On this article, we are going to be taught to foretell the survival possibilities of the Titanic passengers utilizing the given details about their intercourse, age, and so on. As this can be a classification process we can be utilizing random forest.
There can be three important steps on this experiment:
- Function Engineering
- Imputation
- Coaching and Prediction
Dataset
The dataset for this experiment is freely obtainable on the Kaggle web site. Obtain the dataset from this hyperlink https://www.kaggle.com/competitions/titanic/information?choose=prepare.csv. As soon as the dataset is downloaded it’s divided into three CSV information gender submission.csv prepare.csv and take a look at.csv
Importing Libraries and Preliminary setup
Python3
import warnings
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.type.use('fivethirtyeight')
%matplotlib inline
warnings.filterwarnings('ignore')
|
Now let’s learn the coaching and take a look at information utilizing the pandas information body.
Python3
prepare = pd.read_csv('prepare.csv')
take a look at = pd.read_csv('take a look at.csv')
prepare.form
|
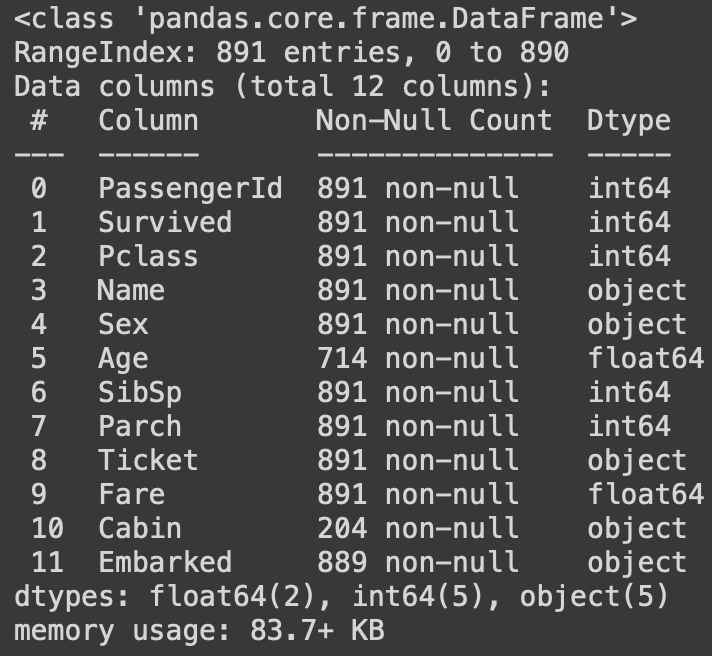
To know the details about every column like the information kind, and so on we use the df.data() operate.
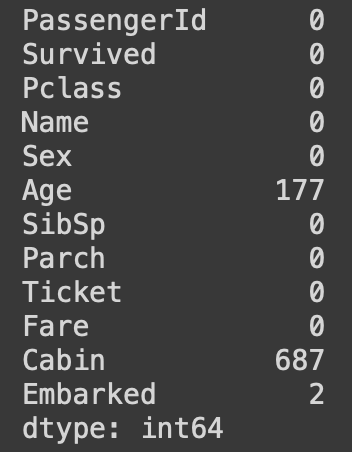
Now let’s see if there are any NULL values current within the dataset. This may be checked utilizing the isnull() operate. It yields the next output.
Visualization
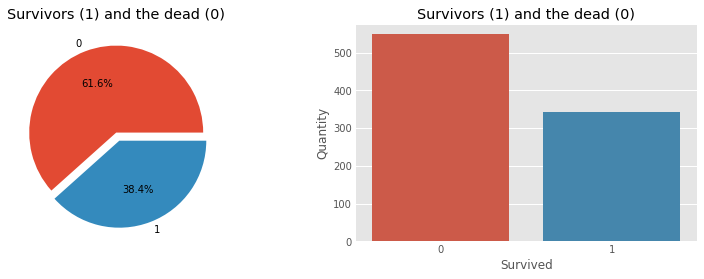
Now allow us to visualize the information utilizing some pie charts and histograms to get a correct understanding of the information.
Allow us to first visualize the variety of survivors and demise counts.
