Introduction
This information is the second a part of three guides about Assist Vector Machines (SVMs). On this information, we’ll preserve engaged on the cast financial institution notes use case, perceive what SVM parameters are already being set by Scikit-learn, what are C and Gamma hyperparameters, and easy methods to tune them utilizing cross validation and grid search.
Within the full sequence of SVM guides, moreover SVM hyperparameters, additionally, you will study easy SVM, an idea known as the kernel trick, and discover different varieties of SVMs.
When you want to learn all of the guides, check out the primary information, or see which of them pursuits you essentially the most, beneath is the desk of subjects lined in every information:
- Use case: neglect financial institution notes
- Background of SVMs
- Easy (Linear) SVM Mannequin
- Concerning the Dataset
- Importing the Dataset
- Exploring the Dataset
- Implementing SVM with Scikit-Be taught
- Dividing Information into Prepare/Take a look at Units
- Coaching the Mannequin
- Making Predictions
- Evaluating the Mannequin
- Deciphering Outcomes
2. Understanding SVM Hyperparameters
- The C Hyperparameter
- The Gamma Hyperparameter
3. Implementing different SVM flavors with Python’s Scikit-Be taught (coming quickly!)
- The Normal Concept of SVMs (a recap)
- Kernel (trick) SVM
- Implementing non-linear kernel SVM with Scikit-Be taught
- Importing libraries
- Importing the dataset
- Dividing knowledge into options (X) and goal (y)
- Dividing Information into Prepare/Take a look at Units
- Coaching the Algorithm
- Polynomial kernel
- Making Predictions
- Evaluating the Algorithm
- Gaussian kernel
- Prediction and Analysis
- Sigmoid Kernel
- Prediction and Analysis
- Comparability of Non-Linear Kernel Performances
Let’s learn to implement cross validation and carry out a hyperparameter tuning.
SVM Hyperparameters
To see all mannequin parameters which have already been set by Scikit-learn and its default values, we will use the get_params() technique:
svc.get_params()
This technique shows:
{'C': 1.0,
'break_ties': False,
'cache_size': 200,
'class_weight': None,
'coef0': 0.0,
'decision_function_shape': 'ovr',
'diploma': 3,
'gamma': 'scale',
'kernel': 'linear',
'max_iter': -1,
'likelihood': False,
'random_state': None,
'shrinking': True,
'tol': 0.001,
'verbose': False}
Discover that there are a complete of 15 hyperparameters already being set, this occurs as a result of the SVM algorithm has many variations. We have now used the linear kernel to acquire a linear operate, however there are additionally kernels that describe different kinds of capabilities and people kernels are parametrized in several methods.
These variations occur to make the mannequin extra versatile and appropriate for locating a separation between totally different shapes of knowledge. If we will draw a line to separate our lessons, then a linear kernel will probably be a superb choice, if we’d like a curve, then a polynomial kernel could be the only option, if our knowledge has round shapes, then a Radial Foundation Perform or RBF kernel will go well with the info higher, if there are values above and beneath a threshold, a sigmoid kernel may separate the lessons higher. From what we now have explored in our knowledge, it appears that evidently both an RBF or a polynomial kernel can be extra appropriate than a linear kernel.
Now that we now have an concept that there are 4 varieties of totally different kernel capabilities, we will return to the parameters. When the SVM algorithm tries to discover a separation between lessons, we now have already understood that it attracts a classification margin between the help vectors and the separation line (or curve).
This margin is, in a way, like a buffer between the separation line and the factors. The margin dimension can fluctuate, when the margin is smaller, there may be much less house for factors that fall outdoors of the margin, making the separation between lessons clearer, so extra samples are being accurately categorized, conversely, when the margin is bigger, the separation between lessons is much less clear, and extra samples will be misclassified. In different phrases, a smaller margin means extra accurately categorized samples, and in addition a extra inflexible classifier, whereas a bigger margin, denotes extra misclassified samples, however a extra versatile classifier.
When these margins are chosen, the parameter that determines them is the C parameter.
