

Should you suppose you recognize what ADASYN is doing in predictive fashions, you’re most certainly incorrect. Learn on and we’ll present you the exceptional reality.
Precept Researcher: Dave Guggenheim / Co-Researcher: Srish Tirumalai
Preface
This analysis assumes that you’re acquainted with class imbalance and the ADASYN algorithm. We strongly encourage our readers to assessment the convention article that launched ADASYN (simply kind that into Google Scholar or see the References part of this doc), after which learn any variety of articles in In the direction of Information Science that debate class imbalance and ADASYN.
As a result of that is neither a information nor an outline; it’s voyage into uncharted waters with startling discoveries.
Introduction
There have been three major questions we wished to research on the outset:
- Do studying fashions and their predictions have differing sensitivities to class imbalance?
- Does ADASYN supply secure predictions throughout a spread of synthesized pattern ratios and studying fashions?
- What’s ADASYN actually doing with unseen knowledge?
The solutions are 1) stunning, 2) fascinating, and three) extraordinary, in that order. However first, we’ll share the muse of the experiments.
Mannequin Definition
All fashions on this analysis have been performed utilizing the RandomForest and LogisticRegression algorithms within the sci-kit study library to realize details about each tree and linear constructions, respectively. All predictive fashions have been 10-fold cross-validated with stratified sampling utilizing “stratify=y” in train_test_split and “cv=10” in GridSearchCV.
All hyperparameters of the random forest fashions have been left of their default states, and ‘random_state=1’ was utilized to all random seed alternatives for partitioning, processing (ADASYN), and modeling.
The linear operate used right here is LogisticRegression + GridSearchCV. Every binary logistic regression classification mannequin was run with the next hyperparameters:
1) penalty = ‘l2’
2) C = 1E42
3) solver = ‘liblinear’
4) class_weight = None
5) cv = 10
6) max_iter = 5000
7) scoring = ‘accuracy’
8) random_state = 1
In an effort to keep the usage of the liblinear solver (it helps each l1 and l2 penalties and we use it solely in our analysis as a stage enjoying area), this solver choice requires setting a regularization penalty. On this case, we selected ‘l2’ or ridge because the penalty, however as a result of we’re solely within the results of ADASYN, we disabled it by setting ‘C’ to be very giant. On this approach, we didn’t need to introduce function scaling as a knowledge preprocessing element, which is problematic given our prior discoveries (The Thriller of Function Scaling is Lastly Solved | by Dave Guggenheim | In the direction of Information Science). All different hyperparameters have been left to their default values.
As a result of pattern dimension is all the time a difficulty with machine studying, if a dataset had lower than 12 samples per predictor as a set level for generalization error (Shmueli, Bruce, Gedeck, & Patel 2019), we reserved 10% of the inhabitants as take a look at samples. For fashions with greater than 24 samples/predictor, we cut up the dataset into equal halves, with 50% for coaching and 50% for testing. Between these two values, we used an equation to steadiness generalization error on the take a look at set with a large-enough coaching set (Abu-Mostafa, Magdon-Ismail, & Lin, 2012, pg. 57).
4 of the datasets contained lacking values, so to keep up consistency with prior analysis we used the MissForest algorithm for lacking worth imputation (MissForest · PyPI) on account of its capability to withstand deleterious results from noise, outliers, or multicollinearity. As well as, we selected to dummy code categorical predictors totally reasonably than go for alternate algorithms for nominal or ordinal knowledge varieties. As a result of each linear and tree fashions are on this analysis, the dummy coding had each dropped and no dropped subtypes for logistic regression and random forest fashions, respectively. As all the time, if a possible predictor is clearly low or no-information, akin to an ID quantity, it was dropped previous to knowledge preprocessing.
These fashions have been constructed for the aim of inspecting the impression of ADASYN reasonably than tuning a mannequin to realize the very best outcomes. For that reason, we included as many default values within the fashions as potential to create a stage floor for mentioned comparisons.
As with our prior analysis, this work incorporates the random operate that’s variance, so outcomes are on knowledge unseen by the educational mannequin. All confusion matrices and their associated analyses symbolize take a look at knowledge — the true world.
Datasets
The thirty open-source datasets used on this evaluation are offered in Desk 1, and so they have been chosen for his or her vary of information varieties and complexity. The UCI index (UCI Machine Studying Repository: Information Units) hosts most of those datasets. Others not within the UCI index are positioned at Kaggle (Discover Open Datasets and Machine Studying Tasks | Kaggle).

