
One of many main advantages of GraphQL is that you may question for all the info you want by means of one schema. This may increasingly assume that almost all methods are one large monolithic service. Nevertheless, because the schema grows, it might should be cut up into smaller schemas to be maintainable. Additionally, with the recognition of the microservice structure, many methods are made up of smaller providers which are chargeable for the info they supply.
In such instances, there’s a want to offer a unified GraphQL schema that shoppers can question. In any other case, we’ll return to a drawback of the standard API requests, the place it’s essential question a number of APIs to get the info you want.
That is the place schema stitching is available in. Schema stitching permits us to mix a number of graphs right into a single graph that knowledge may be fetched from.
On this article, we’ll use a sensible instance to debate schema stitching, the way it works below the hood, and how you can merge sorts throughout a number of schemas.
What’s schema stitching?
Schema stitching combines a number of subschemas and creates a mixed proxy layer referred to as gateway {that a} consumer can use to make requests. This implies that you may mix smaller GraphQL schemas from completely different modules and even completely different distant providers into one schema referred to as the gateway.
When a request comes from a consumer to the gateway, the gateway delegates the request to the subschema(s) that’s chargeable for offering the fields requested.
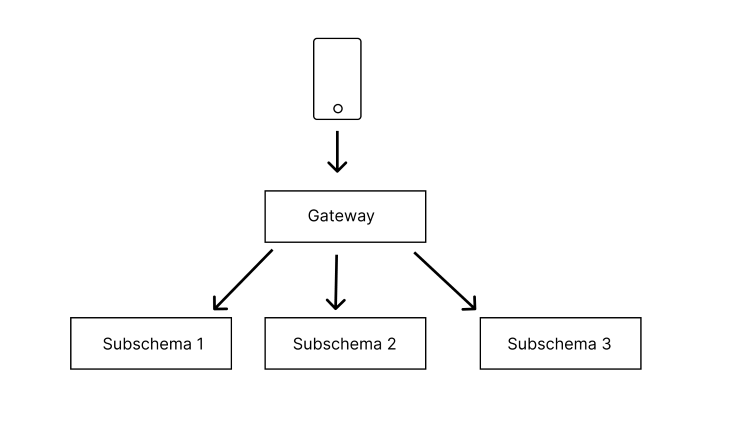
How does the gateway know which subschema to delegate a request to? When a request is available in to the gateway, the gateway seems up the stitched schema configuration to know which subschema(s) is chargeable for resolving the requested fields and delegates the request to the subschema.
It then combines the assorted resolved fields gotten from the schemas and sends them to the consumer. The consumer is mostly not conscious of what goes on when a request is made.
A lot of the advantages of schema stitching are on the backend. Massive graphs may be cut up into smaller graphs, and every group is chargeable for sustaining their schema and the fields they resolve with out impacting the builders engaged on different graphs.
Now, allow us to use an instance for a way schema stitching works in motion. To observe alongside, you would want a fundamental information of GraphQL and a information of JavaScript.
Challenge overview and setup
Since our focus is on schema stitching, we’ll be utilizing a starter venture. On this venture, we have now two subgraphs with their schemas and one folder for the gateway service. We’ll see how we will sew a schema to the gateway that’s in a unique module. Preserving in thoughts that almost all occasions microservices normally have their subschemas working in numerous servers, we will even see how we will sew a distant schema to the gateway. We’ll additionally take a look at how you can merge sorts which have their partial definitions present in numerous subschemas.
Let’s get began:
First, clone the venture right here.
