
XGBoost is an open supply machine studying library that implements optimized distributed gradient boosting algorithms. XGBoost makes use of parallel processing for quick efficiency, handles lacking values properly, performs properly on small datasets, and prevents overfitting. All of those benefits make XGBoost a well-liked resolution for regression issues akin to forecasting.
Forecasting is a crucial job for every kind of enterprise aims, akin to predictive analytics, predictive upkeep, product planning, budgeting, and so on. Many forecasting or prediction issues contain time collection knowledge. That makes XGBoost a superb companion for InfluxDB, the open supply time collection database.
On this tutorial we’ll find out about the way to use the Python bundle for XGBoost to forecast knowledge from InfluxDB time collection database. We’ll additionally use the InfluxDB Python consumer library to question knowledge from InfluxDB and convert the info to a Pandas DataFrame to make working with the time collection knowledge simpler. Then we’ll make our forecast.
I’ll additionally dive into the benefits of XGBoost in additional element.
Necessities
This tutorial was executed on a macOS system with Python 3 put in by way of Homebrew. I like to recommend organising extra tooling like virtualenv, pyenv, or conda-env to simplify Python and consumer installations. In any other case, the total necessities are these:
- influxdb-client = 1.30.0
- pandas = 1.4.3
- xgboost >= 1.7.3
- influxdb-client >= 1.30.0
- pandas >= 1.4.3
- matplotlib >= 3.5.2
- sklearn >= 1.1.1
This tutorial additionally assumes that you’ve a free tier InfluxDB cloud account and that you’ve created a bucket and created a token. You’ll be able to consider a bucket as a database or the best hierarchical stage of knowledge group inside InfluxDB. For this tutorial we’ll create a bucket referred to as NOAA.
Choice timber, random forests, and gradient boosting
To be able to perceive what XGBoost is, we should perceive choice timber, random forests, and gradient boosting. A call tree is a kind of supervised studying technique that’s composed of a collection of exams on a function. Every node is a check and all the nodes are organized in a flowchart construction. The branches symbolize circumstances that in the end decide which leaf or class label will probably be assigned to the enter knowledge.
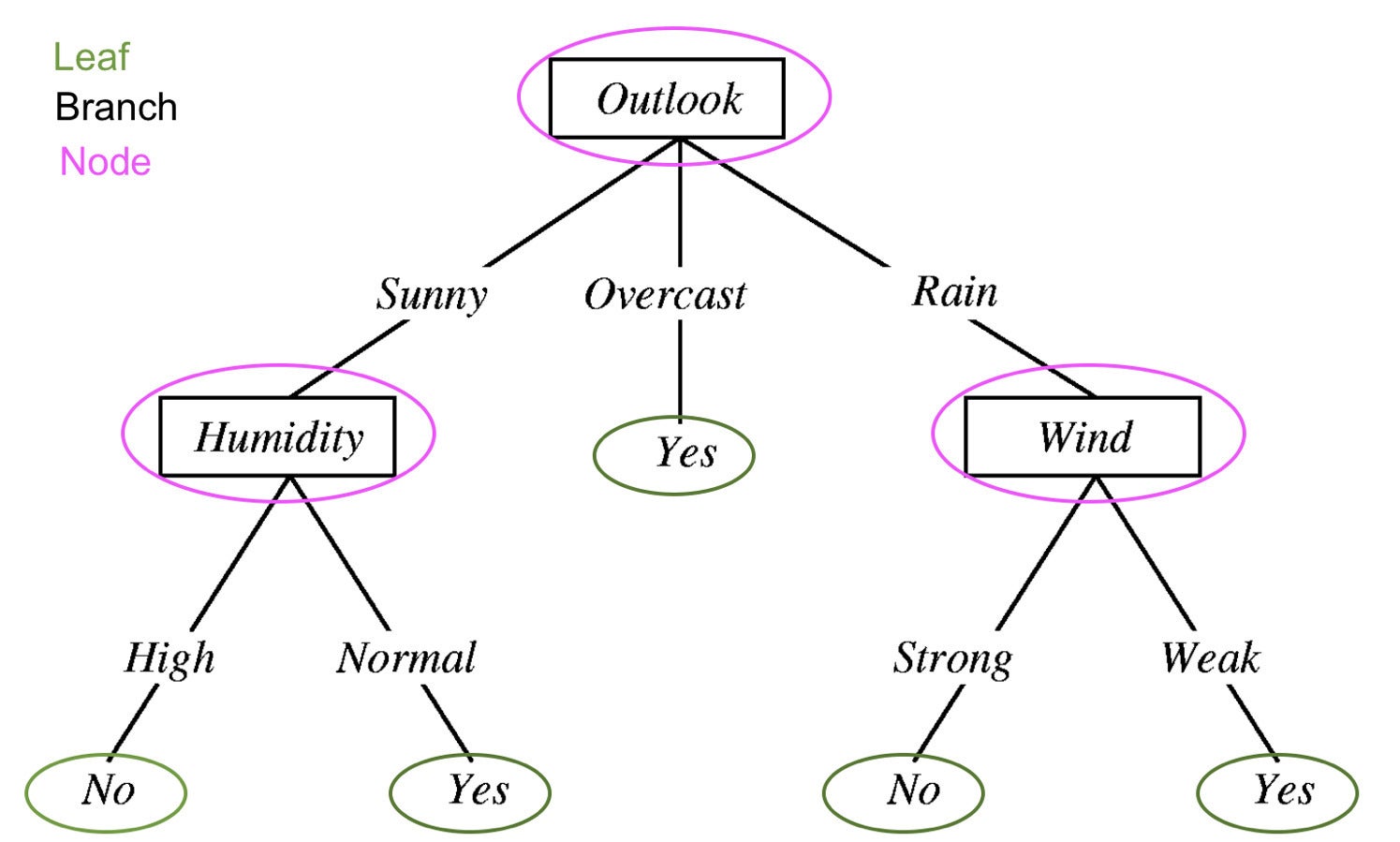 Prince Yadav
