Random Forest is without doubt one of the hottest bagging strategies. What’s bagging you ask? It’s an abbreviation for bootstrapping + aggregating. The purpose of bagging is to cut back the variance of a single estimator, i.e. the variance of a single Choice Tree within the case of Random Forest.
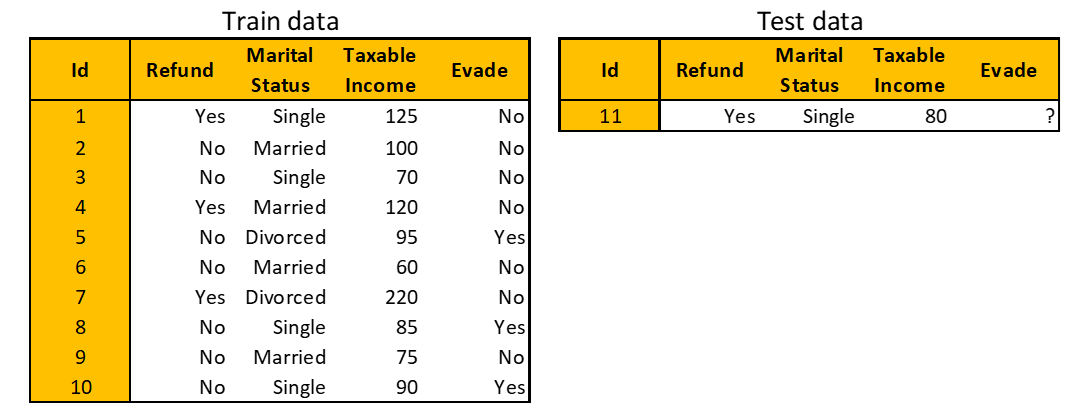
To be concrete, let’s use a dummy dataset all through this story. Suppose you will have the next tax evasion dataset. Your job is to foretell whether or not an individual will comply to pay taxes (the Evade column) based mostly on options like Taxable Earnings (in thousand {dollars}), Marital Standing, and whether or not a Refund is carried out or not.
Random Forest consists of those three steps:
Step 1. Create a bootstrapped knowledge
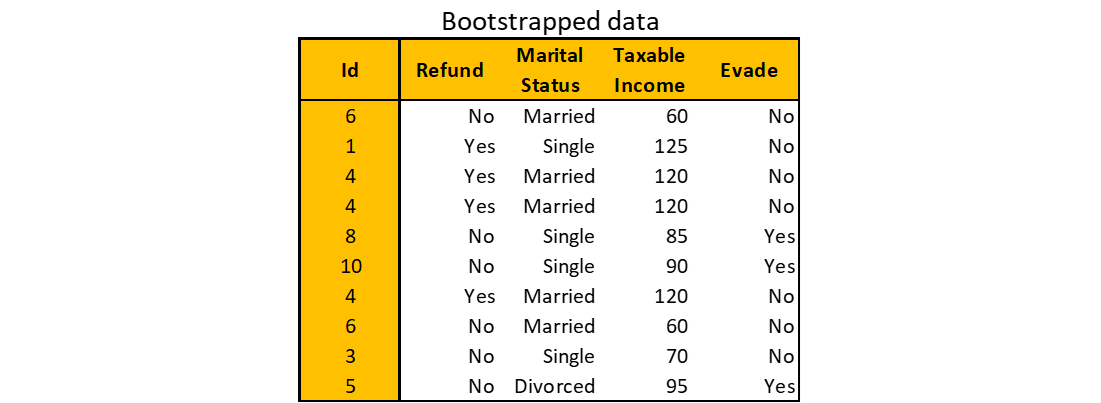
Given an authentic practice knowledge with m observations and n options, pattern m observations randomly with repetition. The key phrase right here is “with repetition”. This implies it’s most probably that some observations are picked greater than as soon as.
Beneath is an instance of bootstrapped knowledge from the unique practice knowledge above. You might need completely different bootstrapped knowledge attributable to randomness.
Step 2. Construct a Choice Tree
The choice tree is constructed:
- utilizing the bootstrapped knowledge, and
- contemplating a random subset of options at every node (the variety of options thought of is often the sq. root of n).
Step 3. Repeat
Step 1 and Step 2 are iterated many instances. For instance, utilizing the tax evasion dataset with six iterations, you’ll get the next Random Forest.
