
A easy and efficient strategy to textual content similarity with TF-IDF and Pandas

Calculating the similarity between two items of textual content is a really helpful exercise within the subject of knowledge mining and pure language processing (NLP). This permits each to isolate anomalies and diagnose for particular issues, for instance very related or very totally different texts on a weblog, or to group related entities into helpful classes.
On this article we’re going to use a script printed right here to scrape a weblog and create a small corpus on which to use a similarity calculation algorithm based mostly on TF-IDF in Python.
Specifically, we’ll use a library known as Trafilatura to retrieve all of the articles from the goal web site by way of its sitemap and place them in a Pandas dataframe for processing.
I invite the reader to learn the article I linked above to know how the extraction algorithm works in additional element.
For simplicity, within the instance we’re going to analyze diariodiunanalista.it, my very own weblog in Italian on information science, to be able to perceive if there are articles which might be too related to one another. Within the course of I’ll diagnose my very own work, and maybe give you some cool insights!
This has vital website positioning repercussions — in truth, related articles give rise to the phenomenon of content material cannibalization: when two items belonging to the identical web site compete for a similar place on Google. We wish to keep away from that and figuring out these sorts of conditions is step one in doing so.
The libraries we’ll want can be Pandas, Numpy, NLTK, Sklearn, TQDM, Matplotlib and Seaborn.
Let’s import them into our Python script.
Moreover, we might want to run the nltk.obtain('stopwords') command to put in the NLTK stopwords. A stopword is a phrase that doesn’t contribute in an necessary technique to the that means of a sentence and we’ll want them to preprocess our texts.
Let’s run the software program from within the article talked about above.

Let’s check out our dataset.
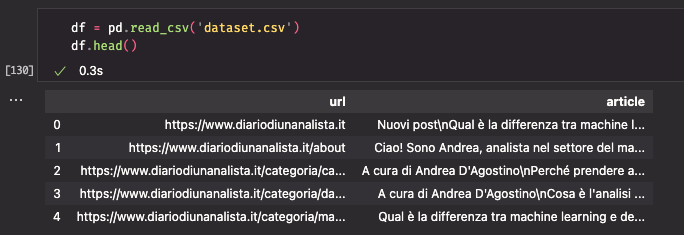
From the taxonomy of the URLs we discover how all of the posts are collected beneath /posts/ — this permits us to isolate solely the precise articles, leaving out pages, classes, tags and extra.
We use the next code to use this choice
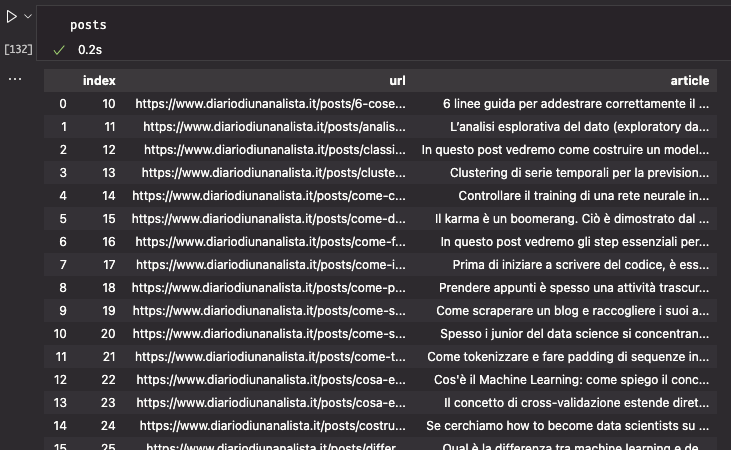
And right here is our corpus. On the time of penning this piece there are round 30 articles — subsequently it’s a very small corpus. It’s going to nonetheless be superb for our instance.
We are going to apply some naked minimal textual content preprocessing to duplicate an actual software pipeline. This may be expanded to enhance the reader’s necessities.
Preprocessing steps
We’re going to apply these preprocessing steps:
- punctuation elimination
- lowercase software
This can all be accomplished in a quite simple operate, which makes use of the usual string and NLTK libraries.
This operate can be utilized by the TF-IDF vectorizer (which we’ll outline shortly) to normalize the textual content.
First, let’s outline our stopwords by saving them in a variable
ita_stopwords = stopwords.phrases('italian')
Now we import TfIdfVectorizer from Sklearn, passing it the preprocessing operate and the stopwords.
The TF-IDF vectorizer will convert every textual content into its vector illustration. This can enable us to deal with every textual content as a sequence of factors in a multidimensional house.
The way in which by which we’re going to calculate the similarity can be by means of the computation of the cosine between the vectors that make up the texts we’re evaluating. The similarity worth is between -1 and +1. A worth of +1 signifies two primarily equal texts, whereas -1 signifies full dissociation.