Prince YadavA call tree for figuring out whether or not it would rain from Choice Tree in Machine Studying. Edited to indicate the parts of the choice tree: leaves, branches, and nodes.
The tenet behind choice timber, random forests, and gradient boosting is {that a} group of “weak learners” or classifiers collectively make sturdy predictions.
A random forest incorporates a number of choice timber. The place every node in a choice tree can be thought of a weak learner, every choice tree within the forest is taken into account one among many weak learners in a random forest mannequin. Sometimes all the knowledge is randomly divided into subsets and handed by way of totally different choice timber.
Gradient boosting utilizing choice timber and random forests are related, however they differ in the way in which they’re structured. Gradient-boosted timber additionally include a forest of choice timber, however these timber are constructed additively and all the knowledge passes by way of a group of choice timber. (Extra on this within the subsequent part.) Gradient-boosted timber might include a set of classification or regression timber. Classification timber are used for discrete values (e.g. cat or canine). Regression timber are used for steady values (e.g. 0 to 100).
What’s XGBoost?
Gradient boosting is a machine studying algorithm that’s used for classification and predictions. XGBoost is simply an excessive kind of gradient boosting. It’s excessive in the way in which that it may carry out gradient boosting extra effectively with the capability for parallel processing. The diagram under from the XGBoost documentation illustrates how gradient boosting may be used to foretell whether or not a person will like a online game.
 xgboost builders
xgboost buildersTwo timber are used to determine whether or not or not a person will probably be prone to get pleasure from a online game. The leaf rating from each timber is added to find out which particular person will probably be more than likely to benefit from the online game.
See Introduction to Boosted Bushes within the XGBoost documentation to be taught extra about how gradient-boosted timber and XGBoost work.
Some benefits of XGBoost:
- Comparatively straightforward to grasp.
- Works properly on small, structured, and common knowledge with few options.
Some disadvantages of XGBoost:
- Susceptible to overfitting and delicate to outliers. It may be a good suggestion to make use of a materialized view of your time collection knowledge for forecasting with XGBoost.