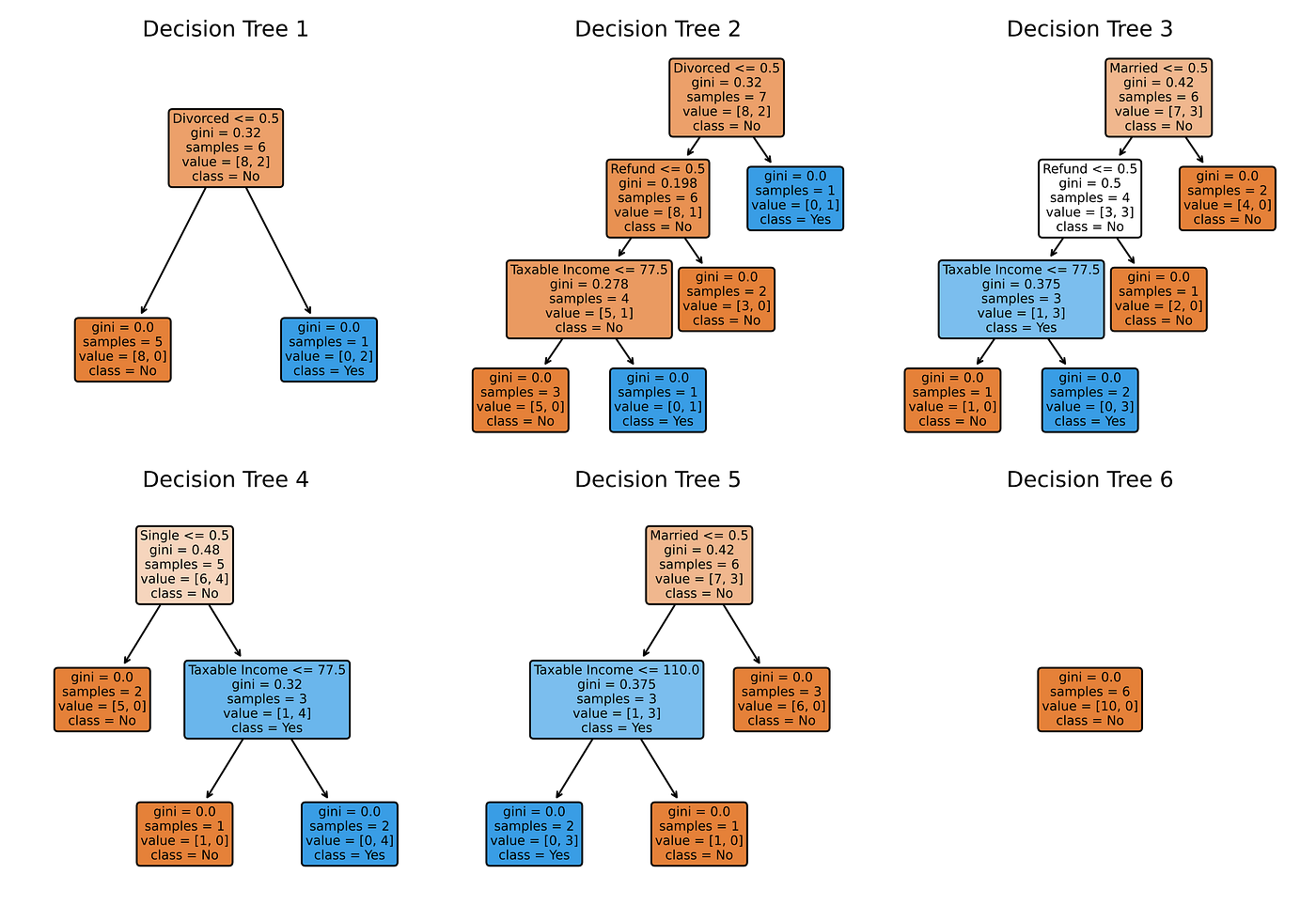
Be aware that Random Forest isn’t deterministic since there’s a random choice of observations and options at play. These random picks are why Random Forest reduces the variance of a Choice Tree.
Predict, combination, and consider
To make predictions utilizing Random Forest, traverse every Choice Tree utilizing the take a look at knowledge. For our instance, there’s just one take a look at commentary on which six Choice Timber respectively give predictions No, No, No, Sure, Sure, and No for the “Evade” goal. Do majority voting from these six predictions to make a single Random Forest prediction: No.
Combining predictions of Choice Timber right into a single prediction of Random Forest is named aggregating. Whereas majority voting is used for classification issues, the aggregating technique for regression issues makes use of the imply or median of all Choice Tree predictions as a single Random Forest prediction.
