Replace 16.10.2020: Added Chinese language and Spanish translations.
This publish expands on the NAACL 2019 tutorial on Switch Studying in NLP. The tutorial was organized by Matthew Peters, Swabha Swayamdipta, Thomas Wolf, and me. On this publish, I spotlight key insights and takeaways and supply updates based mostly on current work. You may see the construction of this publish under:
The slides, a Colaboratory pocket book, and code of the tutorial can be found on-line.
For an outline of what switch studying is, take a look at this weblog publish. Our go-to definition all through this publish would be the following, which is illustrated within the diagram under:
Switch studying is a method to extract data from a supply setting and apply it to a unique goal setting.
Within the span of little greater than a 12 months, switch studying within the type of pretrained language fashions has grow to be ubiquitous in NLP and has contributed to the state-of-the-art on a variety of duties. Nevertheless, switch studying shouldn’t be a current phenomenon in NLP. One illustrative instance is progress on the duty of Named Entity Recognition (NER), which could be seen under.
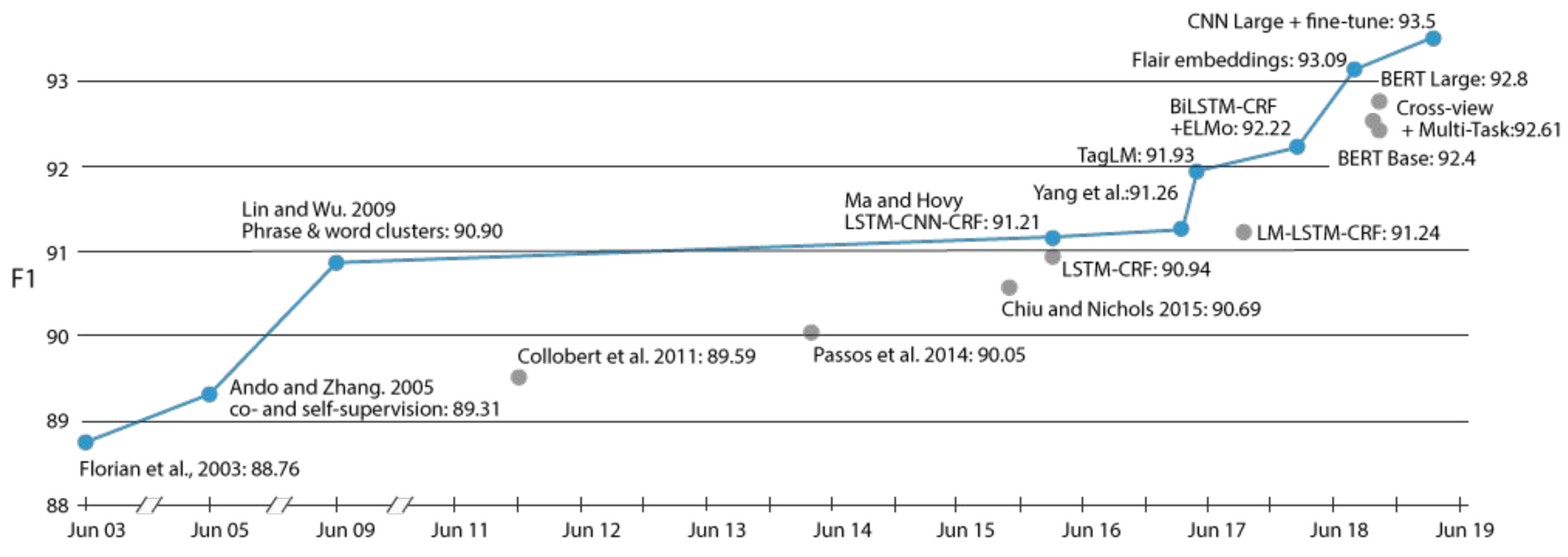
All through its historical past, many of the main enhancements on this process have been pushed by completely different types of switch studying: from early self-supervised studying with auxiliary duties (Ando and Zhang, 2005) and phrase & phrase clusters (Lin and Wu, 2009) to the language mannequin embeddings (Peters et al., 2017) and pretrained language fashions (Peters et al., 2018; Akbik et al., 2018; Baevski et al., 2019) of current years.
There are various kinds of switch studying frequent in present NLP. These could be roughly labeled alongside three dimensions based mostly on a) whether or not the supply and goal settings take care of the identical process; and b) the character of the supply and goal domains; and c) the order through which the duties are realized. A taxonomy that highlights the variations could be seen under:
Sequential switch studying is the shape that has led to the most important enhancements thus far. The overall follow is to pretrain representations on a big unlabelled textual content corpus utilizing your methodology of alternative after which to adapt these representations to a supervised goal process utilizing labelled information as could be seen under.