- Doesn’t carry out properly on sparse or unsupervised knowledge.
Time collection forecasts with XGBoost
We’re utilizing the Air Sensor pattern dataset that comes out of the field with InfluxDB. This dataset incorporates temperature knowledge from a number of sensors. We’re making a temperature forecast for a single sensor. The information seems to be like this:
 InfluxData
InfluxDataUse the next Flux code to import the dataset and filter for the one time collection. (Flux is InfluxDB’s question language.)
import "be a part of"
import "influxdata/influxdb/pattern"
//dataset is common time collection at 10 second intervals
knowledge = pattern.knowledge(set: "airSensor")
|> filter(fn: (r) => r._field == "temperature" and r.sensor_id == "TLM0100")
Random forests and gradient boosting can be utilized for time collection forecasting, however they require that the info be reworked for supervised studying. This implies we should shift our knowledge ahead in a sliding window strategy or lag technique to transform the time collection knowledge to a supervised studying set. We are able to put together the info with Flux as properly. Ideally it’s best to carry out some autocorrelation evaluation first to find out the optimum lag to make use of. For brevity, we’ll simply shift the info by one common time interval with the next Flux code.
import "be a part of"
import "influxdata/influxdb/pattern"
knowledge = pattern.knowledge(set: "airSensor")
|> filter(fn: (r) => r._field == "temperature" and r.sensor_id == "TLM0100")
shiftedData = knowledge
|> timeShift(period: 10s , columns: ["_time"] )
be a part of.time(left: knowledge, proper: shiftedData, as: (l, r) => ({l with knowledge: l._value, shiftedData: r._value}))
|> drop(columns: ["_measurement", "_time", "_value", "sensor_id", "_field"])