That is the general venture construction and the vital information we shall be making use of on this article:
schema-stitching
- begin // the place we shall be making most adjustments
- gateway
- index.js // the place the schema stitching takes locations
- guide
- guide.graphql
- resolvers.js
- index.js
- datasources
- books.json // mocked knowledge for books
- BooksAPI.js
- overview
- overview.graphql
- resolvers.js
- datasources
- opinions.json // mocked opinions
- ReviewsAPI.js
- last // Discover the whole venture right here which you may make reference to
Subsequent, let’s set up the dependencies for gateway. Within the begin listing, run the next instructions:
cd begin/gateway npm set up
Let’s construct our gateway server and see schema stitching in motion. We’ll be doing this within the index.js file discovered within the gateway folder. That is how the bare-bones file seems now. It’s only a fundamental GraphQL node server with none schema:
const { createServer } = require( '@graphql-yoga/node');
async operate foremost() {
const server = createServer({
})
await server.begin()
}
foremost().catch(error => console.error(error))
Subsequent, let’s add our opinions subschema to the gateway server. First, we import the strategies we have to create the opinions subschema:
const { loadSchema } = require('@graphql-tools/load');
const { GraphQLFileLoader } = require('@graphql-tools/graphql-file-loader');
const { addResolversToSchema } = require('@graphql-tools/schema');
const { stitchSchemas } = require('@graphql-tools/sew');
Because the opinions schema is from a unique supply, we’d like these loadSchema and GraphQLFileLoader to load it. The stitchSchemas methodology is what we’ll use to sew our schemas collectively. We additionally must import our opinions resolver file and its knowledge supply file:
const ReviewsAPI = require("./../overview/datasources/ReviewsAPI");
const reviewsResolvers = require('./../overview/resolvers.js');
Subsequent, we create the subschema inside the principle operate:
async operate foremost() {
const reviewsSchema = await loadSchema('./../overview/opinions.graphql', {
loaders: [new GraphQLFileLoader()]
}
)
const reviewsSchemaWithResolvers = addResolversToSchema({
schema: reviewsSchema,
resolvers: reviewsResolvers
})
const reviewsSubschema = { schema: reviewsSchemaWithResolvers };
We’ll now create our gateway schema with the reviewsSubschema and sew it to our foremost gateway schema:
// construct the mixed schema
const gatewaySchema = stitchSchemas({
subschemas: [
reviewsSubschema
]
});
const server = createServer({
context: () => {
return {
dataSources: {
reviewsAPI: new ReviewsAPI()
}
}
},
schema: gatewaySchema,
port: 4003
})
So our file ought to appear to be this:
const { stitchSchemas } = require('@graphql-tools/sew');
const { loadSchema } = require('@graphql-tools/load');
const { GraphQLFileLoader } = require('@graphql-tools/graphql-file-loader');
const { addResolversToSchema } = require('@graphql-tools/schema');
const { createServer } = require( '@graphql-yoga/node');
const ReviewsAPI = require("./../overview/datasources/ReviewsAPI");
const reviewsResolvers = require('./../overview/resolvers.js');
async operate foremost() {
const reviewsSchema = await loadSchema('./../overview/opinions.graphql', {
loaders: [new GraphQLFileLoader()]
}
)
const reviewsSchemaWithResolvers = addResolversToSchema({
schema: reviewsSchema,
resolvers: reviewsResolvers
})
const reviewsSubschema = { schema: reviewsSchemaWithResolvers };
// construct the mixed schema
const gatewaySchema = stitchSchemas({
subschemas: [
reviewsSubschema
]
});
const server = createServer({
context: () => {
return {
dataSources: {
reviewsAPI: new ReviewsAPI()
}
}
},
schema: gatewaySchema,
port: 4003
})
await server.begin()
}
foremost().catch(error => console.error(error))
Let’s begin this server with npm begin and attempt to question some overview fields. Click on on the hyperlink for the server and run the next question:
question {
opinions {
bookIsbn
remark
score
}
}
It’s best to see a listing of opinions with the requested fields.
Now we have now seen how we will sew a schema in a unique module. However as talked about, this isn’t all the time the case. Most occasions, we have now to sew distant GraphQL schemas. So we’ll use the guide subschema to indicate how we will sew distant GraphQL schemas.
Stitching distant subschemas
Let’s begin the GraphQL server for the guide subschema. The index.js file already incorporates code to begin the server:
cd ../guide npm set up npm begin
The server needs to be working at http://0.0.0.0:4002/graphql.
To sew distant schemas, we’d like a nonexecutable schema and an executor.