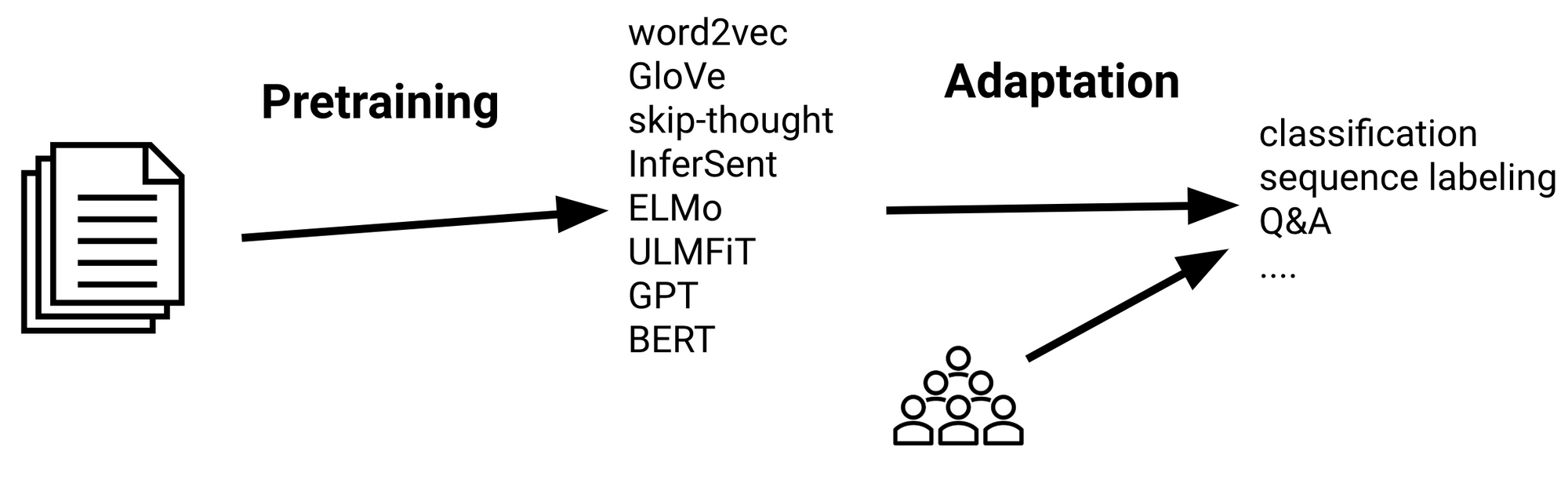
Main themes
A number of main themes could be noticed in how this paradigm has been utilized:
From phrases to words-in-context Over time, representations incorporate extra context. Early approaches reminiscent of word2vec (Mikolov et al., 2013) realized a single illustration for each phrase unbiased of its context. Later approaches then scaled these representations to sentences and paperwork (Le and Mikolov, 2014; Conneau et al., 2017). Present approaches be taught phrase representations that change based mostly on the phrase’s context (McCann et al., 2017; Peters et al., 2018).
LM pretraining Many profitable pretraining approaches are based mostly on variants of language modelling (LM). Benefits of LM are that it doesn’t require any human annotation and that many languages have sufficient textual content out there to be taught cheap fashions. As well as, LM is flexible and allows studying each sentence and phrase representations with quite a lot of goal features.
From shallow to deep Over the past years, state-of-the-art fashions in NLP have grow to be progressively deeper. As much as two years in the past, the state-of-the-art on most duties was a 2-3 layer deep BiLSTM, with machine translation being an outlier with 16 layers (Wu et al., 2016). In distinction, present fashions like BERT-Giant and GPT-2 encompass 24 Transformer blocks and up to date fashions are even deeper.
Pretraining vs goal process The selection of pretraining and goal duties is carefully intertwined. As an example, sentence representations usually are not helpful for word-level predictions, whereas span-based pretraining is necessary for span-level predictions. On the entire, for the most effective goal efficiency, it’s helpful to decide on an analogous pretraining process.
Why does language modelling work so properly?
The outstanding success of pretrained language fashions is stunning. One motive for the success of language modelling could also be that it’s a very tough process, even for people. To have any likelihood at fixing this process, a mannequin is required to find out about syntax, semantics, in addition to sure details in regards to the world. Given sufficient information, a lot of parameters, and sufficient compute, a mannequin can do an inexpensive job. Empirically, language modelling works higher than different pretraining duties reminiscent of translation or autoencoding (Zhang et al. 2018; Wang et al., 2019).
A current predictive-rate distortion (PRD) evaluation of human language (Hahn and Futrell, 2019) means that human language—and language modelling—has infinite statistical complexity however that it may be approximated properly at decrease ranges. This remark has two implications: 1) We are able to receive good outcomes with comparatively small fashions; and a pair of) there’s lots of potential for scaling up our fashions. For each implications we’ve empirical proof, as we are able to see within the subsequent sections.
Pattern effectivity
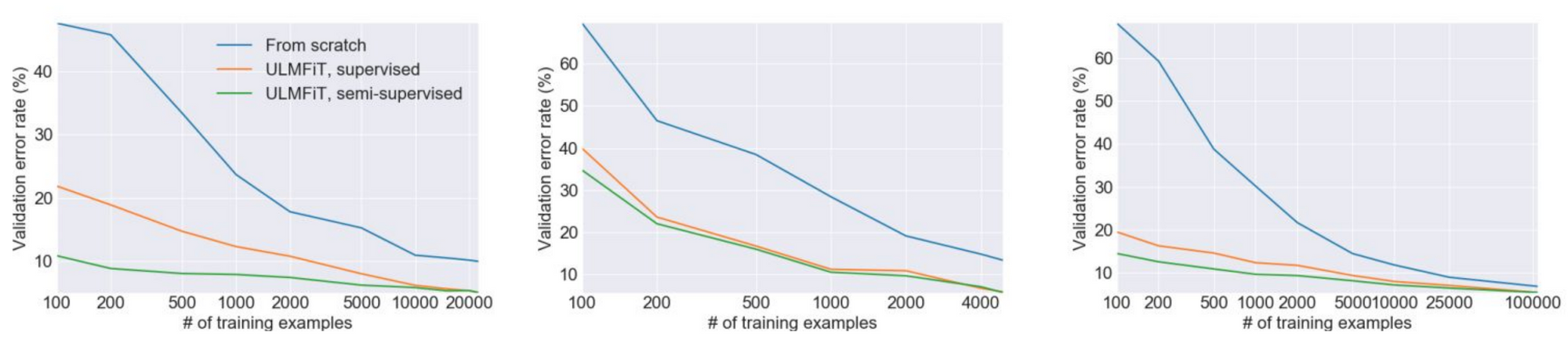
One of many essential advantages of pretraining is that it reduces the necessity for annotated information. In follow, switch studying has usually been proven to attain related efficiency in comparison with a non-pretrained mannequin with 10x fewer examples or extra as could be seen under for ULMFiT (Howard and Ruder, 2018).