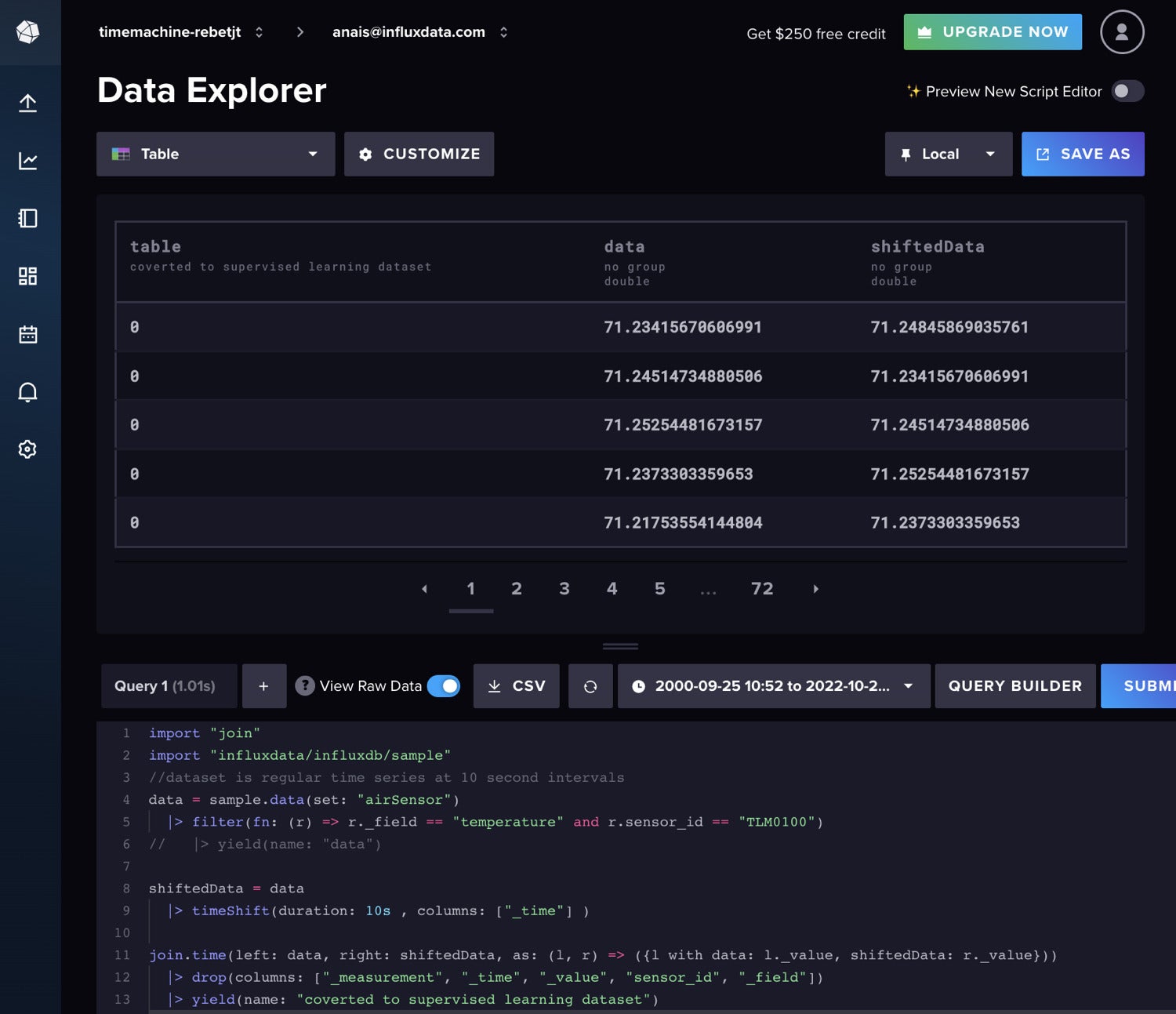 InfluxData
InfluxDataIn case you needed so as to add extra lagged knowledge to your mannequin enter, you possibly can observe the next Flux logic as a substitute.
import "experimental"
import "influxdata/influxdb/pattern"
knowledge = pattern.knowledge(set: "airSensor")
|> filter(fn: (r) => r._field == "temperature" and r.sensor_id == "TLM0100")
shiftedData1 = knowledge
|> timeShift(period: 10s , columns: ["_time"] )
|> set(key: "shift" , worth: "1" )
shiftedData2 = knowledge
|> timeShift(period: 20s , columns: ["_time"] )
|> set(key: "shift" , worth: "2" )
shiftedData3 = knowledge
|> timeShift(period: 30s , columns: ["_time"] )
|> set(key: "shift" , worth: "3")
shiftedData4 = knowledge
|> timeShift(period: 40s , columns: ["_time"] )
|> set(key: "shift" , worth: "4")
union(tables: [shiftedData1, shiftedData2, shiftedData3, shiftedData4])
|> pivot(rowKey:["_time"], columnKey: ["shift"], valueColumn: "_value")
|> drop(columns: ["_measurement", "_time", "_value", "sensor_id", "_field"])
// take away the NaN values
|> restrict(n:360)
|> tail(n: 356)
As well as, we should use walk-forward validation to coach our algorithm. This entails splitting the dataset right into a check set and a coaching set. Then we prepare the XGBoost mannequin with XGBRegressor and make a prediction with the match technique. Lastly, we use MAE (imply absolute error) to find out the accuracy of our predictions. For a lag of 10 seconds, a MAE of 0.035 is calculated. We are able to interpret this as which means that 96.5% of our predictions are excellent. The graph under demonstrates our predicted outcomes from the XGBoost in opposition to our anticipated values from the prepare/check cut up.