I invite the reader to learn extra on the topic on the devoted Wikipedia web page.
Now we’ll outline a operate known as compute_similarity which can use the vectorizer to transform the texts to quantity and apply the operate to calculate the similarity cosine with TF-IDF vectors.
Let’s take two texts from Wikipedia in Italian for example.
Figlio secondogenito del giudice sardo Ugone II di Arborea e di Benedetta, proseguì e intensificò l’eredità culturale e politica del padre, volta al mantenimento dell’autonomia del giudicato di Arborea e alla sua indipendenza, che ampliò all’intera Sardegna. Considerato una delle più importanti determine nel ‘300 sardo, contribuì allo sviluppo dell’organizzazione agricola dell’isola grazie alla promulgazione del Codice rurale, emendamento legislativo successivamente incluso da sua figlia Eleonora nella ben più celebre Carta de Logu
L’incredibile Hulk è un movie del 2008 diretto da Louis Leterrier. Il protagonista è interpretato da Edward Norton, il quale contribuì anche alla stesura della sceneggiatura insieme a Zak Penn; il supereroe è incentrato principalmente sulla versione Final si sottopone all’esperimento di proposito, e non viene investito dai raggi gamma nel tentativo di salvare Rick Jones come nell’universo Marvel tradizionale. Il personaggio mantiene comunque i tratti del “gigante buono” della versione classica che vuole solo essere lasciato in tempo dagli uomini, e non il bestiale assassino dell’altro universo.
Let’s apply the cosine_similarity operate to check how related these two texts are. I anticipate a reasonably low worth as they take care of totally different matters and don’t use the identical terminology.
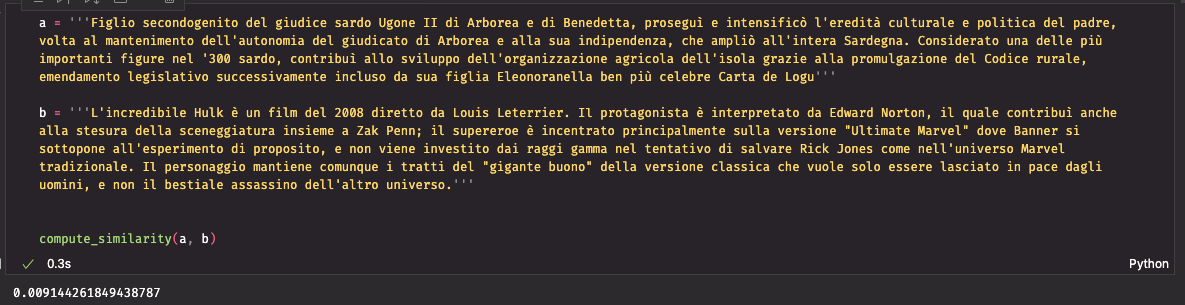
The 2 texts present a really low similarity, near 0. Let’s check it now with two related texts. L’ll copy a part of the second textual content into the primary, conserving the same size.
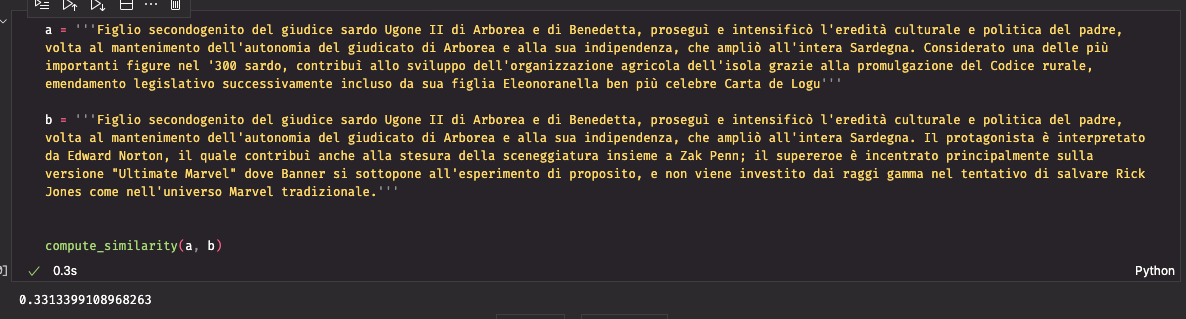
The similarity is now 0.33. It appears to work superb.
Now we apply this methodology to all of corpus, in a pairwise vogue.
Let’s go into element on what this piece of code does.
- We create a 30×30 matrix known as
M - We iterate line by line on the dataframe to entry
article_i - We iterate line by line on the identical dataframe once more, to entry
article_j - We run compute_similarity on
article_iand onarticle_jto acquire the similarity - We save this worth in M at place
i,j
M can simply be transformed right into a Pandas dataframe and this permits us to construct a heatmap with Seaborn.