The creation of bootstrapped knowledge permits some practice observations to be unseen by a subset of Choice Timber. These observations are referred to as out-of-bag samples and are helpful for evaluating the efficiency of Random Forest. To acquire validation accuracy (or any metric of your alternative) of Random Forest:
- run out-of-bag samples via all Choice Timber that had been constructed with out them,
- combination the predictions, and
- examine the aggregated predictions with the true labels.
In contrast to Random Forest, AdaBoost (Adaptive Boosting) is a boosting ensemble technique the place easy Choice Timber are constructed sequentially. How easy? The timber encompass solely a root and two leaves, so easy that they’ve their very own title: Choice Stumps. Listed here are two most important variations between Random Forest and AdaBoost:
- Choice Timber in Random Forest have equal contributions to the ultimate prediction, whereas Choice Stumps in AdaBoost have completely different contributions, i.e. some stumps have extra say than others.
- Choice Timber in Random Forest are constructed independently, whereas every Choice Stump in AdaBoost is made by taking the earlier stump’s mistake into consideration.
Choice Stumps are too easy; they’re barely higher than random guessing and have a excessive bias. The purpose of boosting is to cut back the bias of a single estimator, i.e. the bias of a single Choice Stump within the case of AdaBoost.
Recall the tax evasion dataset. You’ll use AdaBoost to foretell whether or not an individual will comply to pay taxes based mostly on three options: Taxable Earnings, Marital Standing, and Refund.
Step 1. Initialize pattern weight and construct a Choice Stump
Do not forget that a Choice Stump in AdaBoost is made by taking the earlier stump’s mistake into consideration. To try this, AdaBoost assigns a pattern weight to every practice commentary. Larger weights are assigned to misclassified observations by the present stump, informing the following stump to pay extra consideration to these misclassified observations.
Initially, since there aren’t any predictions made but, all observations are given the identical weight of 1/m. Then, a Choice Stump is constructed identical to making a Choice Tree with depth 1.
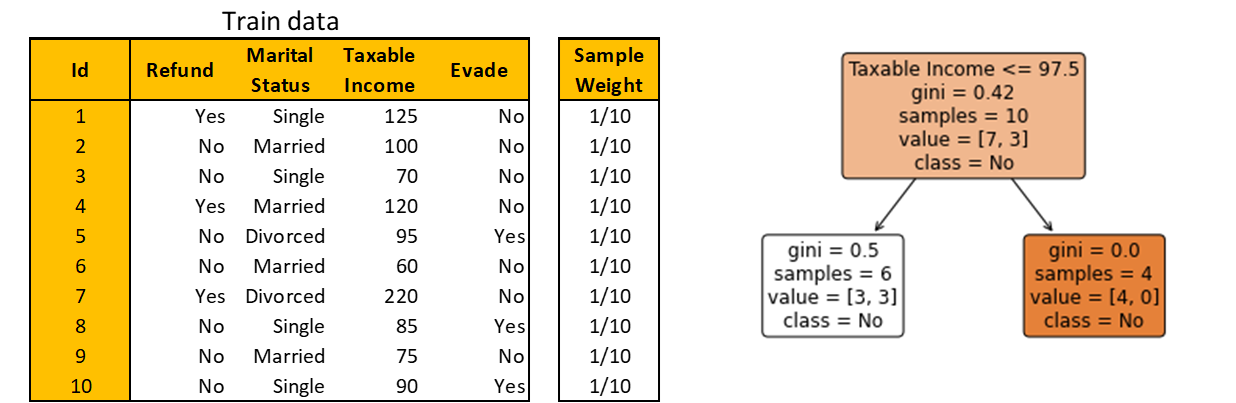
Step 2. Calculate the quantity of say for the Choice Stump
This Choice Stump yields 3 misclassified observations. Since all observations have the identical pattern weight, the whole error when it comes to pattern weight is 1/10 + 1/10 + 1/10 = 0.3.
The quantity of say can then be calculated utilizing the system
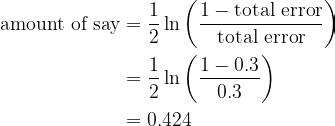
To grasp why the system is smart, let’s plot the quantity of say vs whole error. Be aware that whole error is simply outlined on the interval [0, 1].
