Retrieval Augmented Era (RAG) has turn into a preferred strategy to harness LLMs for query answering utilizing your personal corpus of information. Usually, the context to reinforce the question that’s handed into the Massive Language Mannequin (LLM) to generate a solution comes from a database or search index containing your area information. When it’s a search index, the development is to make use of Vector search (HNSW ANN primarily based) over Lexical (BM25/TF-IDF primarily based) search, usually combining each Lexical and Vector searches into Hybrid search pipelines.
Up to now, I’ve labored on Data Graph (KG) backed entity search platforms, and noticed that for sure forms of queries, they produce outcomes which are superior / extra related in comparison with that produced from an ordinary lexical search platform. The GraphRAG framework from Microsoft Analysis describes a complete approach to leverage KG for RAG. GraphRAG helps produce higher high quality solutions within the following two conditions.
- the reply requires synthesizing insights from disparate items of knowledge via their shared attributes
- the reply requires understanding summarized semantic ideas over a part of or the complete corpus
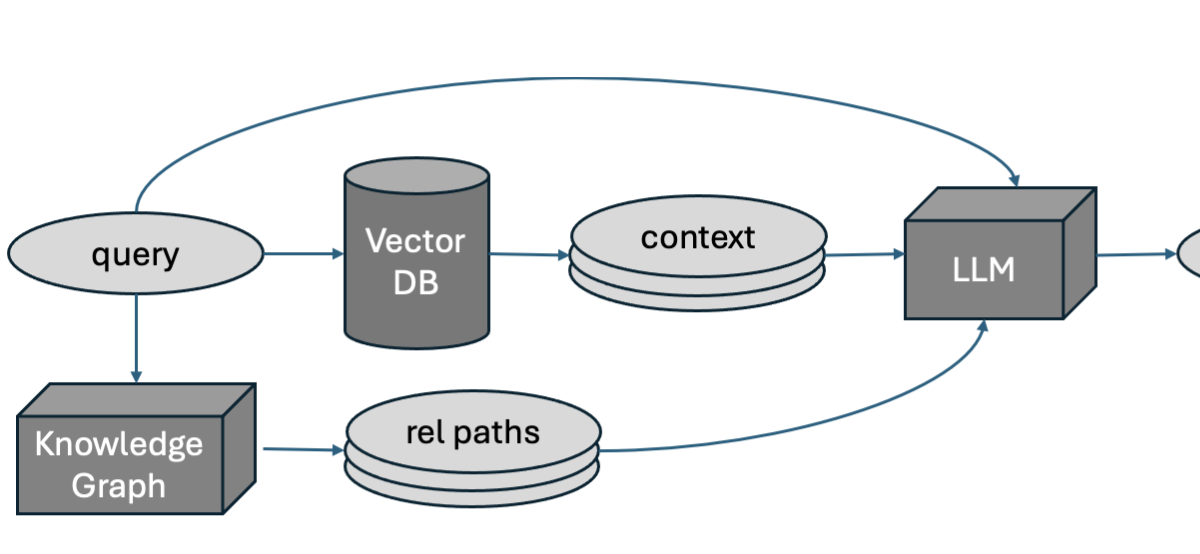
The total GraphRAG strategy consists of constructing a KG out of the corpus, after which querying the ensuing KG to reinforce the context in Retrieval Augmented Era. In my case, I already had entry to a medical KG, so I targeted on constructing out the inference facet. This publish describes what I needed to do to get that to work. It’s primarily based largely on the concepts described on this Data Graph RAG Question Engine web page from the LlamaIndex documentation.
At a excessive stage, the concept is to extract entities from the query, after which question a KG with these entities to seek out and extract relationship paths, single or multi-hop, between them. These relationship paths are used, along side context extracted from the search index, to reinforce the question for RAG. The connection paths are the shortest paths between pairs of entities within the KG, and we solely take into account paths upto 2 hops in size (since longer paths are prone to be much less fascinating).

Our medical KG is saved in an Ontotext RDF retailer. I’m certain we will compute shortest paths in SPARQL (the usual question language for RDF) however Cypher appears easier for this use case, so I made a decision to dump out the nodes and relationships from the RDF retailer into flat information that appear to be the next, after which add them to a Neo4j graph database utilizing neo4j-admin database import full.
1 2 3 4 5 6 7 8 9 |
# nodes.csv cid:ID,cfname,stygrp,:LABEL C8918738,Acholeplasma parvum,organism,Ent ... # relationships.csv :START_ID,:END_ID,:TYPE,relname,rank C2792057,C8429338,Rel,HAS_DRUG,7 ... |
The primary line in each CSV information are the headers that inform Neo4j in regards to the schema. Right here our nodes are of kind Ent and relationships are of kind Rel, cid is an ID attribute that’s used to attach nodes, and the opposite parts are (scalar) attributes of every node. Entities had been extracted utilizing our Dictionary-based Named Entity Recognizer (NER) primarily based on the Aho-Corasick algorithm, and shortest paths are computed between every pair of entities (indicated by placeholders _LHS_ and _RHS_) extracted utilizing the next Cypher question.
1 2 |
MATCH p = allShortestPaths((a:Ent {cid:'_LHS_'})-[*..]-(b:Ent {cid:'_RHS_'})) RETURN p, size(p) |
Shortest paths returned by the Cypher question which are greater than 2 hops lengthy are discarded, since these do not point out sturdy / helpful relationships between the entity pairs. The ensuing checklist of relationship paths are handed into the LLM together with the search outcome context to provide the reply.
We evaluated this implementation towards the baseline RAG pipeline (our pipeline minus the relation paths) utilizing the RAGAS metrics Reply Correctness and Reply Similarity. Reply Correctness measures the factual similarity between the bottom fact reply and the generated reply, and Reply Similarity measures the semantic similarity between these two parts. Our analysis set was a set of fifty queries the place the bottom fact was assigned by human area specialists. The LLM used to generate the reply was Claude-v2 from Anthropic whereas the one used for analysis was Claude-v3 (Sonnet). The desk under reveals the averaged Reply Correctness and Similarity over all 50 queries, for the Baseline and my GraphRAG pipeline respectively.
| Pipeline | Reply Correctness | Reply Similarity |
|---|---|---|
| Baseline | 0.417 | 0.403 |
| GraphRAG (inference) | 0.737 | 0.758 |
As you’ll be able to see, the efficiency acquire from utilizing the KG to reinforce the question for RAG appears to be fairly spectacular. Since we have already got the KG and the NER out there from earlier tasks, it’s a very low effort addition to make to our pipeline. In fact, we would wish to confirm these outcomes utilizing Additional human evaluations.
I just lately got here throughout the paper Data Graph primarily based Thought: A Data Graph enhanced LLM Framework for pan-cancer Query Answering (Feng et al, 2024). In it, the authors determine 4 broad courses of triplet patterns that their questions (i.e, of their area) might be decomposed to, and addressed utilizing reasoning approaches backed by Data Graphs — One hop, Multi-hop, Intersection and Attribute issues. The concept is to make use of an LLM immediate to determine the entities and relationships within the query, then use an LLM to find out which of those templates needs to be used to handle the query and produce a solution. Relying on the trail chosen, an LLM is used to generate a Cypher question (an business commonplace question language for graph databases initially launched by Neo4j) to extract the lacking entities and relationships within the template and reply the query. An fascinating future path for my GraphRAG implementation can be to include a few of the concepts from this paper.

 Sparkles
Sparkles {kind=link}