Datasets for which there was inadequate class imbalance to generate artificial samples have been excluded from consideration; in any other case, they have been chosen to symbolize a variety of imbalances as proven in Determine 1. The Classdiff, or class distinction measure is an easy subtraction of the p.c of the minority class from the p.c of the bulk class.

The goal variables are totally binomial as a result of ADASYN can solely function on binary classification knowledge. Now, on to these questions…
Do studying fashions and their predictions have differing sensitivities to class imbalance?
The stunning reply isn’t any, at the least not for these two fashions. To find out this situation, we measured the proportion of the take a look at knowledge that’s False Adverse in unbalanced fashions for each random forest and logistic regression throughout all datasets. Elevated concentrations of False Negatives point out a better sensitivity to class imbalance as a result of elevated propensity to mis-classify a True Constructive, the minority class. Check with Determine 2 for particulars.
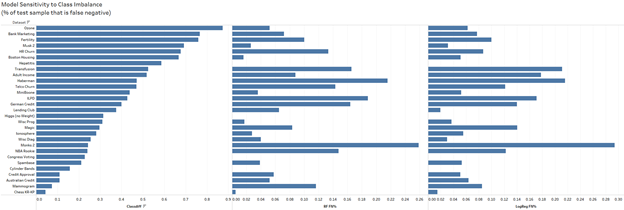
Unbalanced random forest fashions averaged 7.967% of take a look at knowledge as False Adverse whereas unbalanced logistic regression fashions averaged 8.51%, and by failing to reject the null, a number of t-tests confirmed that they symbolize the identical distribution (see Figures 3, 4, and 5).



Two very totally different studying fashions, and but each predict with the identical sensitivity to class imbalance on common. Extra mannequin varieties shall be examined to find out if class imbalance is a common, prediction-agnostic phenomenon.
Does ADASYN supply secure predictions throughout a spread of synthesized ratios and studying fashions?
ADASYN presents the power to alter the ratio of synthesized samples, from the default 50/50 distribution, which has the most important variety of synthesized samples, all the way down to the pure class imbalance of the info the place no synthesized samples are generated. Every chart reveals the identify of the dataset throughout the highest and a collection of fashions utilizing the ADASYN ratio operate and measured with the F1 rating on the y-axis (labeled ‘Accuracy’). F1 rating was chosen because it was a advisable normal measure by the ADASYN authors (He, Bai, Garcia, & Li, 2008). The x-axis comprises the ratio of majority/minority lessons expressed as a deviation from the 50/50 place to begin. A fast information for studying the x-axis tick marks is as follows:
a. 0 = 50/50 ratio
b. 10 = 55/45 ratio (50+5 and 50–5)
c. 20 = 60/40 ratio (50+10 and 50–10)
d. 30 = 65/35 ratio (50+15 and 50–15)
e. 40 = 70/30 ratio (and so forth.)
f. 50 = 75/25 ratio (and so forth.)
g. 60 = 80/20 ratio (and so forth.)
The default 50/50 ADASYN distribution is on the far left and the pure imbalance happens on the far proper. Every in-sequence mannequin that defines the traces represents a two-percent enhance at school distinction from the 50/50 place to begin till pure imbalance was reached (every mannequin = majority +1 and minority -1). The blue dots (on the far left) point out the coaching knowledge with out balancing whereas the orange dots (similar locale) present the take a look at knowledge with out balancing. Horizontal blue and orange traces present balanced coaching and take a look at knowledge, respectively — these in-sequence fashions.
There are two plots in every group, the dataset fitted with random forest adopted by similar fitted with logistic regression (see Figures 6–11). We have been seeking to see how disturbed the take a look at knowledge plotted traces have been throughout the vary of synthesized samples, datasets, and fashions, therefore the amount of plots.
We’ll discuss them right here so you possibly can skip the plots and get to the ADASYN Reveal faster. Principally, random forest is generally secure throughout the vary of ratios for all datasets whereas logistic regression can turn out to be fairly disturbed, with fascinating stepwise features leading to secure quantum ranges. The mathematical description of those quantum ranges, significantly the willpower of their dimensions, needs to be explored in future work.
No matter studying mannequin, and in nearly each case, the default 50/50 ADASYN processing was secure and supplied the very best efficiency on the take a look at knowledge. Nonetheless, there have been some exceptions (e.g., Churn Modeling utilizing each fashions, Credit score Approval with RandomForest, and German Credit score with LogisticRegression). Please check with the next charts for illustrations from this 1,000+ mannequin experiment.