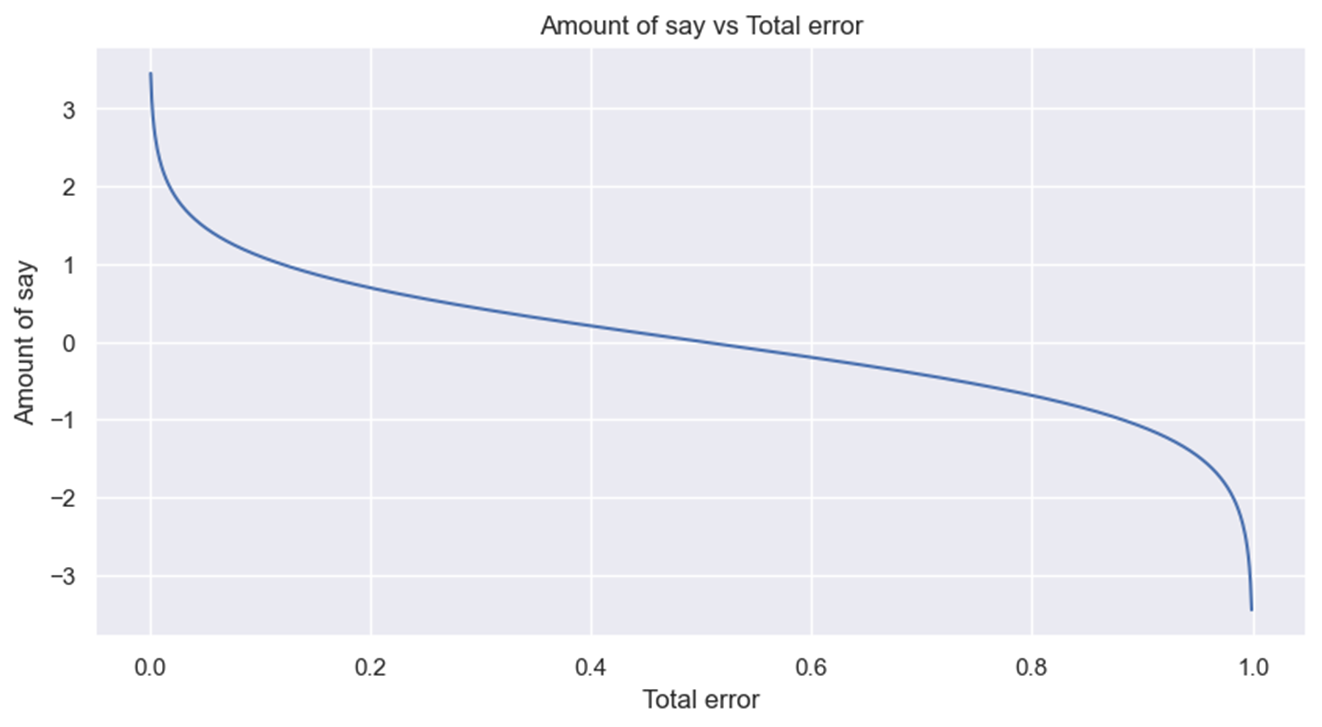
If the whole error is near 0, the quantity of say is an enormous constructive quantity, indicating the stump offers many contributions to the ultimate prediction. However, if the whole error is near 1, the quantity of say is an enormous detrimental quantity, giving a lot penalty for the misclassification the stump produces. If the whole error is 0.5, the stump doesn’t do something for the ultimate prediction.
Step 3. Replace pattern weight
AdaBoost will enhance the weights of incorrectly labeled observations and reduce the weights of accurately labeled observations. The brand new pattern weight influences the following Choice Stump: observations with bigger weights are paid extra consideration to.
To replace the pattern weight, use the system
- For incorrectly labeled observations:
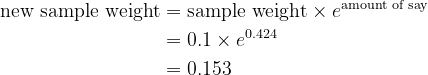
- For accurately labeled observations:
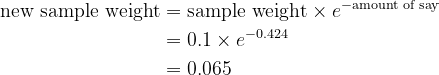
It is advisable normalize the brand new pattern weights such that their sum equals 1 earlier than persevering with to the following step, utilizing the system
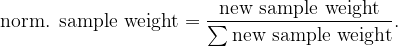
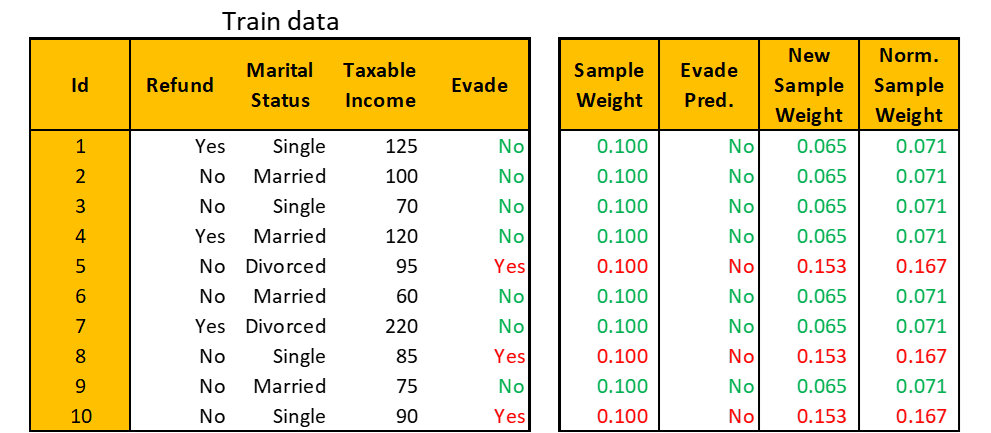
These calculations are summarized within the desk beneath. The inexperienced observations are accurately labeled and the purple ones are incorrectly labeled by the present stump.