Scaling up pretraining
Pretrained representations can typically be improved by collectively growing the variety of mannequin parameters and the quantity of pretraining information. Returns begin to diminish as the quantity of pretraining information grows enormous. Present efficiency curves such because the one under, nevertheless, don’t point out that we’ve reached a plateau. We are able to thus count on to see even greater fashions skilled on extra information.
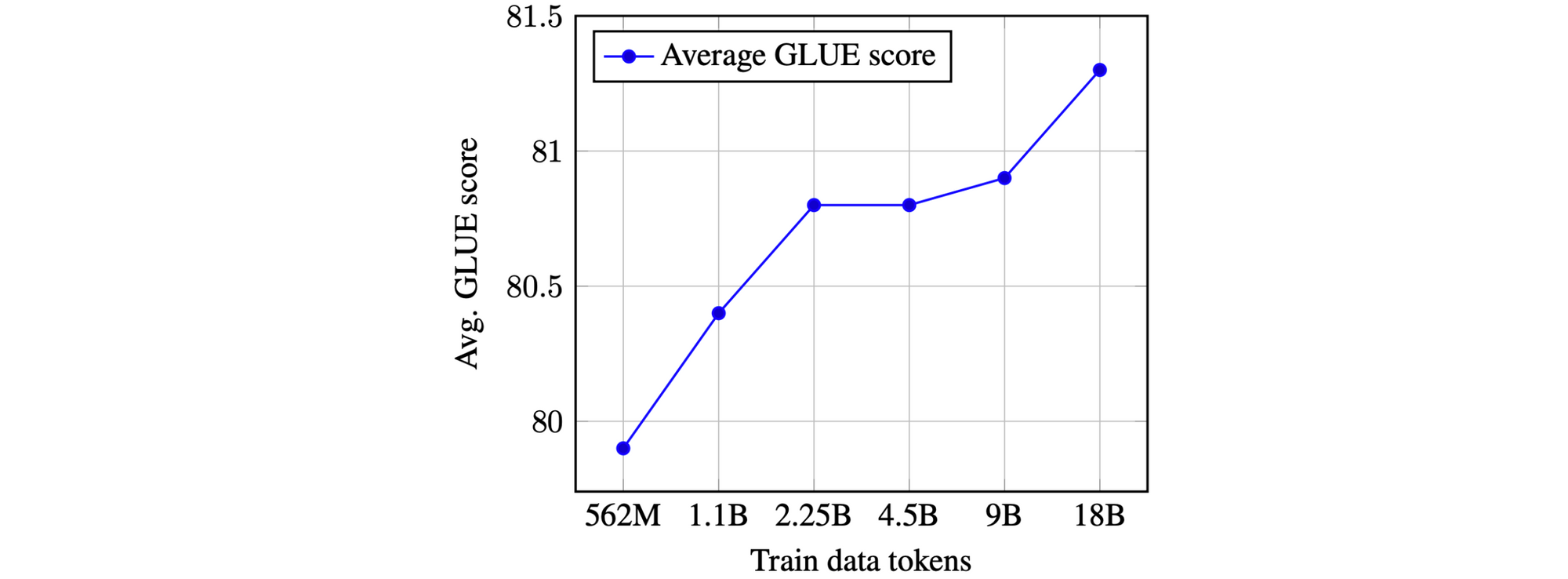
Latest examples of this pattern are ERNIE 2.0, XLNet, GPT-2 8B, and RoBERTa. The latter particularly finds that merely coaching BERT for longer and on extra information improves outcomes, whereas GPT-2 8B reduces perplexity on a language modelling dataset (although solely by a relatively small issue).
Cross-lingual pretraining
A significant promise of pretraining is that it could actually assist us bridge the digital language divide and might allow us be taught NLP fashions for extra of the world’s 6,000 languages. A lot work on cross-lingual studying has centered on coaching separate phrase embeddings in numerous languages and studying to align them (Ruder et al., 2019). In the identical vein, we are able to be taught to align contextual representations (Schuster et al., 2019). One other frequent methodology is to share a subword vocabulary and prepare one mannequin on many languages (Devlin et al., 2019; Artetxe and Schwenk, 2019; Mulcaire et al., 2019; Lample and Conneau, 2019). Whereas that is simple to implement and is a powerful cross-lingual baseline, it results in under-representation of low-resource languages (Heinzerling and Strube, 2019). Multilingual BERT particularly has been the topic of a lot current consideration (Pires et al., 2019; Wu and Dredze, 2019). Regardless of its sturdy zero-shot efficiency, devoted monolingual language fashions usually are aggressive, whereas being extra environment friendly (Eisenschlos et al., 2019).
Sensible issues
Pretraining is cost-intensive. Pretraining the Transformer-XL model mannequin we used within the tutorial takes 5h–20h on 8 V100 GPUs (a couple of days with 1 V100) to succeed in an excellent perplexity. Sharing pretrained fashions is thus crucial. Pretraining is comparatively strong to the selection of hyper-parameters—aside from needing a studying price warm-up for transformers. As a common rule, your mannequin mustn’t have sufficient capability to overfit in case your dataset is giant sufficient. Masked language modeling (as in BERT) is often 2-4 occasions slower to coach than commonplace LM as masking solely a fraction of phrases yields a smaller sign.