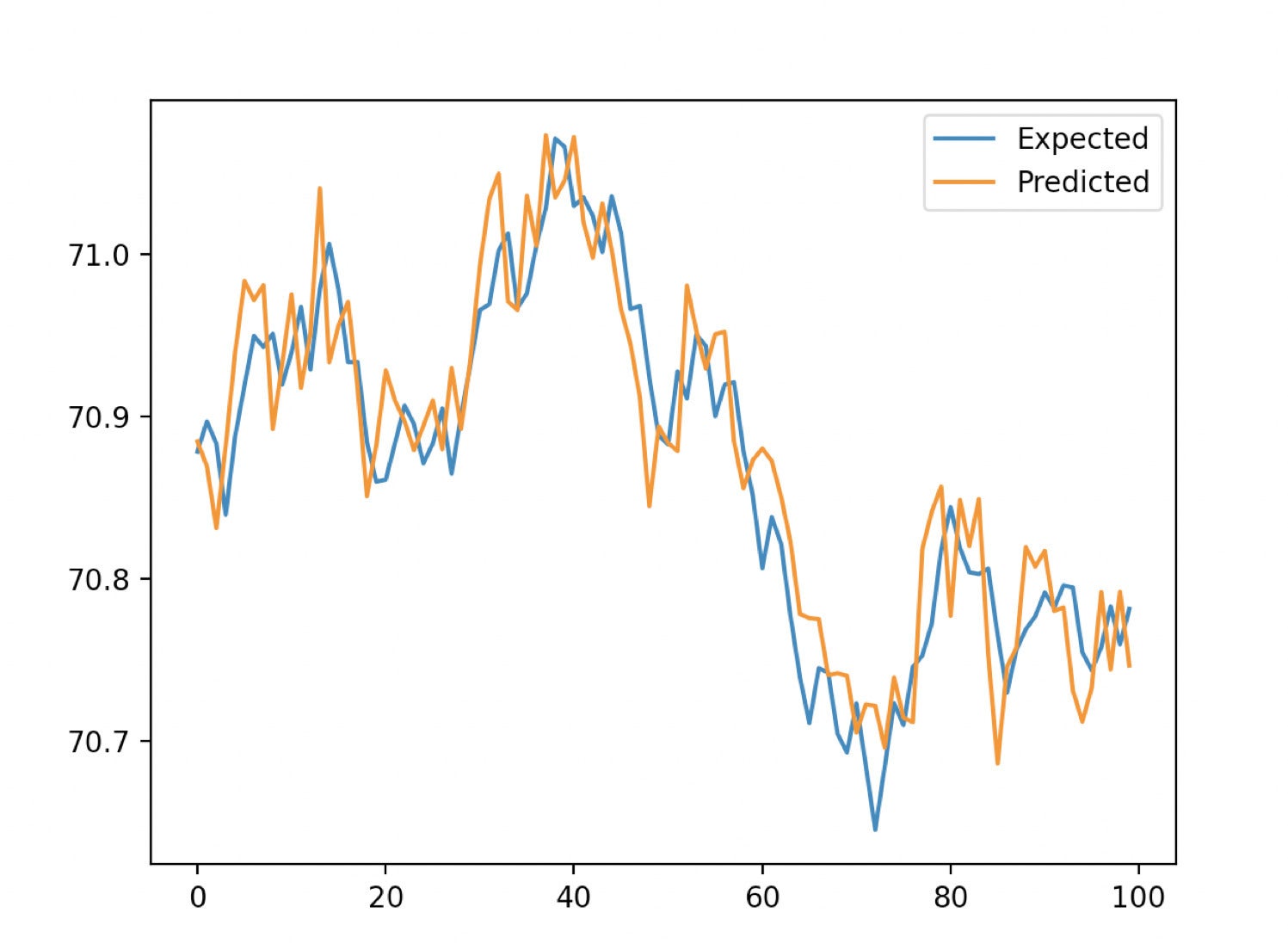 InfluxData
InfluxDataBeneath is the total script. This code was largely borrowed from the tutorial right here.