Step 4. Repeat
A brand new Choice Stump is created utilizing the weighted impurity perform, i.e. weighted Gini Index, the place normalized pattern weight is taken into account in figuring out the proportion of observations per class. Alternatively, one other approach to create a Choice Stump is to make use of bootstrapped knowledge based mostly on normalized pattern weight.
Since normalized pattern weight has a sum of 1, it may be thought of as a likelihood {that a} specific commentary is picked when bootstrapping. So, observations with Ids 5, 8, and 10 are extra possible to be picked and therefore the Choice Stump is extra targeted on them.
The bootstrapped knowledge is proven beneath. Be aware that you could be get completely different bootstrapped knowledge attributable to randomness. Construct a Choice Stump as earlier than.
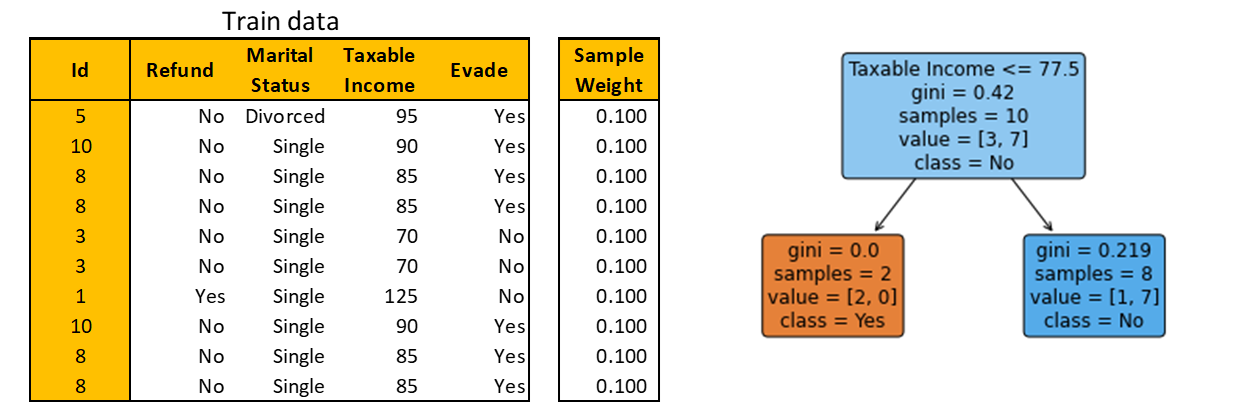
You see that there’s one misclassified commentary. So, the quantity of say is 1.099. Replace the pattern weight and normalize with respect to the sum of weights of solely bootstrapped observations. These calculations are summarized within the desk beneath.

The bootstrapped observations return to the pool of practice knowledge and the brand new pattern weight turns into as proven beneath. You may then bootstrap the practice knowledge once more utilizing the brand new pattern weight for the third Choice Stump and the method goes on.

Prediction
Let’s say you iterate the steps six instances. Thus, you will have six Choice Stumps. To make predictions, traverse every stump utilizing the take a look at knowledge and group the expected lessons. The group with the most important quantity of say represents the ultimate prediction of AdaBoost.
As an instance, the primary two Choice Stumps you constructed have the quantity of say 0.424 and 1.099, respectively. Each stumps predict Evade = No since for the taxable earnings, 77.5 < 80 ≤ 97.5 (80 is the worth of Taxable Earnings for the take a look at commentary). Let’s say the opposite 4 Choice Stumps predict and have the next quantity of say.