The C Hyperparameter
The C parameter is inversely proportional to the margin dimension, which means the bigger the worth of C, the smaller the margin, and, conversely, the smaller the worth of C, the bigger the margin. The C parameter can be utilized together with any kernel, it tells the algorithm how a lot to keep away from misclassifying every coaching pattern, because of that, it is usually generally known as regularization. Our linear kernel SVM has used a C of 1.0, which is a giant worth and offers a smaller margin.

We will experiment with a smaller worth of ‘C’ and perceive in apply what occurs with a bigger margin. To try this, we’ll create a brand new classifier, svc_c, and alter solely the worth of C to 0.0001. Let’s additionally repeat the match and predict steps:
svc_c = SVC(kernel='linear', C=0.0001)
svc_c.match(X_train, y_train)
y_pred_c = svc_c.predict(X_test)
Now we will take a look at the outcomes for the check knowledge:
print(classification_report(y_test, y_pred_c))
cm_c = confusion_matrix(y_test, y_pred_c)
sns.heatmap(cm_c, annot=True, fmt='d').set_title('Confusion matrix of linear SVM with C=0.0001')
This outputs:
precision recall f1-score help
0 0.82 0.96 0.88 148
1 0.94 0.76 0.84 127
accuracy 0.87 275
macro avg 0.88 0.86 0.86 275
weighted avg 0.88 0.87 0.86 275
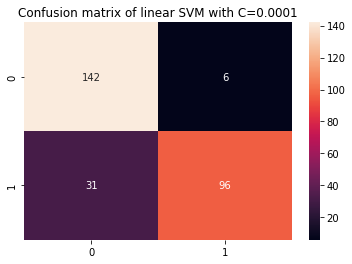
Through the use of a smaller C and acquiring a bigger margin, the classifier has turn out to be extra versatile and with extra classification errors. Within the classification report, we will see that the f1-score, beforehand 0.99 for each lessons, has lowered to 0.88 for sophistication 0, and to 0.84 for sophistication 1. Within the confusion matrix, the mannequin went from 2 to six false positives, and from 2 to 31 false negatives.
We will additionally repeat the predict step and take a look at the outcomes to examine if there may be nonetheless an overfit when utilizing practice knowledge:
y_pred_ct = svc_c.predict(X_train)
cm_ct = confusion_matrix(y_train, y_pred_ct)
sns.heatmap(cm_ct, annot=True, fmt='d').set_title('Confusion matrix of linear SVM with C=0.0001 and practice knowledge')
print(classification_report(y_train, y_pred_ct))
This ends in:
precision recall f1-score help
0 0.88 0.96 0.92 614
1 0.94 0.84 0.88 483
accuracy 0.90 1097
macro avg 0.91 0.90 0.90 1097
weighted avg 0.91 0.90 0.90 1097
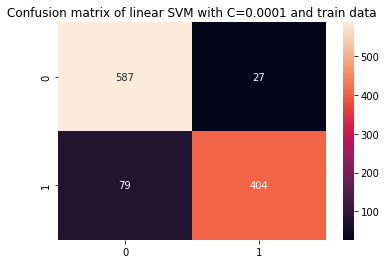
By trying on the outcomes with a smaller C and practice knowledge, we will see there was an enchancment within the overfit, however as soon as most metrics are nonetheless increased for practice knowledge, it appears that evidently the overfit hasn’t been solved. So, simply altering the C parameter wasn’t sufficient to make the mannequin extra versatile and enhance its generalization.
Be aware: Looking for steadiness between a operate getting too removed from the info, being too mounted, or having excessive bias or it is reverse, a operate becoming to shut to the info, being too versatile, or having excessive variance is often known as the bias variance trade-off. Discovering that steadiness is non trivial, however when it’s achieved, there isn’t any underfitting or overfitting of the mannequin to the info. As a manner of decreasing variance and stopping overfitting, the info will be evenly shrinked to be made extra common and simplified when acquiring a operate that describes it. That’s what the parameter C does when it’s utilized in SVM, for that cause, it is usually known as L2 regularization or Ridge Regression.