Representations have been proven to be predictive of sure linguistic phenomena reminiscent of alignments in translation or syntactic hierarchies. Higher efficiency has been achieved when pretraining with syntax; even when syntax shouldn’t be explicitly encoded, representations nonetheless be taught some notion of syntax (Williams et al. 2018). Latest work has moreover proven that data of syntax could be distilled effectively into state-of-the-art fashions (Kuncoro et al., 2019). Community architectures typically decide what’s in a illustration. As an example, BERT has been noticed to seize syntax (Tenney et al., 2019; Goldberg, 2019). Completely different architectures present completely different layer-wise developments by way of what info they seize (Liu et al., 2019).
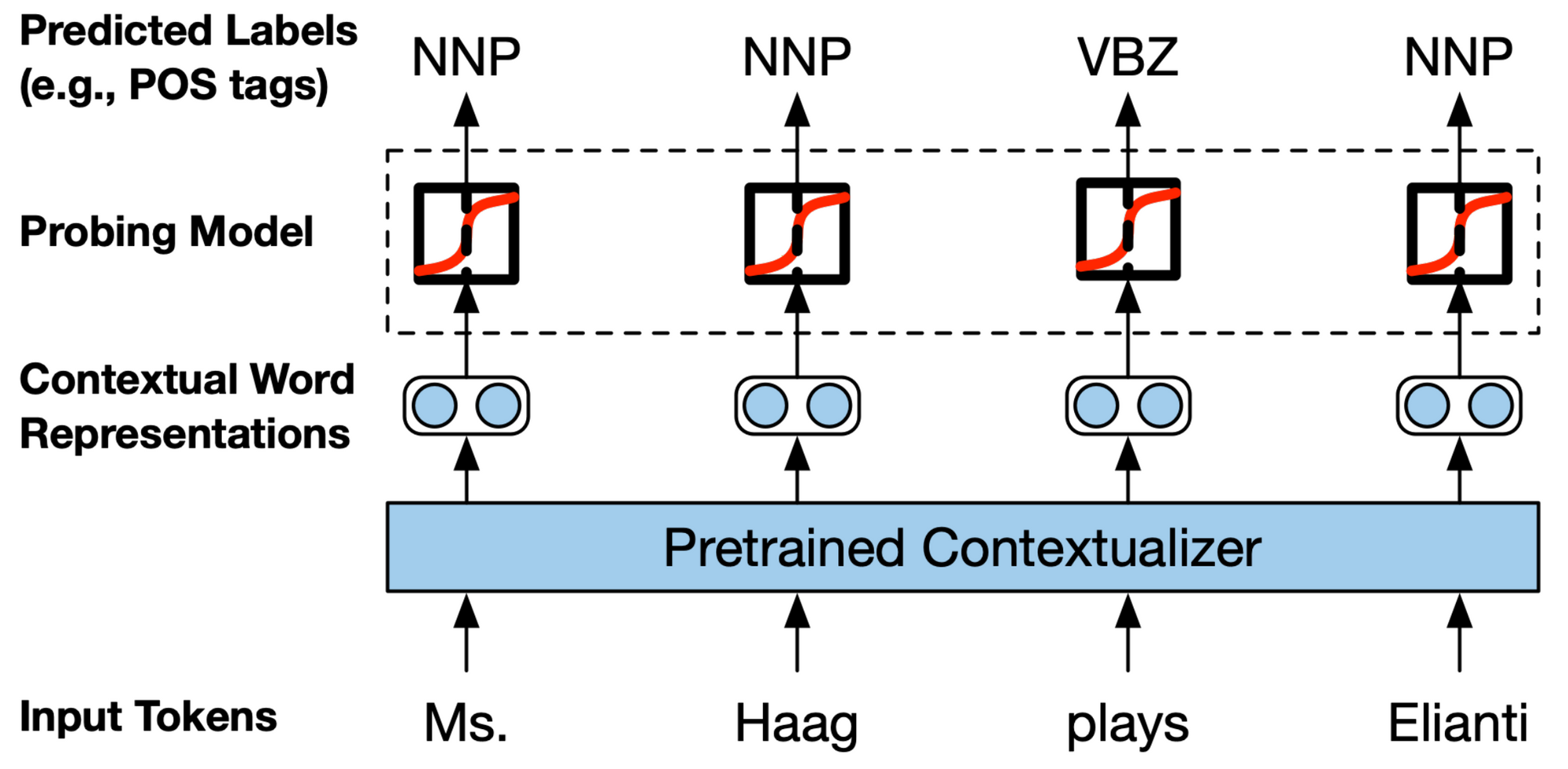
The data {that a} mannequin captures additionally relies upon the way you have a look at it: Visualizing activations or consideration weights supplies a chicken’s eye view of the mannequin’s data, however focuses on a couple of samples; probes that prepare a classifier on prime of realized representations in an effort to predict sure properties (as could be seen above) uncover corpus-wide particular traits, however could introduce their very own biases; lastly, community ablations are nice for bettering the mannequin, however could also be task-specific.
For adapting a pretrained mannequin to a goal process, there are a number of orthogonal instructions we are able to make choices on: architectural modifications, optimization schemes, and whether or not to acquire extra sign.
Architectural modifications
For architectural modifications, the 2 common choices we’ve are:
a) Preserve the pretrained mannequin internals unchanged This may be so simple as including a number of linear layers on prime of a pretrained mannequin, which is usually finished with BERT. As a substitute, we are able to additionally use the mannequin output as enter to a separate mannequin, which is commonly helpful when a goal process requires interactions that aren’t out there within the pretrained embedding, reminiscent of span representations or modelling cross-sentence relations.