Word: Australian Credit score demonstrates knowledge that’s almost balanced with out artificial adjustment (284/233 class samples within the coaching set). There was no ADASYN enchancment in random forest, however logistic regression confirmed higher efficiency regardless of the injection of a restricted variety of artificial samples within the coaching knowledge.




For many datasets, ADASYN is solely changing take a look at samples from True Adverse to False Constructive (the higher lateral) and from False Adverse to True Constructive (the decrease lateral), one-for-one inside every lateral, respectively. A small variety of datasets traveled within the reverse path, additionally one-for-one inside every lateral. Please check with Determine 12 for extra particulars.

The next 4 graphs (Figs. 13–16) present the delta in True Negatives (TN), False Positives (FP), False Negatives (FN), and True Positives (TP) as measured in share change of the take a look at knowledge as a result of software of ADASYN. Random forest fashions are the primary two graphs whereas logistic regression follows. The primary of every pair of graphs (Figs. 13 and 15) reveals the connection between True Negatives and False Positives and the second of every pair (Figs. 14 and 16) reveals the connection between False Negatives and True Positives.
Bars transferring to the left point out a discount by share of the take a look at knowledge and bars transferring to the fitting point out a rise as a share of similar — that is the delta from an unbalanced mannequin. Equal-length bars in opposition, the ‘butterfly’s wings’, present a direct switch from a left-side quadrant to its lateral relation within the confusion matrix due to ADASYN*
*Totally supported by the numeric knowledge underlying these graphs. Statistical help is irrelevant as a result of transfers are equivalent in absolute worth.
Random Forest Fashions

Relating to random forest fashions, 26 of the 30 datasets confirmed a zero or positive-value switch from True Adverse to False Constructive in precisely equal portions (eight with zero and 18 positive-valued). These outcomes will trigger no change to the denominator however a discount within the numerator for specificity (TN/(TN+FP)), thus a discount total for the metric that captures each the supply and sink for the TN-FP switch.
Precision ought to by no means be used as a result of it fails to seize the True Adverse supply for the False Constructive sink. Moreover, the F1 rating ought to by no means be used as a result of it incorporates precision in each the numerator and denominator.
4 of the datasets confirmed a reverse of this situation, with transfers occurring from False Constructive to True Adverse. This phenomenon shall be explored shortly.