Up thus far, we now have understood concerning the margins in SVM and the way they influence the general results of the algorithm, however how concerning the line (or curve) that separates the lessons? This line is the determination boundary. So, we already know that the margins have an effect on the choice boundary flexibility in direction of errors, we will now check out one other parameter that additionally impacts the choice boundary.
Take a look at our hands-on, sensible information to studying Git, with best-practices, industry-accepted requirements, and included cheat sheet. Cease Googling Git instructions and really study it!
Be aware: The choice boundary can be known as a hyperplane. A hyperplane is a geometrical idea to check with the variety of dimensions of an area minus one (dims-1). If the house is 2-dimensional, similar to a airplane with x and y coordinates, the 1-dimensional strains (or curves) are the hyperplanes. Within the machine studying context, for the reason that variety of columns used within the mannequin are its airplane dimensions, once we are working with 4 columns and an SVM classifier, we’re discovering a three-d hyperplane that separates between lessons.
The Gamma Hyperparameter
Infinite determination boundaries will be chosen, a few of these boundaries will separate the lessons and others will not. When selecting an efficient determination boundary ought to the primary 10 nearest factors of every class be thought of? Or ought to extra factors be thought of, together with the factors which are distant? In SVM, that alternative of vary is outlined by one other hyperparameter, gamma.
Like C, gamma is considerably inversely proportional to its distance. The increased its worth, the closest are the factors which are thought of for the choice boundary, and the lowest the gamma, the farther factors are additionally thought of for selecting the choice boundary.
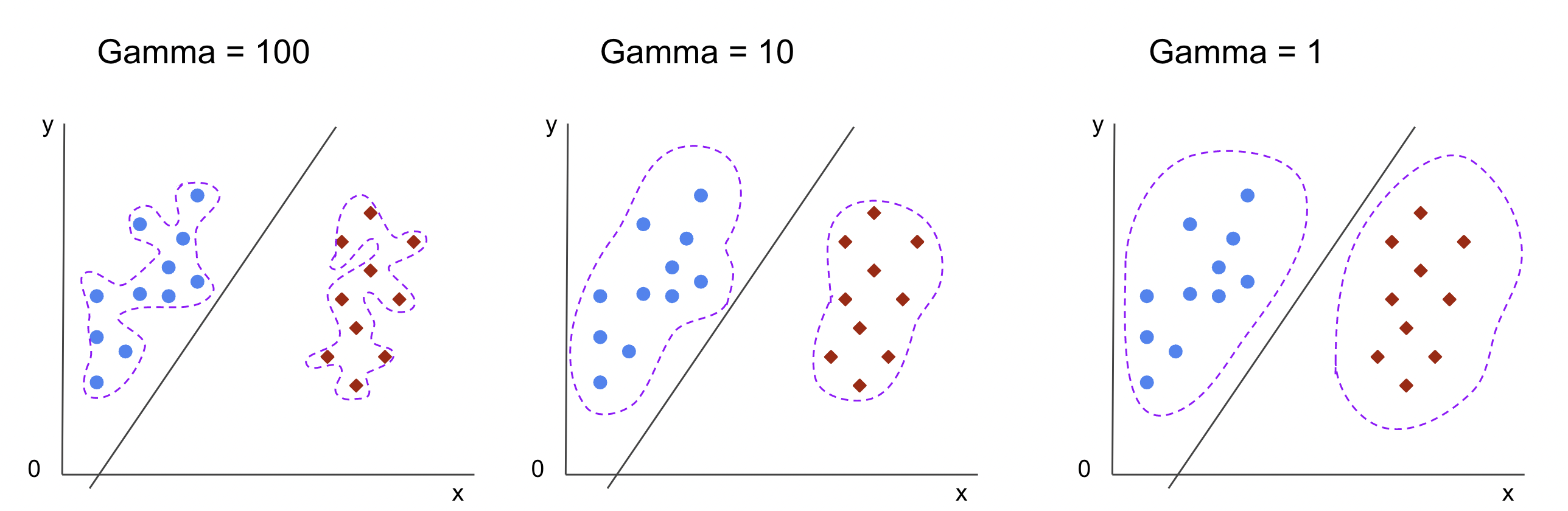
One other influence of gamma, is that the upper its worth, the extra the scope of the choice boundary will get nearer to the factors round it, making it extra jagged and vulnerable to overfit – and the bottom its worth, the smoother and common the choice boundary floor will get, additionally, much less vulnerable to overfit. That is true for any hyperplane, however will be simpler noticed when separating knowledge in increased dimensions. In some documentations, gamma can be known as sigma.