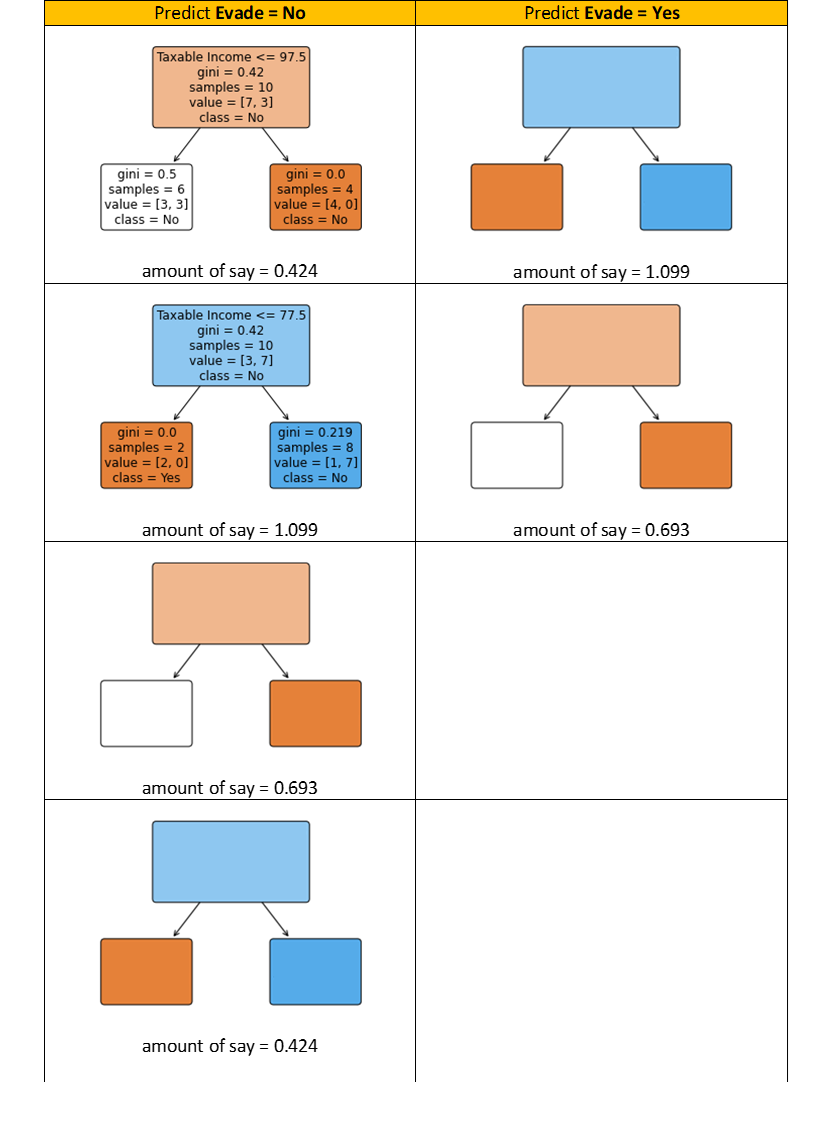
For the reason that sum of the quantity of say of all stumps that predict Evade = No is 2.639, greater than the sum of the quantity of say of all stumps that predict Evade = Sure (which is 1.792), then the ultimate AdaBoost prediction is Evade = No.
Since each are boosting strategies, AdaBoost and Gradient Boosting have the same workflow. There are two most important variations although:
- Gradient Boosting makes use of timber bigger than a Choice Stump. On this story, we restrict the timber to have a most of three leaf nodes, which is a hyperparameter that may be modified at will.
- As an alternative of utilizing pattern weight to information the following Choice Stump, Gradient Boosting makes use of the residual made by the Choice Tree to information the following tree.
Recall the tax evasion dataset. You’ll use Gradient Boosting to foretell whether or not an individual will comply to pay taxes based mostly on three options: Taxable Earnings, Marital Standing, and Refund.
Step 1. Initialize a root
A root is a Choice Tree with zero depth. It doesn’t contemplate any characteristic to do prediction: it makes use of Evade itself to foretell on Evade. How does it do that? Encode Evade utilizing the mapping No → 0 and Sure → 1. Then, take the common, which is 0.3. That is referred to as the prediction likelihood (the worth is at all times between 0 and 1) and is denoted by p.