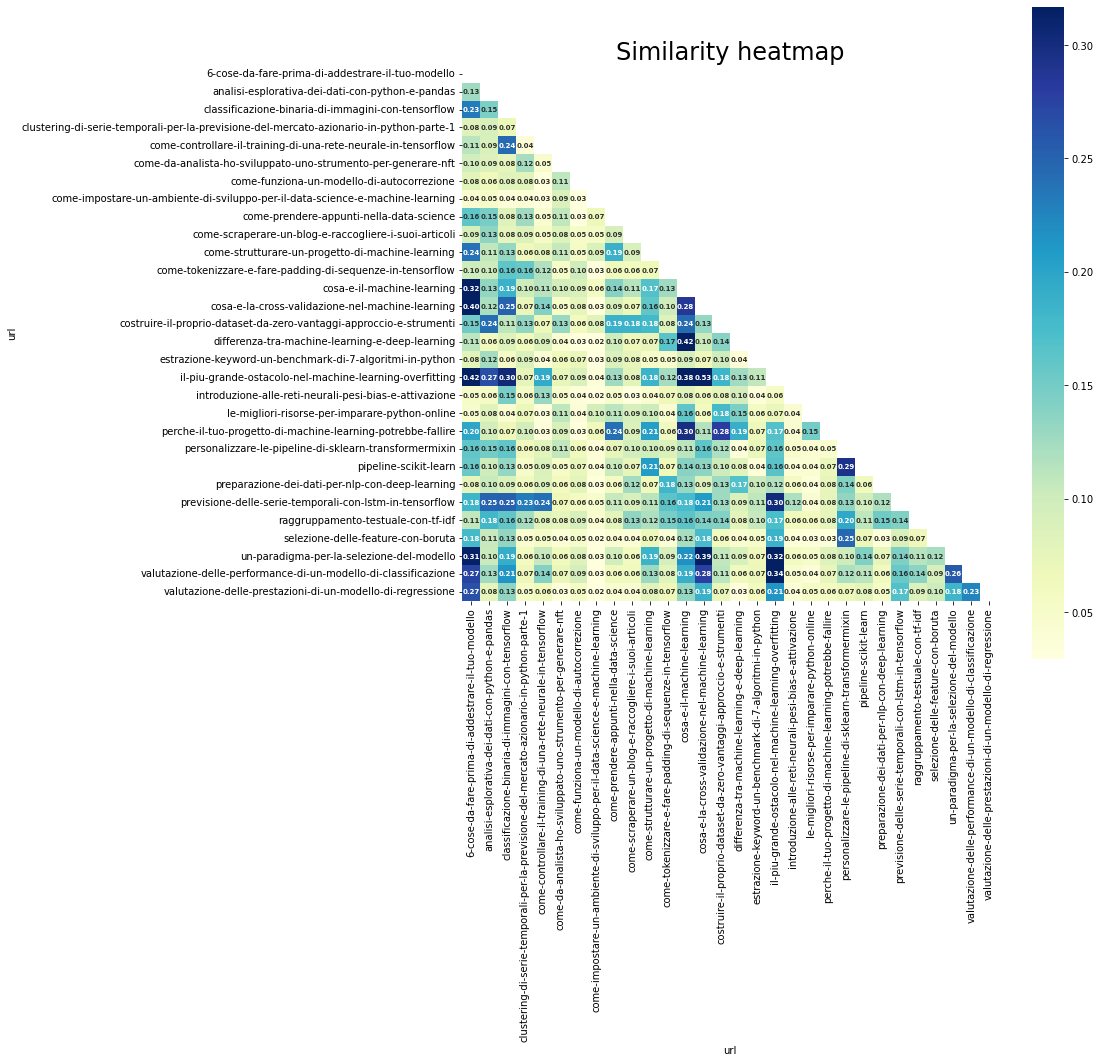
The heatmap highlights anomalies utilizing brighter or duller colours based mostly on the similarity worth obtained.
Let’s make a small change to the code to pick out solely parts which have similarity higher than 0.40.