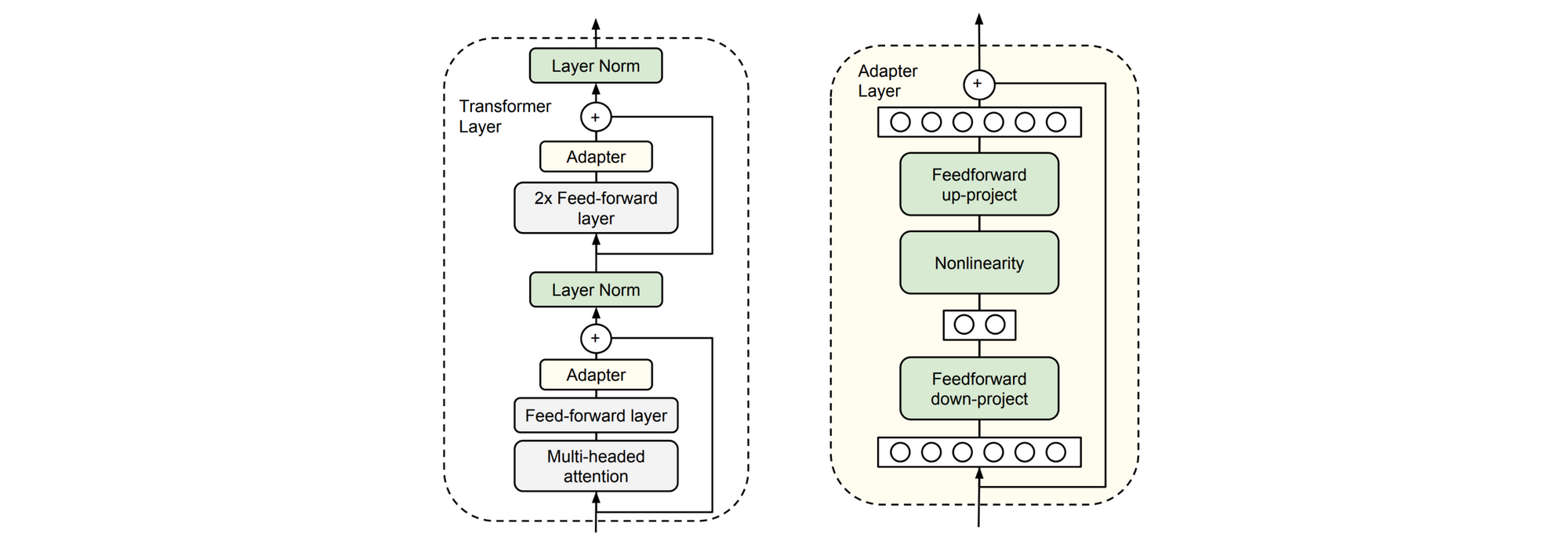
b) Modify the pretrained mannequin inner structure One motive why we would need to do that is in an effort to adapt to a structurally completely different goal process reminiscent of one with a number of enter sequences. On this case, we are able to use the pretrained mannequin to initialize as a lot as attainable of a structurally completely different goal process mannequin. We’d additionally need to apply task-specific modifications reminiscent of including skip or residual connections or consideration. Lastly, modifying the goal process parameters could cut back the variety of parameters that must be fine-tuned by including bottleneck modules (“adapters”) between the layers of the pretrained mannequin (Houlsby et al., 2019; Stickland and Murray, 2019).
Optimization schemes
By way of optimizing the mannequin, we are able to select which weights we must always replace and the way and when to replace these weights.
Which weights to replace
For updating the weights, we are able to both tune or not tune (the pretrained weights):
a) Don’t change the pretrained weights (function extraction) In follow, a linear classifier is skilled on prime of the pretrained representations. The most effective efficiency is often achieved through the use of the illustration not simply of the highest layer, however studying a linear mixture of layer representations (Peters et al., 2018, Ruder et al., 2019). Alternatively, pretrained representations can be utilized as options in a downstream mannequin. When including adapters, solely the adapter layers are skilled.
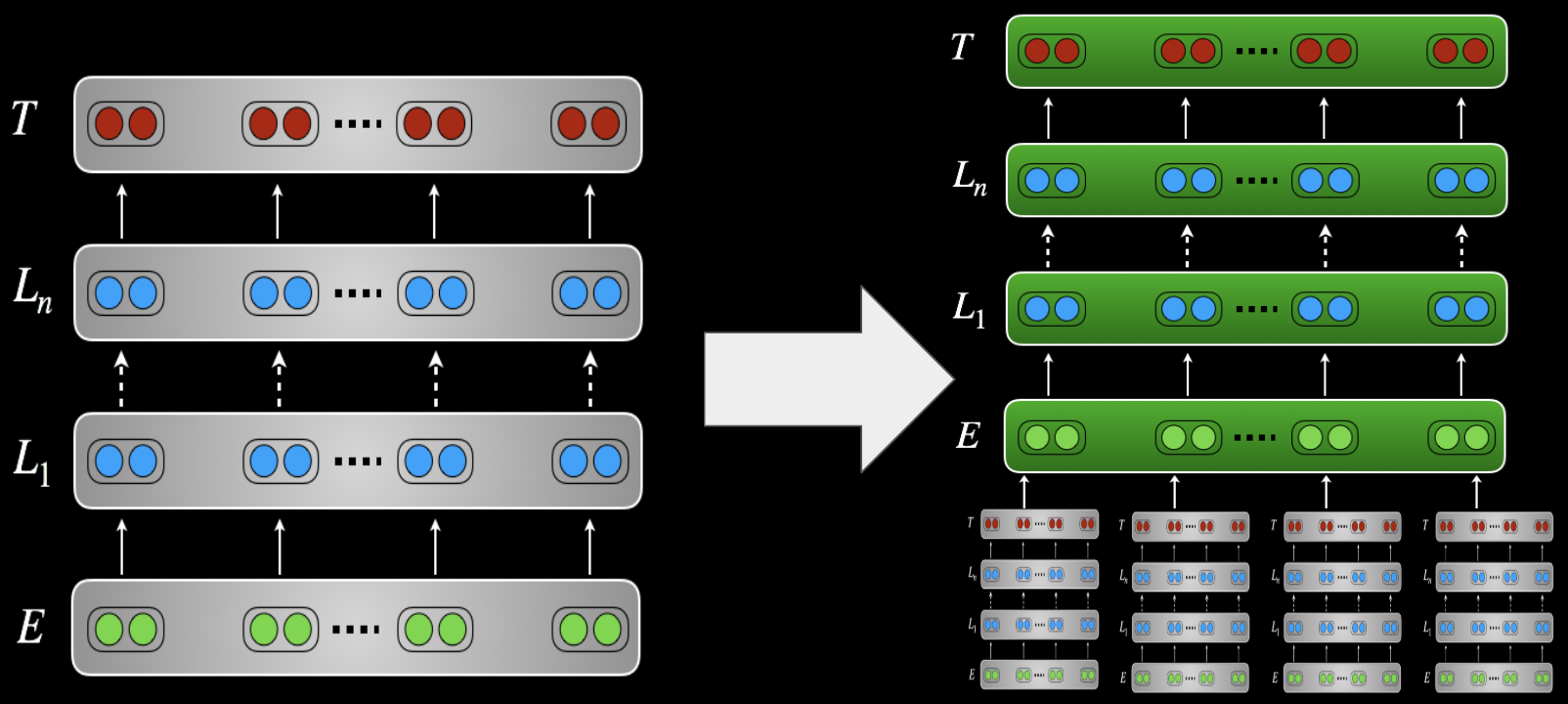
b) Change the pretrained weights (fine-tuning) The pretrained weights are used as initialization for parameters of the downstream mannequin. The entire pretrained structure is then skilled in the course of the adaptation part.