Python3
f, ax = plt.subplots(1, 2, figsize=(12, 4))
prepare['Survived'].value_counts().plot.pie(
explode=[0, 0.1], autopct='%1.1f%%', ax=ax[0], shadow=False)
ax[0].set_title('Survivors (1) and the useless (0)')
ax[0].set_ylabel('')
sns.countplot('Survived', information=prepare, ax=ax[1])
ax[1].set_ylabel('Amount')
ax[1].set_title('Survivors (1) and the useless (0)')
plt.present()
|
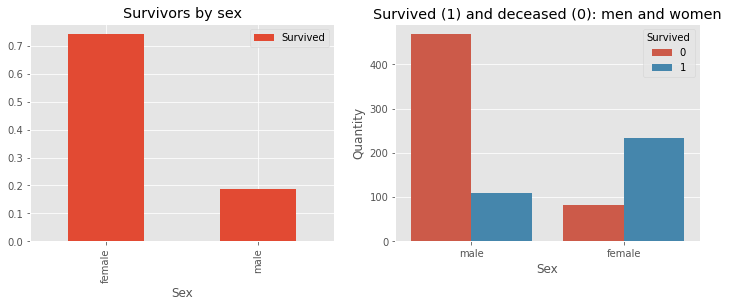
Intercourse characteristic
Python3
f, ax = plt.subplots(1, 2, figsize=(12, 4))
prepare[['Sex', 'Survived']].groupby(['Sex']).imply().plot.bar(ax=ax[0])
ax[0].set_title('Survivors by intercourse')
sns.countplot('Intercourse', hue='Survived', information=prepare, ax=ax[1])
ax[1].set_ylabel('Amount')
ax[1].set_title('Survived (1) and deceased (0): women and men')
plt.present()
|
Function Engineering
Now let’s see which columns ought to we drop and/or modify for the mannequin to foretell the testing information. The principle duties on this step is to drop pointless options and to transform string information into the numerical class for simpler coaching.
We’ll begin off by dropping the Cabin characteristic since not much more helpful data will be extracted from it. However we are going to make a brand new column from the Cabins column to see if there was cabin data allotted or not.
Python3
prepare["CabinBool"] = (prepare["Cabin"].notnull().astype('int'))
take a look at["CabinBool"] = (take a look at["Cabin"].notnull().astype('int'))
prepare = prepare.drop(['Cabin'], axis=1)
take a look at = take a look at.drop(['Cabin'], axis=1)
|
We will additionally drop the Ticket characteristic because it’s unlikely to yield any helpful data
Python3
prepare = prepare.drop(['Ticket'], axis=1)
take a look at = take a look at.drop(['Ticket'], axis=1)
|
There are lacking values within the Embarked characteristic. For that, we are going to change the NULL values with ‘S’ because the variety of Embarks for ‘S’ are larger than the opposite two.
Python3
prepare = prepare.fillna({"Embarked": "S"})
|
We are going to now kind the age into teams. We are going to mix the age teams of the individuals and categorize them into the identical teams. BY doing so we can be having fewer classes and may have a greater prediction since it will likely be a categorical dataset.
Python3
prepare["Age"] = prepare["Age"].fillna(-0.5)
take a look at["Age"] = take a look at["Age"].fillna(-0.5)
bins = [-1, 0, 5, 12, 18, 24, 35, 60, np.inf]
labels = ['Unknown', 'Baby', 'Child', 'Teenager',
'Student', 'Young Adult', 'Adult', 'Senior']
prepare['AgeGroup'] = pd.reduce(prepare["Age"], bins, labels=labels)
take a look at['AgeGroup'] = pd.reduce(take a look at["Age"], bins, labels=labels)
|
Within the ‘title’ column for each the take a look at and prepare set, we are going to categorize them into an equal variety of courses. Then we are going to assign numerical values to the title for comfort of mannequin coaching.
Python3
mix = [train, test]
for dataset in mix:
dataset['Title'] = dataset.Identify.str.extract(' ([A-Za-z]+).', develop=False)
pd.crosstab(prepare['Title'], prepare['Sex'])
for dataset in mix:
dataset['Title'] = dataset['Title'].change(['Lady', 'Capt', 'Col',
'Don', 'Dr', 'Major',
'Rev', 'Jonkheer', 'Dona'],
'Uncommon')
dataset['Title'] = dataset['Title'].change(
['Countess', 'Lady', 'Sir'], 'Royal')
dataset['Title'] = dataset['Title'].change('Mlle', 'Miss')
dataset['Title'] = dataset['Title'].change('Ms', 'Miss')
dataset['Title'] = dataset['Title'].change('Mme', 'Mrs')
prepare[['Title', 'Survived']].groupby(['Title'], as_index=False).imply()
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3,
"Grasp": 4, "Royal": 5, "Uncommon": 6}
for dataset in mix:
dataset['Title'] = dataset['Title'].map(title_mapping)
dataset['Title'] = dataset['Title'].fillna(0)
|
Now utilizing the title data we are able to fill within the lacking age values.