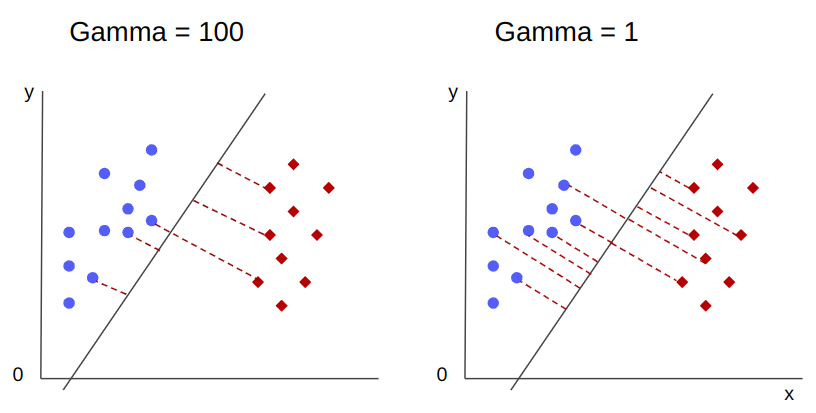
Within the case of our mannequin, the default worth of gamma was scale. As it may be seen within the Scikit-learn SVC documentation, it implies that its worth is:
$$
gamma = (1/ textual content{n_features} * X.var())
$$
or
$$
gamma = (1/ textual content{number_of_features} * textual content{features_variance})
$$
In our case, we have to calculate the variance of X_train, multiply it by 4 and divide the outcome by 1. We will do that with the next code:
number_of_features = X_train.form[1]
features_variance = X_train.values.var()
gamma = 1/(number_of_features * features_variance)
print('gamma:', gamma)
This outputs:
gamma: 0.013924748072859962
There may be additionally one other manner to take a look at the worth of gamma, by accessing the classifier’s object gamma parameter with ._gamma:
svc._gamma
We will see that the gamma utilized in our classifier was low, so it additionally thought of farther away factors.
Be aware: As we now have seen, C and gamma are necessary for some definitions of the mannequin. One other hyperparameter, random_state, is commonly utilized in Scikit Be taught to ensure knowledge shuffling or a random seed for fashions, so we all the time have the identical outcomes, however this can be a little totally different for SVM’s. Significantly, the random_state solely has implications if one other hyperparameter, likelihood, is about to true. It is because it should shuffle the info for acquiring likelihood estimates. If we do not need likelihood estimates for our lessons and likelihood is about to false, SVM’s random_state parameter has no implications on the mannequin outcomes.
There isn’t a rule on how to decide on values for hyperparameters, similar to C and gamma – it should rely on how lengthy and what assets can be found for experimenting with totally different hyperparameter values, what transformations will be made to the info, and what outcomes are anticipated. The standard option to seek for the hyperparameter values is by combining every of the proposed values by means of a grid search together with a process that applies these hyperparameter values and obtains metrics for various elements of the info known as cross validation. In Scikit-learn, that is already applied because the GridSearchCV (CV from cross validation) technique.
To run a grid search with cross validation, we have to import the GridSearchCV, outline a dictionary with the values of hyperparameters that will probably be experimented with, similar to the kind of kernel, the vary for C, and for gamma, create an occasion of the SVC, outline the rating or metric will probably be used for evaluating (right here we’ll selected to optimize for each precision and recall, so we’ll use f1-score), the variety of divisions that will probably be made within the knowledge for operating the search in cv – the default is 5, however it’s a good apply to make use of no less than 10 – right here, we’ll use 5 knowledge folds to make it clearer when evaluating outcomes.
