover and talk about rising enterprise expertise in unprecedented depth and breadth. The choice is subjective, primarily based on our decide of the applied sciences we consider to be vital and of biggest curiosity to InfoWorld readers. InfoWorld doesn’t settle for advertising and marketing collateral for publication and reserves the proper to edit all contributed content material. Ship all inquiries to newtechforum@infoworld.com.
Copyright © 2023 IDG Communications, Inc.

{kind=link}