Python3
mr_age = prepare[train["Title"] == 1]["AgeGroup"].mode()
miss_age = prepare[train["Title"] == 2]["AgeGroup"].mode()
mrs_age = prepare[train["Title"] == 3]["AgeGroup"].mode()
master_age = prepare[train["Title"] == 4]["AgeGroup"].mode()
royal_age = prepare[train["Title"] == 5]["AgeGroup"].mode()
rare_age = prepare[train["Title"] == 6]["AgeGroup"].mode()
age_title_mapping = {1: "Younger Grownup", 2: "Scholar",
3: "Grownup", 4: "Child", 5: "Grownup", 6: "Grownup"}
for x in vary(len(prepare["AgeGroup"])):
if prepare["AgeGroup"][x] == "Unknown":
prepare["AgeGroup"][x] = age_title_mapping[train["Title"][x]]
for x in vary(len(take a look at["AgeGroup"])):
if take a look at["AgeGroup"][x] == "Unknown":
take a look at["AgeGroup"][x] = age_title_mapping[test["Title"][x]]
|
Now assign a numerical worth to every age class. As soon as we have now mapped the age into totally different classes we don’t want the age characteristic. Therefore drop it
Python3
age_mapping = {'Child': 1, 'Baby': 2, 'Teenager': 3,
'Scholar': 4, 'Younger Grownup': 5, 'Grownup': 6,
'Senior': 7}
prepare['AgeGroup'] = prepare['AgeGroup'].map(age_mapping)
take a look at['AgeGroup'] = take a look at['AgeGroup'].map(age_mapping)
prepare.head()
prepare = prepare.drop(['Age'], axis=1)
take a look at = take a look at.drop(['Age'], axis=1)
|
Drop the identify characteristic because it accommodates no extra helpful data.
Python3
prepare = prepare.drop(['Name'], axis=1)
take a look at = take a look at.drop(['Name'], axis=1)
|
Assign numerical values to intercourse and embarks classes
Python3
sex_mapping = {"male": 0, "feminine": 1}
prepare['Sex'] = prepare['Sex'].map(sex_mapping)
take a look at['Sex'] = take a look at['Sex'].map(sex_mapping)
embarked_mapping = {"S": 1, "C": 2, "Q": 3}
prepare['Embarked'] = prepare['Embarked'].map(embarked_mapping)
take a look at['Embarked'] = take a look at['Embarked'].map(embarked_mapping)
|
Fill within the lacking Fare worth within the take a look at set based mostly on the imply fare for that P-class
Python3
for x in vary(len(take a look at["Fare"])):
if pd.isnull(take a look at["Fare"][x]):
pclass = take a look at["Pclass"][x]
take a look at["Fare"][x] = spherical(
prepare[train["Pclass"] == pclass]["Fare"].imply(), 4)
prepare['FareBand'] = pd.qcut(prepare['Fare'], 4,
labels=[1, 2, 3, 4])
take a look at['FareBand'] = pd.qcut(take a look at['Fare'], 4,
labels=[1, 2, 3, 4])
prepare = prepare.drop(['Fare'], axis=1)
take a look at = take a look at.drop(['Fare'], axis=1)
|
Now we’re executed with the characteristic engineering
Mannequin Coaching
We can be utilizing Random forest because the algorithm of option to carry out mannequin coaching. Earlier than that, we are going to cut up the information in an 80:20 ratio as a train-test cut up. For that, we are going to use the train_test_split() from the sklearn library.
Python3
from sklearn.model_selection import train_test_split
predictors = prepare.drop(['Survived', 'PassengerId'], axis=1)
goal = prepare["Survived"]
x_train, x_val, y_train, y_val = train_test_split(
predictors, goal, test_size=0.2, random_state=0)
|
Now import the random forest operate from the ensemble module of sklearn and fir the coaching set.
Python3
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
randomforest = RandomForestClassifier()
randomforest.match(x_train, y_train)
y_pred = randomforest.predict(x_val)
acc_randomforest = spherical(accuracy_score(y_pred, y_val) * 100, 2)
print(acc_randomforest)
|
With this, we obtained an accuracy of 83.25%
Prediction
We’re supplied with the testing dataset on which we have now to carry out the prediction. To foretell, we are going to move the take a look at dataset into our educated mannequin and reserve it right into a CSV file containing the knowledge, passengerid and survival. PassengerId would be the passengerid of the passengers within the take a look at information and the survival will column can be both 0 or 1.
Python3
ids = take a look at['PassengerId']
predictions = randomforest.predict(take a look at.drop('PassengerId', axis=1))
output = pd.DataFrame({'PassengerId': ids, 'Survived': predictions})
output.to_csv('resultfile.csv', index=False)
|
This can create a resultfile.csv which seems like this



{kind=link}