Transferring to the FN-TP dimension, 26 of the 30 datasets confirmed a zero or positive-count switch from False Adverse to True Constructive in precisely equal portions (4 with zero and 22 positive-valued). These outcomes will trigger no change to the denominator however a rise within the numerator for sensitivity (TP/(TP+FN)), thus a rise total for the metric that captures each the supply and sink for the FN-TP switch.
4 of the datasets confirmed a reverse of this situation, with transfers occurring from True Constructive to False Adverse, once more to be explored quickly.
Logistic Regression Fashions

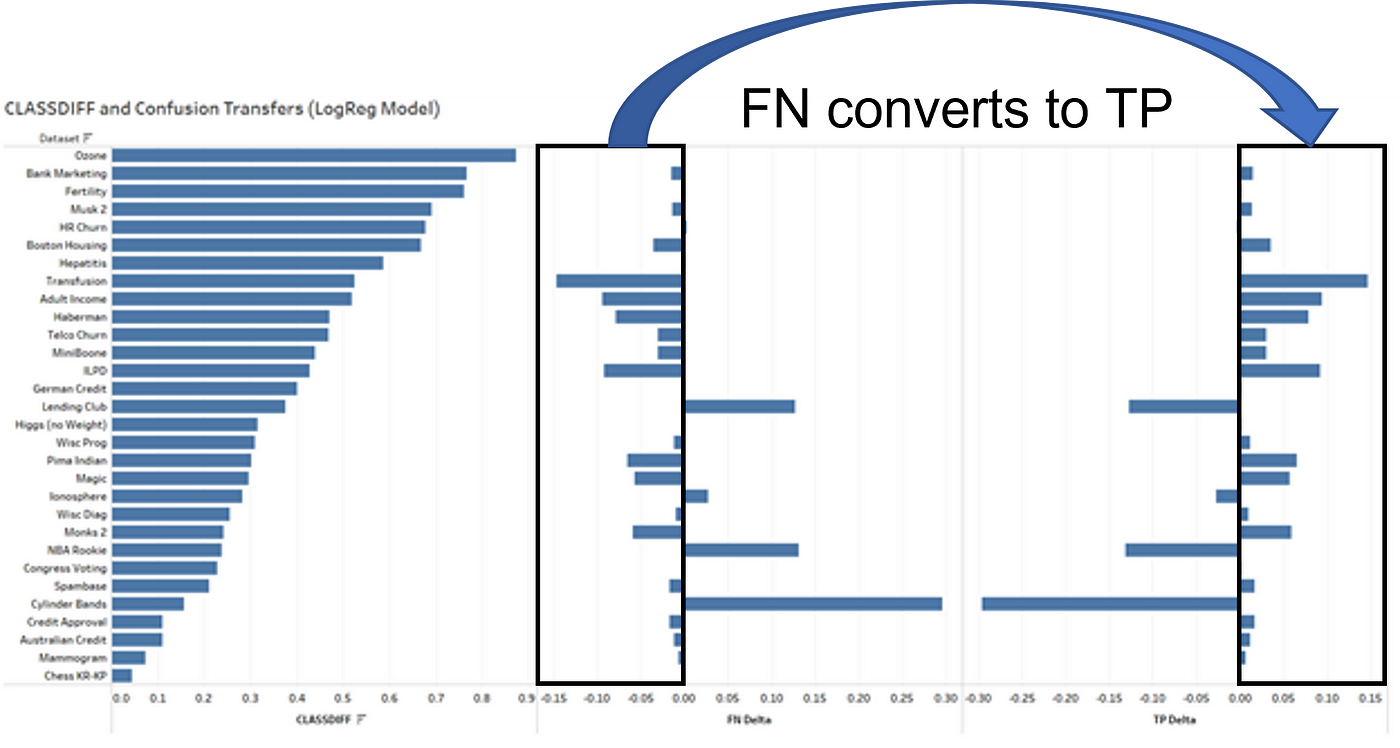
Relating to logistic regression fashions, 26 of the 30 datasets confirmed a zero or positive-valued switch from True Adverse to False Constructive in precisely equal portions (4 with zero and 22 positive-valued). As well as, transferring to the FN-TP dimension, additionally 26 of the 30 datasets confirmed a zero or positive-valued switch from False Adverse to True Constructive in precisely equal portions (six with zero and 20 positive-valued).
As acknowledged, specificity and sensitivity needs to be used for evaluation as a result of they embrace each the supply and sink respectively for confusion transfers (see Determine 17 for extra data).