How and when to replace the weights
The principle motivation for selecting the order and learn how to replace the weights is that we need to keep away from overwriting helpful pretrained info and maximize optimistic switch. Associated to that is the idea of catastrophic forgetting (McCloskey & Cohen, 1989; French, 1999), which happens if a mannequin forgets the duty it was initially skilled on. In most settings, we solely care in regards to the efficiency on the goal process, however this may increasingly differ relying on the appliance.
A tenet for updating the parameters of our mannequin is to replace them progressively from top-to-bottom in time, in depth, or in comparison with a pretrained mannequin:
a) Progressively in time (freezing) The principle instinct is that coaching all layers on the identical time on information of a unique distribution and process could result in instability and poor options. As a substitute, we prepare layers individually to offer them time to adapt to the brand new process and information. This goes again to layer-wise coaching of early deep neural networks (Hinton et al., 2006; Bengio et al., 2007). Latest approaches (Felbo et al., 2017; Howard and Ruder, 2018; Chronopoulou et al., 2019) principally differ within the combos of layers which might be skilled collectively; all prepare all parameters collectively in the long run. Unfreezing has not been investigated intimately for Transformer fashions.
b) Progressively in depth (decrease studying charges) We need to use decrease studying charges to keep away from overwriting helpful info. Decrease studying charges are significantly necessary in decrease layers (as they seize extra common info), early in coaching (because the mannequin nonetheless must adapt to the goal distribution), and late in coaching (when the mannequin is near convergence). To this finish, we are able to use discriminative fine-tuning (Howard and Ruder, 2018), which decays the educational price for every layer as could be seen under. With a view to keep decrease studying charges early in coaching, a triangular studying price schedule can be utilized, which is often known as studying price warm-up in Transformers. Liu et al. (2019) lately counsel that warm-up reduces variance within the early stage of coaching.
