

Strategies to switch the need of a contamination degree in outlier detection
Actual life is usually chaotic and unpredictable. It appears to love throwing the metaphorical “spanner within the works”, making knowledge normally seem baffling and random. Most knowledge that’s recorded or extracted usually requires some type of cleansing earlier than making use of additional strategies like modeling. Nevertheless, it’s typically tough or close to unattainable to visually distinguish what knowledge is true, noise, or an anomaly. Typically, anomalies could even be essential, additional complicating the act of distinguishing what knowledge to make use of. That’s the place the methods of outlier detection is available in.
Outlier detection strategies can are available many shapes and types. However the crux of their potential to detect outliers is mostly by a set of statistical situations. Some are rigorous, others easy, but all these strategies are necessary to an information scientist’s toolkit when on the hunt for knowledge that stands out from the remainder.
PyOD is a considered one of many python libraries that incorporates a helpful assortment of strategies for outlier detection. It’s simplistic in use and has a plethora extra outlier detection strategies than most different libraries. Therefore, why it’s such a favourite amongst most knowledge scientists. Nevertheless, a pesky but essential parameter exists when making an attempt to make use of most strategies to search out outliers… the contamination degree. Most strategies return a outlier confidence rating when utilized to a dataset. This rating is helpful in its personal proper however like regression is to classification, it lacks the labels. Due to this fact, a contamination degree is required to set the boundary separating inliers from outliers by thresholding the arrogance scores.
In PyOD and plenty of different libraries the contamination degree is usually set earlier than outlier detection. Nevertheless, this enter parameter raises the query: how does one know the way contaminated their dataset is earlier than testing for outliers? And that could be a nice query! The reply to this normally signifies that some type of statistical take a look at have to be completed previous to outlier detection to get the contamination degree. Fashionable strategies embody utilizing the z-score or the inter-quartile area. Whereas these are a great approximate to the proper contamination degree they aren’t infallible to their very own disadvantages. A greater method can be to use statistical exams to the outlier detection scores themselves as a way to threshold inliers from outliers.
The next examples will implement the PyThresh library… a library meant for thresholding outlier scores, and that I’m affiliated with and actively creating. PyThresh consists of a group of statistical strategies that try and threshold the outlier detection scores with out the necessity of setting a contamination degree previous to becoming the info. These statistical strategies vary from classical thresholding reminiscent of k-means clustering and chance distances, to extra obscure strategies that contain topology and graph principle. All in all, they try and take the guessing of contamination ranges (educated as they might be) out of the equation in terms of outlier detection.
Let’s check out how thresholding may be applied on outlier detection scores. For the instance under the cardio open supply dataset from Outlier Detection DataSets (ODDS) will probably be used. This dataset was made freely obtainable by the Stony Brook College and represents actual world knowledge [1].
The cardio (Cardiotocography) dataset [2][3] consists of measurements of fetal coronary heart fee and uterine contraction options on cardiotocograms that had been labeled by skilled obstetricians. The measurements had been classed as both being regular (inliers) or pathologic (outliers).
To begin, let’s load the cardio dataset and standardize the variables that will probably be scored by the outlier detection methodology.
If we take a fast take a look at the info we are able to see that we are going to have 21 explanatory variables to suit, with every variable having 1831 distinctive entries. Of these entries, 1655 (~90%) are inliers and 176 (~10%) are outliers as classed within the response variable.
With a view to accurately establish the 2 courses, it is very important choose the proper outlier detection and outlier thresholding strategies. For this dataset, the Precept Element Evaluation (PCA) outlier detection methodology was chosen as a result of quantity of exploratory variables. This methodology reduces the dimensionality of the info by developing a subspace that’s generated by eigenvectors that represents the best variance that may nonetheless clarify the info. Outliers can change into extra obvious throughout this dimensionality discount and the outlier scores are the sum of the projected distance of a pattern on all eigenvectors. For this dataset, we are going to set the variety of parts to scale back from 21 to five.
Synergy between the outlier and thresholding strategies typically supplies higher outcomes. That is as a result of method the scores which can be generated by the outlier detection methodology are then dealt with by the thresholding methodology. The extra related the 2 strategies behave, the much less probability there’s for an irrational threshold to happen. Nevertheless, this isn’t at all times the case and choosing the proper outlier detection and thresholding strategies could require strong statistical exams earlier than and after software.
For this dataset together with the outlier detection methodology a great corresponding thresholding methodology can be the Distance Shift from Regular (DSN) threshold. The best way this threshold works is that it compares the chance distribution of the outlier scores with that of a standard distribution, and measures the distinction between the 2. When working with statistical distances it is very important choose the metric with which measurements will probably be made. The Bhattacharyya distance is a measure of similarity between two chance distributions and returns the quantity of overlap that exists between them. Technically it’s not a metric, nevertheless it is going to be used for thresholding the dataset. The Bhattacharyya distance is outlined as,