The schema may be gotten by means of introspection or gotten as a flat SDL string from the server or repo. In our case, we’ll use introspection. Introspection allows you to question a GraphQL server for details about its schema. So with introspection, you’ll find out in regards to the sorts, fields, queries, and mutations. However be aware that not all schemas allow introspection. In that case, you may fall again to utilizing the flat SDL.
The executor is an easy generic methodology that performs requests to the distant schema.
Let’s do that for the working guide GraphQL server. We’ll return to the index.js file within the gateway listing.
Let’s import the required dependencies:
const { introspectSchema } = require('@graphql-tools/wrap');
const { fetch } = require('cross-undici-fetch')
const { print } = require('graphql')
Subsequent, we’ll add the executor for the books schema:
async operate remoteExecutor({ doc, variables }) {
const question = print(doc)
const fetchResult = await fetch('http://0.0.0.0:4002/graphql', {
methodology: 'POST',
headers: { 'Content material-Sort': 'utility/json' },
physique: JSON.stringify({ question, variables })
})
return fetchResult.json()
}
The GraphQL endpoint is hardcoded right here. However if you’re to make use of this for a number of distant schemas, you’ll need to make the executor extra generic.
Lastly, let’s construct our schema and add it to the gateway schema:
const booksSubschema = {
schema: await introspectSchema(remoteExecutor),
executor: remoteExecutor,
};
const gatewaySchema = stitchSchemas({
subschemas: [booksSubschema, reviewsSubschema],
});
In a unique terminal, begin your gateway server whether it is stopped and question for the next utilizing the server hyperlink supplied:
question{
opinions {
bookIsbn
remark
score
}
books {
isbn
title
}
}
It’s best to get each opinions and books.
Nice! We have now seen how schemas may be stitched to a gateway. Now, allow us to think about how you can merge sorts which are outlined in a number of schemas.
Sort merging for stitched schemas
In stitched schemas, it’s common for a sort to have fields which are supplied by a number of providers. In such instances, the gateway makes use of the stitched schema configuration to know which service resolves a specific subject. We’ll use an instance to elucidate the way it works.
Allow us to prolong the Overview kind to incorporate details about the Guide. So within the opinions.graphql file discovered within the opinions service, we add the guide subject to the overview and outline the Guide kind:
kind Overview {
id: Int!
bookIsbn: String!
score: Int!
remark: String
guide: Guide!
}
kind Guide {
isbn: String
}
It is a unidirectional kind relationship, which suggests the opinions service doesn’t present any distinctive subject for the Guide kind. So on this case, we solely want so as to add a merge configuration to the Guide subschema because it gives all of the distinctive fields for the Guide kind. All we have to do is to make sure that the keyfield isbn, which is required to resolve the Guide kind, is accurately supplied. We’ll do this by including a resolver that returns the isbn of the guide.
Within the resolvers.js file within the opinions service, we add the resolver for the guide subject:
const resolvers = {
Question: {
opinions(_, __, { dataSources }) {
return dataSources.reviewsAPI.getAllReviews();
},
reviewsForBook(_, { isbn }, { dataSources }) {
const opinions = dataSources.reviewsAPI.getReviewsForBook(isbn);
return { isbn, opinions };
},
},
Overview: {
guide: (overview) => {
return { isbn: overview.bookIsbn };
},
},
};
module.exports = resolvers;
Subsequent, we have to add a merge configuration for the guide subschema within the gateway. That is mandatory since we have now the Guide kind outlined in a number of schemas. Replace the booksSubschema to the next:
const booksSubschema = {
schema: await introspectSchema(remoteExecutor),
executor: remoteExecutor,
merge: {
Guide: {
selectionSet: "{ isbn }",
fieldName: "guide",
args: ({ isbn }) => ({ isbn }),
},
},
};
That is all we have to do for this unidirectional kind merging; we don’t want so as to add the merge configuration to the Critiques subschema because it doesn’t present any distinctive subject. If you’re confused in regards to the properties wanted for the merge config, maintain on — it will likely be defined shortly.
In case you run the next question:
{
opinions {
id
score
remark
guide {
creator
}
}
}
It’s best to get:
{
"knowledge": {
"opinions": [
{
"id": 1,
"rating": 4,
"comment": "A great introduction to Javascript",
"book": {
"author": "Marijn Haverbeke"
}
},
If you want to know more about how the gateway resolves these fields, you can refer to the merging flow documentation.
That was a simple example of type merging. However, in many cases, unique fields are provided by multiple services. For instance, we may want to be able to get all reviews for a particular book and the reviews service will be responsible for resolving that field. In such a case, we’ll need to add a merge configuration to the gateway service to enable it to resolve these fields. Let’s do that.
First, we add the reviews field to the Book type defined in reviews.graphql:
type Book {
isbn: String
reviews: [Review]
}
We’ll additionally add a question that accepts an ISBN and returns the Guide kind. We’ll use this in our merge configuration as the sphere identify wanted to resolve the added fields for the Guide kind:
kind Question {
opinions: [Review!]!
reviewsForBook(isbn: String): Guide
}
Subsequent, let’s add its resolver:
const resolvers = {
Question: {
opinions(_, __, { dataSources }) {
return dataSources.reviewsAPI.getAllReviews();
},
reviewsForBook(_, { isbn }, { dataSources }) {
const opinions = dataSources.reviewsAPI.getReviewsForBook(isbn);
return { isbn, opinions };
},
},
Subsequent, we’ll add the merge configuration to the gateway service. So within the index.js file within the gateway listing, we add the merge configuration to the reviewsSubschema definition:
const reviewsSubschema = {
schema: reviewsSchemaWithResolvers,
merge: {
Guide: {
selectionSet: "{ isbn }",
fieldName: "reviewsForBook",
args: ({ isbn }) => ({ isbn }),
}
}
};
Within the merge configuration, we specified that the fields of the Guide kind shall be resolved by the reviewsForBook, which is the fieldName outlined right here. That is the top-level question to seek the advice of for resolving the Guide fields outlined within the Critiques subschema.
The selectionSet signifies the fields that should be chosen from the Guide object to get the arguments wanted for reviewsForBook.
args transforms the selectionSet into the arguments that’s utilized by reviewsForBook. That is helpful if we need to do any transformation to the selectionSet earlier than it’s handed to the fieldName.
Now, let’s get the opinions for a guide with this question:
{
guide(isbn: "9781491943533") {
isbn
creator
opinions {
remark
score
}
}
}
It’s best to get this:
{
"knowledge": {
"guide": {
"isbn": "9781491943533",
"creator": "Nicolás Bevacqua",
"opinions": [
{
"comment": "Dive into ES6 and the Future of JavaScript",
"rating": 5
}
]
}
}
}
Abstract
On this tutorial, we have now mentioned what schema stitching is, why schema stitching is important, and we used a sensible instance to see how we will sew schemas from a unique module and a distant schema working in a unique server. We additionally noticed how one can merge sorts outlined in a number of subschemas. For a extra detailed rationalization of kind merging, you may seek advice from the documentation for it.
We will see that schema stitching may be very helpful for giant methods made up of smaller providers. It additionally helps groups to keep up their schemas unbiased of different builders in different groups.
One other in style manner of mixing a number of subschemas is Apollo Federation. You’ll be able to learn this text to learn how it differs from schema stitching.
Monitor failed and sluggish GraphQL requests in manufacturing
Whereas GraphQL has some options for debugging requests and responses, ensuring GraphQL reliably serves sources to your manufacturing app is the place issues get harder. In case you’re occupied with making certain community requests to the backend or third get together providers are profitable, strive LogRocket.
 https://logrocket.com/signup/
https://logrocket.com/signup/
LogRocket is sort of a DVR for internet and cell apps, recording actually the whole lot that occurs in your web site. As an alternative of guessing why issues occur, you may combination and report on problematic GraphQL requests to shortly perceive the basis trigger. As well as, you may monitor Apollo consumer state and examine GraphQL queries’ key-value pairs.
LogRocket devices your app to file baseline efficiency timings resembling web page load time, time to first byte, sluggish community requests, and in addition logs Redux, NgRx, and Vuex actions/state. Begin monitoring totally free.

{kind=link}