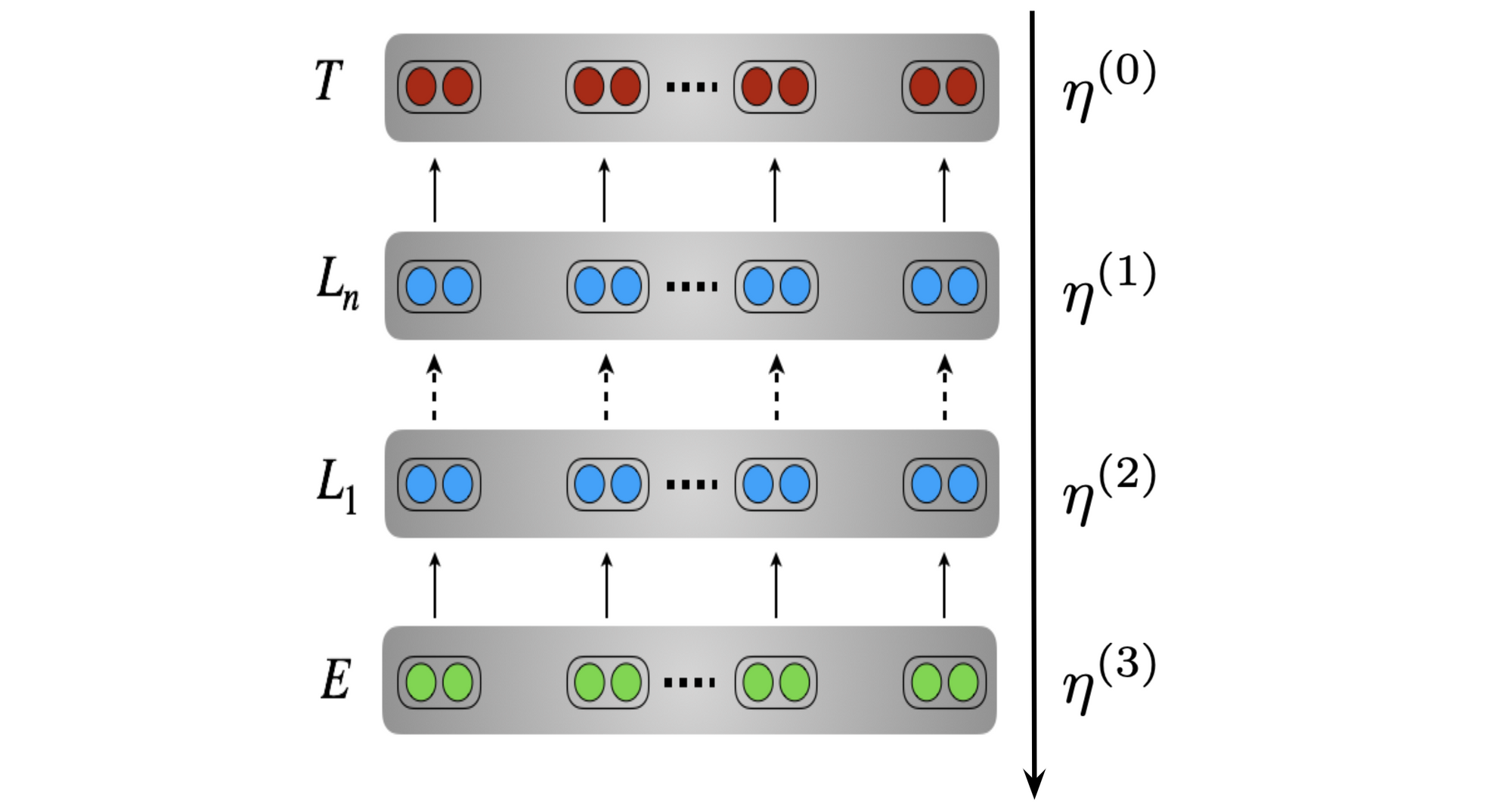
c) Progressively vs. a pretrained mannequin (regularization) One method to reduce catastrophic forgetting is to encourage goal mannequin parameters to remain near the parameters of the pretrained mannequin utilizing a regularization time period (Wiese et al., CoNLL 2017, Kirkpatrick et al., PNAS 2017).
Commerce-offs and sensible issues
Generally, the extra parameters you could prepare from scratch the slower your coaching might be. Characteristic extraction requires including extra parameters than fine-tuning (Peters et al., 2019), so is often slower to coach. Characteristic extraction, nevertheless, is extra space-efficient when a mannequin must be tailored to many duties because it solely requires storing one copy of the pretrained mannequin in reminiscence. Adapters strike a stability by including a small variety of extra parameters per process.
By way of efficiency, no adaptation methodology is clearly superior in each setting. If supply and goal duties are dissimilar, function extraction appears to be preferable (Peters et al., 2019). In any other case, function extraction and fine-tuning usually carry out related, although this is dependent upon the price range out there for hyper-parameter tuning (fine-tuning could usually require a extra in depth hyper-parameter search). Anecdotally, Transformers are simpler to fine-tune (much less delicate to hyper-parameters) than LSTMs and will obtain higher efficiency with fine-tuning.
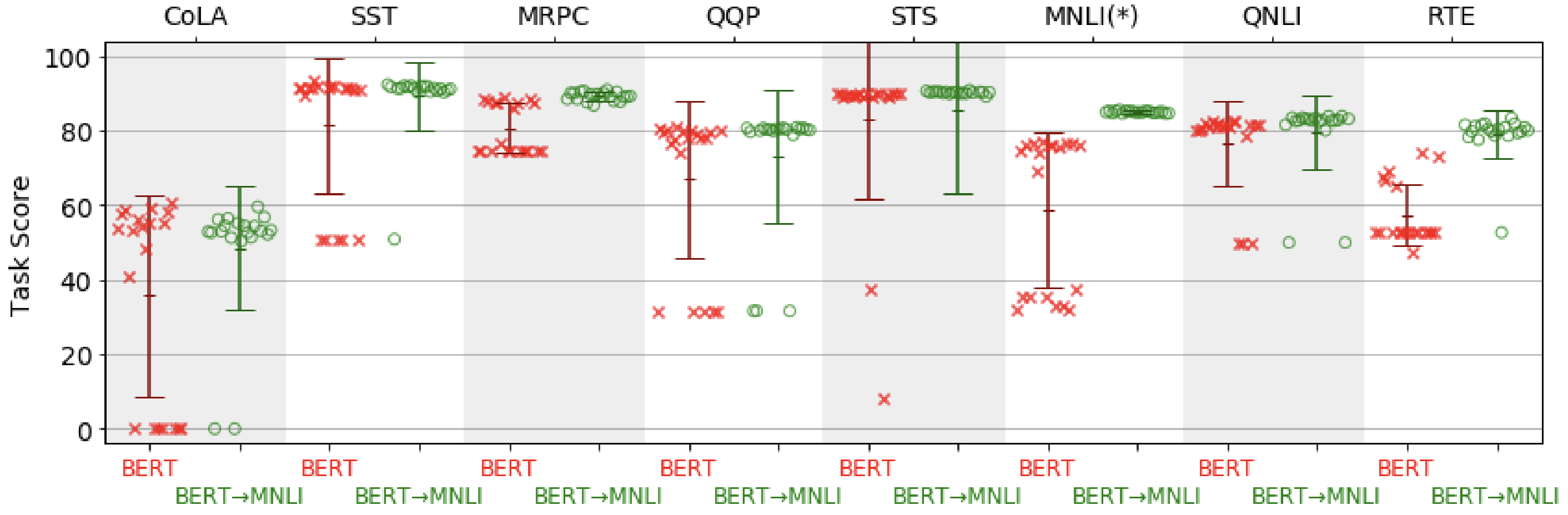
Nevertheless, giant pretrained fashions (e.g. BERT-Giant) are liable to degenerate efficiency when fine-tuned on duties with small coaching units. In follow, the noticed conduct is commonly “on-off”: the mannequin both works very properly or doesn’t work in any respect as could be seen within the determine under. Understanding the situations and causes of this conduct is an open analysis query.