The GridSearchCV has a match technique that receives our practice knowledge and additional splits it in practice and check units for the cross validation. We will set return_train_score to true to check the outcomes and assure there isn’t any overfit.
That is the code for the grid search with cross validation:
from sklearn.model_selection import GridSearchCV
parameters_dictionary = {'kernel':['linear', 'rbf'],
'C':[0.0001, 1, 10],
'gamma':[1, 10, 100]}
svc = SVC()
grid_search = GridSearchCV(svc,
parameters_dictionary,
scoring = 'f1',
return_train_score=True,
cv = 5,
verbose = 1)
grid_search.match(X_train, y_train)
This code outputs:
Becoming 5 folds for every of 18 candidates, totalling 90 suits
# and a clickable GridSeachCV object schema
After doing the hyperparameter search, we will use the best_estimator_, best_params_ and best_score_ properties to acquire the most effective mannequin, parameter values and highest f1-score:
best_model = grid_search.best_estimator_
best_parameters = grid_search.best_params_
best_f1 = grid_search.best_score_
print('The most effective mannequin was:', best_model)
print('The most effective parameter values have been:', best_parameters)
print('The most effective f1-score was:', best_f1)
This ends in:
The most effective mannequin was: SVC(C=1, gamma=1)
The most effective parameter values have been: {'C': 1, 'gamma': 1, 'kernel': 'rbf'}
The most effective f1-score was: 0.9979166666666666
Confirming our preliminary guess from trying on the knowledge, the most effective mannequin does not have a linear kernel, however a nonlinear one, RBF.
Recommendation: when additional investigating, it’s fascinating that you simply embrace extra non-linear kernels within the grid search.
Each C and gamma have the worth of 1, and the f1-score could be very excessive, 0.99. For the reason that worth is excessive, let’s have a look at if there was an overfit by peeking on the imply check and practice scores we now have returned, contained in the cv_results_ object:
gs_mean_test_scores = grid_search.cv_results_['mean_test_score']
gs_mean_train_scores = grid_search.cv_results_['mean_train_score']
print("The imply check f1-scores have been:", gs_mean_test_scores)
print("The imply practice f1-scores have been:", gs_mean_train_scores)
The imply scores have been:
The imply check f1-scores have been:
[0.78017291 0. 0.78017291 0. 0.78017291 0.
0.98865407 0.99791667 0.98865407 0.76553515 0.98865407 0.040291
0.98656 0.99791667 0.98656 0.79182565 0.98656 0.09443985]
The imply practice f1-scores have been:
[0.78443424 0. 0.78443424 0. 0.78443424 0.
0.98762683 1. 0.98762683 1. 0.98762683 1.
0.98942923 1. 0.98942923 1. 0.98942923 1. ]
By trying on the imply scores, we will see that the best one, 0.99791667 seems twice, and in each instances, the rating in practice knowledge was 1. This means the overfit persists. From right here, it could be fascinating to return to the info preparation and perceive if it is sensible to normalize the info, make another kind of knowledge transformation, and in addition create new options with characteristic engineering.
We have now simply seen a way to seek out the mannequin hyperparameters, and we now have already talked about one thing about linear separability, help vectors, determination boundary, maximization of margins, and kernel trick. SVM is a fancy algorithm, often with lots of mathematical ideas concerned and small tweakable elements that should be adjusted to come back collectively as a complete.
Let’s mix what we now have seen thus far, make a recap on how all of the elements of SVM work, after which check out a few of the different kernel implementations together with their outcomes.
Conclusion
On this article we understood concerning the default parameters behind Scikit-Be taught’s SVM implementation. We understood what C and Gamma parameters are, and the way altering every one among them can influence the SVM mannequin.
We additionally realized about grid search to search for the most effective C and Gamma values, and to make use of cross validation to raised generalize our outcomes and assure that there is not some type of knowledge leakage.
Performing a hyperparameter tuning with grid search and cross validation is a standard apply in knowledge science, so I strongly recommend you implement the strategies, run the code and see the hyperlinks between the hyperparameter values and the modifications in SVM predictions.

{kind=link}