A normal measure of efficiency may begin with informedness, which is the same as specificity + sensitivity − 1. One other measure could possibly be the harmonic imply of sensitivity and specificity as an adaptation of the F1 rating [2 * ((TPR * TNR)/(TPR + TNR))]. Nonetheless, the F1 rating has been criticized as a result of it could take into account specificity to have the identical worth as sensitivity, which is never the case. There’s a tunable F1 rating that makes use of a beta coefficient to induce an offset between the 2 base measures (the fbeta_score in sklearn.metrics) and this could possibly be tailored, however selecting that coefficient is problematic. Others have proposed the Matthews correlation coefficient as a greater measure for binary variables (Chicco & Jurman, 2020).
Reverse Transfers
Reverse transfers are these the place False Positives turn out to be True Negatives and when True Positives turn out to be False Negatives. There have been seven datasets that resulted in reverse transfers, three have been unique to random forest fashions, one was unique to logistic regression, and three that generated reverse transfers whatever the studying mannequin (see Desk 2).
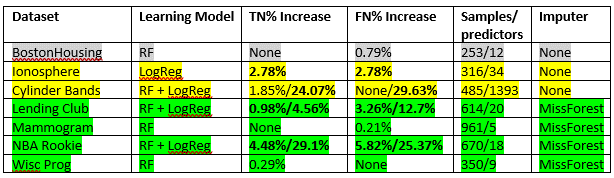
If each TN and FN elevated (proven in daring), then a matched pair of lateral confusion quadrants have been discovered. The desk is color-coded, with grey indicating an unknown, yellow displaying pattern dimension points, and inexperienced displaying a shared use of MissForest.
Specializing in the random forest mannequin (see Figures 18 and 19), one of many two smaller reverse transfers of the 4 (counting from the highest, quantity 4) could possibly be on account of points with pattern dimension. In that case there have been far fewer than 12 samples per predictor (i.e., p >> n) and a miniscule reverse switch was seen. Whereas that is anecdotal, pattern dimension is all the time a difficulty in machine studying, and these minor reverse transfers could possibly be the results of instabilities within the mannequin. In these instances of potential pattern dimension issues, there have been a scarcity of matches between the TN-FP and FN-TP switch dimensions additional implicating mannequin instability. BostonHousing is an anomaly in that pattern dimension doesn’t seem like a difficulty regardless of a negligible impression from the reverse switch — this shall be studied additional in later analysis.


Nonetheless, a a lot bigger reverse switch occurred in two datasets no matter studying mannequin and the place pattern dimension was not a difficulty. These two datasets (Lending Membership and NBA Rookie) had matched reverse transfers (FP transformed to TN and TP transformed to FN) and little else in similarity apart from dramatic will increase in each TN% delta and FN% delta with logistic regression; for instance, NBA Rookie displayed a 29.1% enhance in True Negatives and a 25.37% enhance in False Negatives (and corresponding decreases in FP and TP) over its unbalanced mannequin. NBA Rookie is all numeric with numerous floating-point predictors whereas Lending Membership has eight categorical variables that induced better sparsification on account of one-hot encoding (see Desk 3). The one attribute they do share is that each used the MissForest lacking worth imputation algorithm. In truth, of the seven datasets that resulted in reverse transfers, 4 of them used the MissForest algorithm — these have been the one 4 datasets with lacking values.

ADASYN makes use of the k-nearest neighbors (kNN) algorithm internally and altering the lacking worth imputation algorithm to KNNImputer from the sklearn.impute library resulted in minor enhancements such that Mammogram and Wisc Prog have been transformed from unmatched reverse transfers to matched ahead transfers of small proportion; basically, regular operation was achieved. Whereas small enhancements have been measured, each Lending Membership and NBA Rookie nonetheless have severe points with reverse transfers, an unexplained phenomenon deserving of additional analysis.
However this does increase an fascinating software level — we must always think about using kNN lacking worth imputation when working with ADASYN because it supplied barely higher efficiency in each case of lacking values.
Eventualities for Enterprise Analytics
Specificity and sensitivity, whereas good metrics, every fail to seize details about the alternative lateral within the confusion matrix. Specificity defines the higher lateral and sensitivity measures the decrease, however neither can ‘see’ the opposite aspect of the equation. The measure informedness helps remedy this drawback, however better understanding comes from an financial evaluation, which includes all 4 quadrants of the confusion matrix and normalizes them in a price/profit relationship. Whereas False Negatives and False Positives nearly all the time have an related price, True Negatives and True Positives is usually a price or profit relying on the state of affairs, which limits the usefulness of normal measures for efficiency in enterprise settings.
Accordingly, if the detrimental worth of the TN-FP shift is bigger than the optimistic worth of the FN-TP switch, then ADASYN will underperform an unbalanced mannequin. Conversely, if the FN-TP conversion ends in better absolute worth than the TN-FP dimension, then the ADASYN-assisted mannequin shall be superior.
The next 4 situations discover the idea of financial efficiency with simplified instances to indicate a number of potential outcomes.
State of affairs 1 Worker Attrition (HR Churn)
On this case, the goal variable, Gone, signifies an worker who has left the group. Predicting impending resignations with precision could be fairly vital, even with out The Nice Resignation, due to the associated fee to rent and practice new personnel.
Utilizing knowledge from the U.S. Bureau of Labor, the associated fee to switch an worker could be as much as 200% of annual wage for executives, however the nationwide common is 21% of annual wage. The price of an intervention to forestall a resignation is just not accessible as they’re normally custom-made, so we selected 4% of annual wage as retention prices. It needs to be famous that this retention price might fluctuate over time and circumstances. Information estimating common salaries by career was additionally obtained from the Bureau of Labor.
TN = Worker is unaffected, which is impartial.
FN = Worker will depart with out intervention; Value to switch * rely is detrimental
FP = Worker gained’t depart, however intervention anyway; Value to keep up * rely is detrimental
TP = Worker will depart however intervention has prevented; Value to keep up * rely is detrimental however price to switch * rely is a optimistic financial savings.

Desk 4 signifies that ADASYN-assisted random forest outperformed all different fashions within the collection.
State of affairs 2 Credit score Approval (Credit score Approval)
For this case, we chosen a imply credit score worth of $10,000 and a 25% default price of that worth.
TN = Credit score is authorised and the quantity * rely is added as a optimistic
FN = Credit score is authorised, however quantity * default price * rely is a detrimental
FP = Credit score is denied, and quantity * rely is a detrimental
TP = Credit score is denied, which resulted in saving the price of default * rely as a optimistic

Desk 5 signifies that the unassisted random forest mannequin outperformed all different fashions within the collection.
State of affairs 3 Buyer Churn (Telco Churn)
Having labored within the telecommunications trade with predictive fashions, our estimates of $500 as the associated fee to switch a buyer and $50 as a price to retain are based mostly on real-world data that at one time was appropriate, however now could possibly be out of date.
TN = Buyer is unaffected, which is impartial.
FN = Buyer will depart with out intervention; Value to switch * rely is detrimental
FP = Buyer gained’t depart, however intervention anyway; Value to keep up * rely is detrimental
TP = Buyer will depart however intervention has prevented; Value to keep up * rely is detrimental

Desk 6 signifies that ADASYN-assisted logistic regression outperformed all different fashions within the collection. Please do not forget that this can be a simplified state of affairs, one that doesn’t take into account buyer income, so extra element within the economics might lead to a shift to a special mannequin.
State of affairs 4 Mortgage Approval (Lending Membership)
As a result of it’s the supply of presumably deleterious results from reverse transfers, we select this dataset to research the impression of these occasions. On this case, we selected a median mortgage approval of $25,000 with a default price of $6,250.
TN = Mortgage is authorised and the mortgage quantity * rely is added as a optimistic
FN = Mortgage is authorised, however mortgage quantity * default price * rely is a detrimental
FP = Mortgage is denied, and mortgage quantity * rely is a detrimental
TP = Mortgage is denied, which saved the price of default * rely as a optimistic

Desk 7 signifies that ADASYN-assisted logistic regression outperformed all different fashions within the collection. This state of affairs demonstrates how reverse transfers have been enhancing the efficiency due to the bigger variety of True Negatives, and on this state of affairs, the TN quadrant holds a big optimistic valuation. Regardless of a rise in False Negatives, the default price wasn’t in a position to overcome the mortgage profit, however we imagine this to be a uncommon prevalence as a result of the TN quadrant normally doesn’t maintain such a big valuation.
Conclusion
Our investigation led us to some really thought-provoking takeaways on the problem of sophistication imbalance in addition to ADASYN.
As we appeared into the impression of sophistication imbalance on our studying fashions, the proportions of False Negatives in our unbalanced take a look at knowledge signified that each random forest and logistic regression predict with the identical sensitivities to class imbalance. Apparently sufficient, ADASYN appeared to have an effect on the outcomes in a different way between studying fashions because the ‘butterfly’ graphs point out with each higher and decrease laterals.
When implementing ADASYN on each fashions, knowledge confirmed that random forest usually had secure predictions whatever the synthesized ratio used, whereas logistic regression fashions tended to be impacted extra by numerous ratios. It is a phenomenon that was outdoors the scope of this work however shall be examined sooner or later.
Maybe our most significant discovery have been the ADASYN-assisted conversions on the atomic stage over an unbalanced mannequin. The idea of lateral transfers from FN-TP and TN-FP created by ADASYN could be extraordinarily advantageous when deciding whether or not the algorithm ought to or shouldn’t be used to steadiness a dataset, and in addition goes to indicate simply how impactful ADASYN could be when utilized to enterprise analytics.
Now we have proven that the ultimate formation of the confusion matrix is just not on account of a collapsing wave operate — I’m petting Schrodinger’s cat proper now! And whereas it’s a mechanical phenomenon, the simplicity and universality of the TN-FP and FN-TP conversions are extraordinary.
We are able to now view ADASYN by means of a clearer lens, one from which we are able to higher analyze our fashions and obtain extra significant outcomes.
Future Analysis
Future analysis into class imbalance will discover mannequin sensitivity additional to find fashions which can be resistant. Repeating this experimental design with totally different studying fashions, akin to help vector machines and boosted bushes, and totally different imbalance algorithms, akin to SMOTE, KMeansSMOTE, BorderlineSMOTE, and so forth. may show fascinating. Additionally, understanding reverse transfers is on the agenda, particularly the 2 datasets with excessive results. Moreover, we’ll search to grasp the quantized ranges that seem within the ratio plots, and in the event that they develop with different imbalance algorithms.
References
Abu-Mostafa, Y. S., Magdon-Ismail, M., & Lin, H.-T. (2012). Studying from knowledge (Vol. 4). AMLBook New York, NY, USA
Chicco, D., & Jurman, G. (2020). The benefits of the Matthews correlation coefficient (MCC) over F1 rating and accuracy in binary classification analysis. BMC genomics, 21(1), 6. https://doi.org/10.1186/s12864-019-6413-7
Shmueli, G., Bruce, P. C., Gedeck, P., & Patel, N. R. (2019). Information mining for enterprise analytics: ideas, strategies and purposes in Python. John Wiley & Sons.
He, H., Bai, Y., Garcia, E. A., & Li, S. (2008, June). ADASYN: Adaptive artificial sampling method for imbalanced studying. In 2008 IEEE worldwide joint convention on neural networks (IEEE world congress on computational intelligence) (pp. 1322–1328). IEEE.
Contact Data:
Dr. David Guggenheim: LinkedIn Profile, dguggen@gmail.com
Srish Tirumalai: LinkedIn Profile, stirumalai1@gmail.com

{kind=link}