Getting extra sign
The goal process is commonly a low-resource process. We are able to usually enhance the efficiency of switch studying by combining a various set of alerts:
Sequential adaptation If associated duties can be found, we are able to fine-tune our mannequin first on a associated process with extra information earlier than fine-tuning it on the goal process. This
helps significantly for duties with restricted information and related duties (Phang et al., 2018) and improves pattern effectivity on the goal process (Yogatama et al., 2019).
Multi-task fine-tuning Alternatively, we are able to additionally fine-tune the mannequin collectively on associated duties along with the goal process. The associated process may also be an unsupervised auxiliary process. Language modelling is an efficient alternative for this and has been proven to assist even with out pretraining (Rei et al., 2017). The duty ratio can optionally be annealed to de-emphasize the auxiliary process in direction of the top of coaching (Chronopoulou et al., NAACL 2019). Language mannequin fine-tuning is used as a separate step in ULMFiT (Howard and Ruder, 2018). Just lately, multi-task fine-tuning has led to enhancements even with many goal duties (Liu et al., 2019, Wang et al., 2019).
Dataset slicing Somewhat than fine-tuning with auxiliary duties, we are able to use auxiliary heads which might be skilled solely on specific subsets of the info. To this finish, we’d first analyze the errors of the mannequin, use heuristics to routinely determine difficult subsets of the coaching information, after which prepare auxiliary heads collectively with essential head.
Semi-supervised studying We are able to additionally use semi-supervised studying strategies to make our mannequin’s predictions extra constant by perturbing unlabelled examples. The perturbation could be noise, masking (Clark et al., 2018), or information augmentation, e.g. back-translation (Xie et al., 2019).
Ensembling To enhance efficiency the predictions of fashions fine-tuned with completely different hyper-parameters, fine-tuned with completely different pretrained fashions, or skilled on completely different goal duties or dataset splits could also be mixed.
Distilling Lastly, giant fashions or ensembles of fashions could also be distilled right into a single, smaller mannequin. The mannequin may also be loads easier (Tang et al., 2019) or have a unique inductive bias (Kuncoro et al., 2019). Multi-task fine-tuning may also be mixed with distillation (Clark et al., 2019).
Pretraining large-scale fashions is expensive, not solely by way of computation but in addition by way of the environmental affect (Strubell et al., 2019). Each time attainable, it is best to make use of open-source fashions. If you could prepare your personal fashions, please share your pretrained fashions with the neighborhood.
Frameworks and libraries
For sharing and accessing pretrained fashions, completely different choices can be found:
Hubs Hubs are central repositories that present a typical API for accessing pretrained fashions. The 2 most typical hubs are TensorFlow Hub and PyTorch Hub. Hubs are typically easy to make use of; nevertheless, they act extra like a black-box because the supply code of the mannequin can’t be simply accessed. As well as, modifying the internals of a pretrained mannequin structure could be tough.
Creator launched checkpoints Checkpoint information typically comprise all of the weights of a pretrained mannequin. In distinction to hub modules, the mannequin graph nonetheless must be created and mannequin weights must be loaded individually. As such, checkpoint information are tougher to make use of than hub modules, however give you full management over the mannequin internals.
Third-party libraries Some third-party libraries like AllenNLP, quick.ai, and pytorch-transformers present easy accessibility to pretrained fashions. Such libraries usually allow quick experimentation and canopy many commonplace use circumstances for switch studying.
For examples of how such fashions and libraries can be utilized for downstream duties, take a look on the code snippets within the slides, the Colaboratory pocket book, and the code.
There are lots of open issues and attention-grabbing future analysis instructions. Beneath is simply an up to date choice. For extra pointers, take a look at the slides.
Shortcomings of pretrained language fashions
Pretrained language fashions are nonetheless unhealthy at fine-grained linguistic duties (Liu et al., 2019), hierarchical syntactic reasoning (Kuncoro et al., 2019), and customary sense (once you really make it tough; Zellers et al., 2019). They nonetheless fail at pure language era, particularly sustaining long-term dependencies, relations, and coherence. In addition they are inclined to overfit to floor kind info when fine-tuned and might nonetheless principally be seen as ‘fast floor learners’.
As we’ve famous above, significantly giant fashions which might be fine-tuned on small quantities of knowledge are tough to optimize and undergo from excessive variance. Present pretrained language fashions are additionally very giant. Distillation and pruning are two methods to take care of this.
Pretraining duties
Whereas the language modelling goal has proven to be efficient empirically, it has its weaknesses. These days, we’ve seen that bidirectional context and modelling contiguous phrase sequences is especially necessary. Possibly most significantly, language modelling encourages a give attention to syntax and phrase co-occurrences and solely supplies a weak sign for capturing semantics and long-term context. We are able to take inspiration from different types of self-supervision. As well as, we are able to design specialised pretraining duties that explicitly be taught sure relationships (Joshi et al., 2019, Solar et al., 2019).
On the entire, it’s tough to be taught sure kinds of info from uncooked textual content. Latest approaches incorporate structured data (Zhang et al., 2019; Logan IV et al., 2019) or leverage a number of modalities (Solar et al., 2019; Lu et al., 2019) as two potential methods to mitigate this drawback.
Quotation
Should you discovered this publish useful, contemplate citing the tutorial as:
@inproceedings{ruder2019transfer,
title={Switch Studying in Pure Language Processing},
creator={Ruder, Sebastian and Peters, Matthew E and Swayamdipta, Swabha and Wolf, Thomas},
booktitle={Proceedings of the 2019 Convention of the North American Chapter of the Affiliation for Computational Linguistics: Tutorials},
pages={15--18},
12 months={2019}
}Translations
This text has been translated into the next languages:

{kind=link}