the place p and q symbolize the 2 chance distributions over the identical area X and the Bhattacharyya coefficient (BC) for steady chance distributions may be expressed by,

The edge for the outlier detection scores is lastly set such that any rating greater than 1 minus the Bhattacharyya distance is labelled as an outlier.
With a greater understanding now, we are able to apply these strategies to the dataset:
The labels returned from the thresholder consists of a binary array the place inliers are represented by zeros and outliers by ones. Earlier than revealing the ultimate tally of how properly these strategies carried out, let’s fairly take a look at a side-by-side plot of the true vs the expected labels. Once more we are going to use PCA, however now to visualise the info in 2D by lowering the dimensionality. This step, together with others, is important when working with actual world knowledge that has no response variable because it supplies a visible illustration of what was thresholded. Be aware that PCA is an orthogonal linear transformation and due to this fact outliers with a non-linear relationship could not at all times seem as evident outliers visually. Additionally lowering the info to 2 dimensions may take away the dimensionality wanted to differentiate inliers from outliers. Nevertheless, even with these disadvantages PCA visualization is a robust affirmation testing instrument.
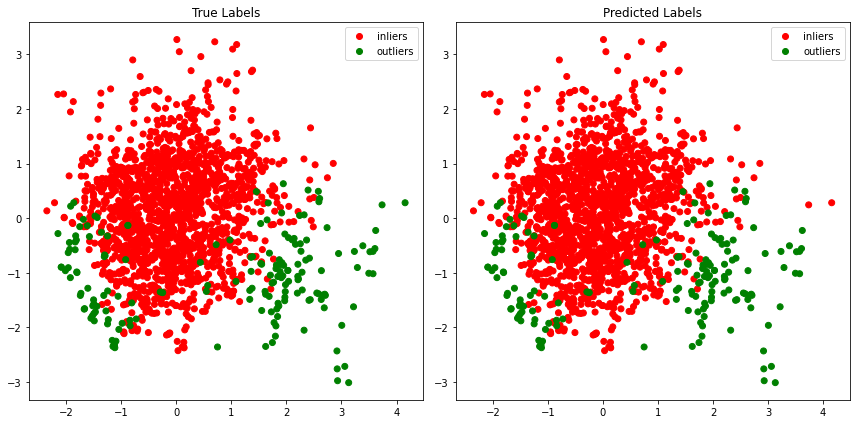
As we are able to see from the plot, the DSN threshold together with the PCA outlier detector scores was capable of separate outliers from inliers with important accuracy! The accuracy for this instance was 99% correct with solely two outliers classed as inliers and no inliers classed as outliers. Nevertheless, relying on the dataset, the utilized outlier detector, and the thresholder, the prediction accuracy will differ. Though the contamination degree has been eliminated for a extra statistical method to threshold outlier scores, on the finish of the day it’s as much as the info scientist to make the ultimate name if the expected outcomes seem appropriate.
In closing, thresholding of outlier detection scores is just not a brand new science and has many properly established implementations. These statistical and mathematical strategies add to an information scientists toolkit, and help in navigating although the great world of knowledge and knowledge.
[1] Shebuti Rayana (2016). ODDS Library [http://odds.cs.stonybrook.edu]. Stony Brook, NY: Stony Brook College, Division of Pc Science.
[2] C. C. Aggarwal and S. Sathe, “Theoretical foundations and algorithms for outlier ensembles.” ACM SIGKDD Explorations E-newsletter, vol. 17, no. 1, pp. 24–47, 2015.
[3] Saket Sathe and Charu C. Aggarwal. LODES: Native Density meets Spectral Outlier Detection. SIAM Convention on Knowledge Mining, 2016.

{kind=link}