Since 0.3 is lower than the brink of 0.5, the basis will predict No for each practice commentary. In different phrases, the prediction is at all times the mode of Evade. In fact, this can be a very dangerous preliminary prediction. To enhance the efficiency, you’ll be able to calculate the log(odds) for use within the subsequent step utilizing the system
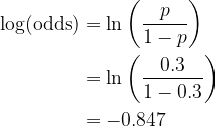
Step 2. Calculate the residual to suit a Choice Tree into
To simplify notations, let the encoded column of Evade be denoted by y. Residual is outlined just by r = y − p, the place p is the prediction likelihood calculated from the most recent log(odds) utilizing its inverse perform
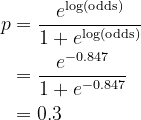
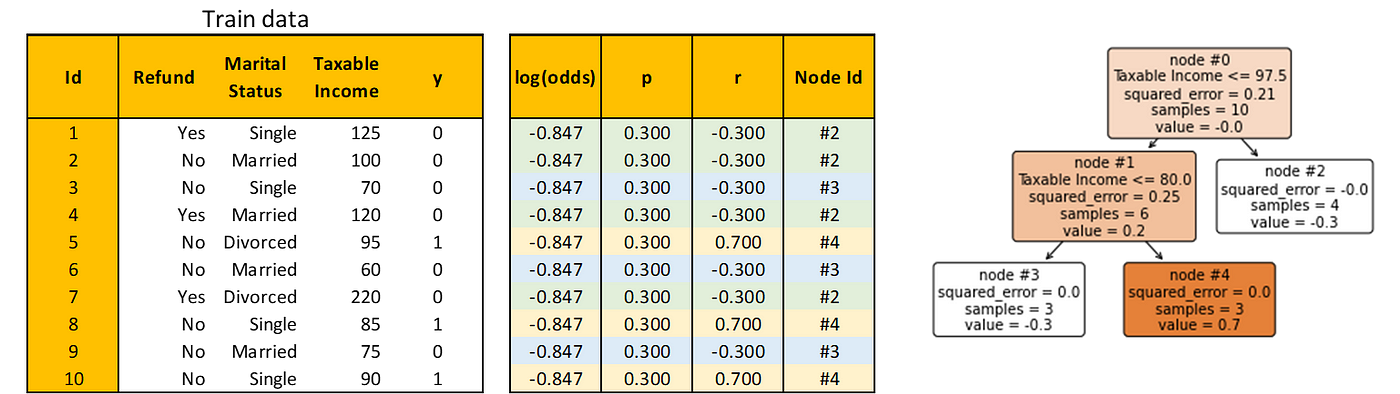
Construct a Choice Tree to foretell the residual utilizing all practice observations. Be aware that this can be a regression job.
Step 3. Replace log(odds)
Be aware that I additionally added a Node Id column that explains the index of the node within the Choice Tree the place every commentary is predicted. Within the desk above, every commentary is color-coded to simply see which commentary goes to which node.
To mix the predictions of the preliminary root and the Choice Tree you simply constructed, it is advisable remodel the expected values within the Choice Tree such that they match the log(odds) within the preliminary root.
For instance, let dᵢ denote the set of commentary Ids in node #i, i.e. d₂ = {1, 2, 4, 7}. Then the transformation for node #2 is
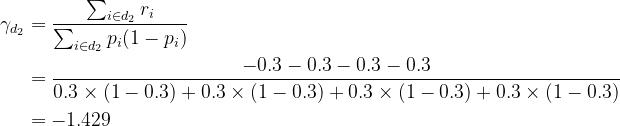
Do the identical calculation to node #3 and node #4, you get γ for all coaching observations as the next desk. Now you’ll be able to replace the log(odds) utilizing the system
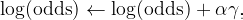
the place α is the training price of Gradient Boosting and is a hyperparameter. Let’s set α = 0.4, then the whole calculation of updating log(odds) may be seen beneath.
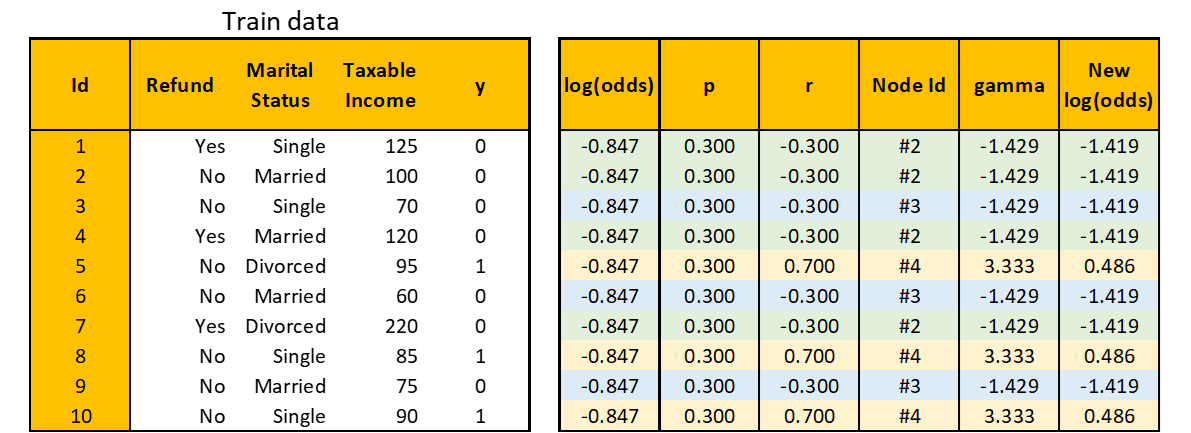
Step 4. Repeat
Utilizing the brand new log(odds), repeat Step 2 and Step 3. Right here’s the brand new residual and the Choice Tree constructed to foretell it.