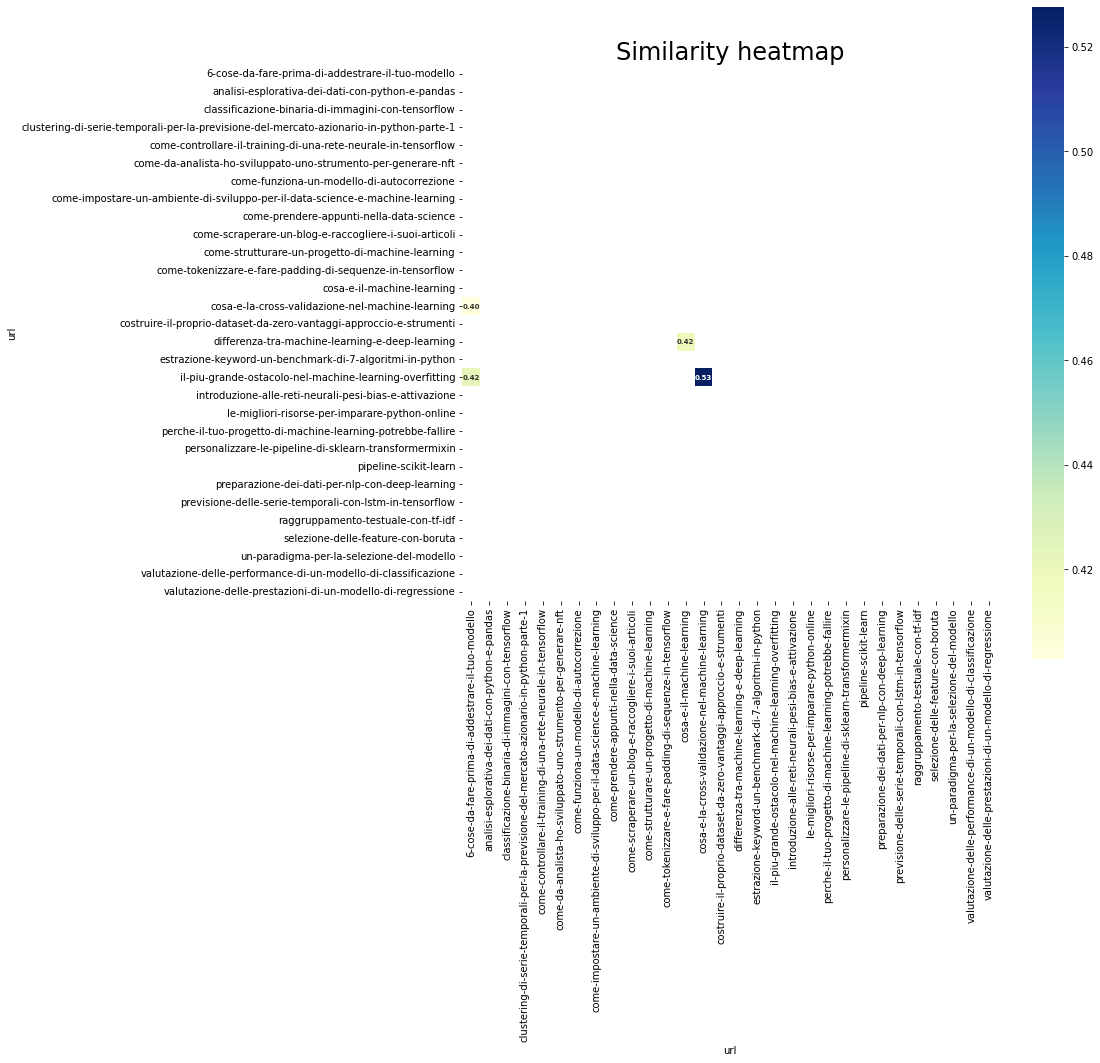
We see 4 pages with a similarity index higher than 0.4.
Specifically we see these combos:
- 6 issues to do earlier than coaching your mannequin -> the largest impediment in machine studying — overfitting
- 6 issues to do earlier than coaching your mannequin -> what’s cross-validation in machine studying
- what’s cross-validation in machine studying -> the largest impediment in machine studying — overfitting
- what’s machine studying -> what’s the distinction between machine studying and deep studying
The similarity between a few of these pairs can be current amongst different pairs that present excessive similarity.
These articles share the subject, particularly that of machine studying and a few finest practices.
On this article we’ve seen a easy however efficient algorithm to establish related pages or articles of an internet site, scraped with an equally environment friendly methodology.
The subsequent steps would come with a deeper evaluation to know why these articles have a excessive similarity. Information mining and NLP instruments, corresponding to Spacy, are very handy and permit a POS (a part of speech) and NER (named entity recognition) evaluation.
Learning essentially the most used key phrases can be simply as efficient!
If you wish to assist my content material creation exercise, be happy to observe my referral hyperlink under and be a part of Medium’s membership program. I’ll obtain a portion of your funding and also you’ll be capable to entry Medium’s plethora of articles on information science and extra in a seamless method.
What’s your methodology to your information mining efforts? How do you often discover anomalies corresponding to related content material? Share your ideas with a remark 
Thanks to your consideration and see you quickly! 

{kind=link}