import pandas as pd
from numpy import asarray
from sklearn.metrics import mean_absolute_error
from xgboost import XGBRegressor
from matplotlib import pyplot
from influxdb_client import InfluxDBClient
from influxdb_client.consumer.write_api import SYNCHRONOUS
# question knowledge with the Python InfluxDB Shopper Library and remodel knowledge right into a supervised studying downside with Flux
consumer = InfluxDBClient(url="https://us-west-2-1.aws.cloud2.influxdata.com", token="NyP-HzFGkObUBI4Wwg6Rbd-_SdrTMtZzbFK921VkMQWp3bv_e9BhpBi6fCBr_0-6i0ev32_XWZcmkDPsearTWA==", org="0437f6d51b579000")
# write_api = consumer.write_api(write_options=SYNCHRONOUS)
query_api = consumer.query_api()
df = query_api.query_data_frame('import "be a part of"'
'import "influxdata/influxdb/pattern"'
'knowledge = pattern.knowledge(set: "airSensor")'
'|> filter(fn: (r) => r._field == "temperature" and r.sensor_id == "TLM0100")'
'shiftedData = knowledge'
'|> timeShift(period: 10s , columns: ["_time"] )'
'be a part of.time(left: knowledge, proper: shiftedData, as: (l, r) => ({l with knowledge: l._value, shiftedData: r._value}))'
'|> drop(columns: ["_measurement", "_time", "_value", "sensor_id", "_field"])'
'|> yield(title: "transformed to supervised studying dataset")'
)
df = df.drop(columns=['table', 'result'])
knowledge = df.to_numpy()
# cut up a univariate dataset into prepare/check units
def train_test_split(knowledge, n_test):
return knowledge[:-n_test:], knowledge[-n_test:]
# match an xgboost mannequin and make a one step prediction
def xgboost_forecast(prepare, testX):
# remodel listing into array
prepare = asarray(prepare)
# cut up into enter and output columns
trainX, trainy = prepare[:, :-1], prepare[:, -1]
# match mannequin
mannequin = XGBRegressor(goal="reg:squarederror", n_estimators=1000)
mannequin.match(trainX, trainy)
# make a one-step prediction
yhat = mannequin.predict(asarray([testX]))
return yhat[0]
# walk-forward validation for univariate knowledge
def walk_forward_validation(knowledge, n_test):
predictions = listing()
# cut up dataset
prepare, check = train_test_split(knowledge, n_test)
historical past = [x for x in train]
# step over every time-step within the check set
for i in vary(len(check)):
# cut up check row into enter and output columns
testX, testy = check[i, :-1], check[i, -1]
# match mannequin on historical past and make a prediction
yhat = xgboost_forecast(historical past, testX)
# retailer forecast in listing of predictions
predictions.append(yhat)
# add precise statement to historical past for the following loop
historical past.append(check[i])
# summarize progress
print('>anticipated=%.1f, predicted=%.1f' % (testy, yhat))
# estimate prediction error
error = mean_absolute_error(check[:, -1], predictions)
return error, check[:, -1], predictions
# consider
mae, y, yhat = walk_forward_validation(knowledge, 100)
print('MAE: %.3f' % mae)
# plot anticipated vs predicted
pyplot.plot(y, label="Anticipated")
pyplot.plot(yhat, label="Predicted")
pyplot.legend()
pyplot.present()
Conclusion
I hope this weblog publish evokes you to make the most of XGBoost and InfluxDB to make forecasts. I encourage you to try the following repo which incorporates examples for the way to work with most of the algorithms described right here and InfluxDB to make forecasts and carry out anomaly detection.
Anais Dotis-Georgiou is a developer advocate for InfluxData with a ardour for making knowledge stunning with using knowledge analytics, AI, and machine studying. She applies a mixture of analysis, exploration, and engineering to translate the info she collects into one thing helpful, helpful, and exquisite. When she is just not behind a display, yow will discover her exterior drawing, stretching, boarding, or chasing after a soccer ball.
—
New Tech Discussion board offers a venue to discover and talk about rising enterprise expertise in unprecedented depth and breadth. The choice is subjective, based mostly on our choose of the applied sciences we imagine to be vital and of best curiosity to InfoWorld readers. InfoWorld doesn’t settle for advertising collateral for publication and reserves the appropriate to edit all contributed content material. Ship all inquiries to newtechforum@infoworld.com.
Copyright © 2022 IDG Communications, Inc.

{kind=link}