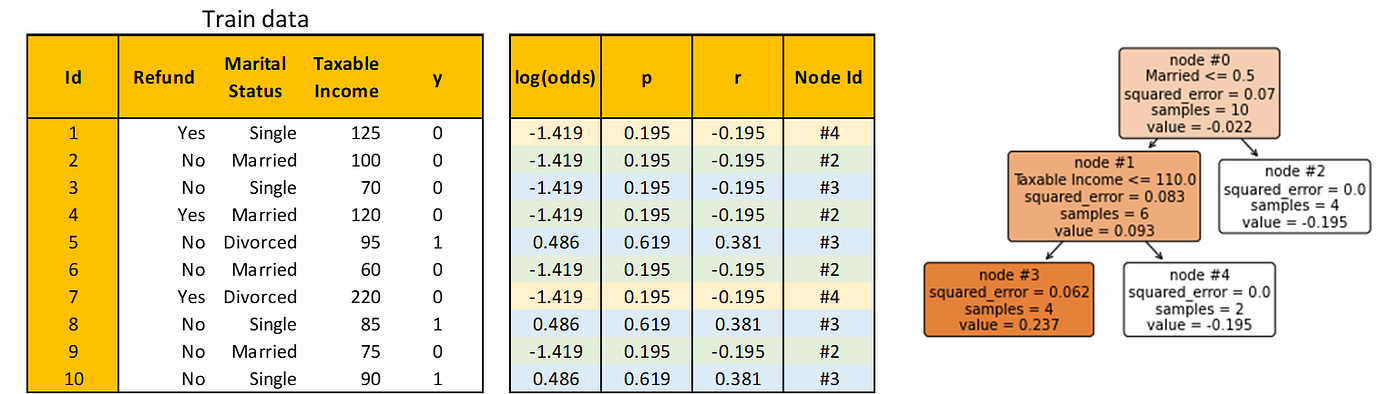
Calculate γ as earlier than. For instance, contemplate node #3, then
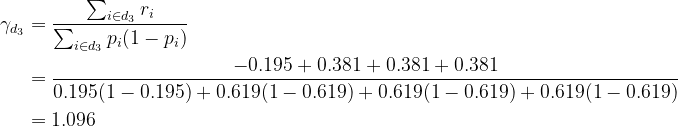
Utilizing γ, calculate the brand new log(odds) as earlier than. Right here’s the whole calculation

You may repeat the method as many instances as you want. For this story, nevertheless, to keep away from issues getting out of hand, we’ll cease the iteration now.
Prediction
To do prediction on take a look at knowledge, first, traverse every Choice Tree till reaching a leaf node. Then, add the log(odds) of the preliminary root with all of the γ of the corresponding leaf nodes scaled by the training price.
In our instance, the take a look at commentary lands on node #3 of each Choice Timber. Therefore, the summation turns into -0.847 + 0.4 × (-1.429 + 1.096) = -0.980. Convert to prediction likelihood
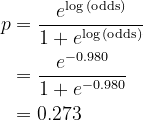
Since 0.273 < 0.5, predict Evade = No.
You’ve realized in nice element Random Forest, AdaBoost, and Gradient Boosting, and utilized them to a easy dummy dataset. Now, not solely you’ll be able to construct them utilizing established libraries, however you additionally confidently know the way they work from the within out, the most effective practices to make use of them, and enhance their efficiency.
Congrats!
 Thanks! When you get pleasure from this story and need to help me as a author, contemplate changing into a member. For less than $5 a month, you’ll get limitless entry to all tales on Medium. When you join utilizing my hyperlink, I’ll earn a small fee.
Thanks! When you get pleasure from this story and need to help me as a author, contemplate changing into a member. For less than $5 a month, you’ll get limitless entry to all tales on Medium. When you join utilizing my hyperlink, I’ll earn a small fee.
 Need to know extra about how gradient descent and plenty of different optimizers work? Proceed studying:
Need to know extra about how gradient descent and plenty of different optimizers work? Proceed studying:
