
From tail to go, we focus on the grotesque Information innards that create lovely graphics, experiences, and insights
A layman in information strolling into an information undertaking architectural assembly is certain to be shortly overwhelmed with engineering, math, analysis, and statistics. Couple that with overheated discussions about mannequin deployment and GPUs that refuse to work with the code, and you’ve got the proper data storm.
On the finish of the day, it’ll be all meshed collectively right into a information sausage, the place you seemingly lose observe of all of the separate elements however continues to be very a lot scrumptious to devour.
To totally perceive the final means of an information undertaking creation, we have to break up it into areas of concern: what’s the enter and output of every step, who’s accountable, and what instruments ought to we all know to work successfully.
However first, let’s get some descriptions out of the way in which: what’s an information undertaking? In a nutshell, the target of an information undertaking is to course of uncooked information and enrich it utilizing some sort of aggregation/mixture/statistical modeling and ship it in a approach the ultimate person can perceive.
We might additional separate an information undertaking: one such separation is within the OSEMN framework (Get hold of, Scrub, Discover, Mannequin, iNterpret) which takes care of virtually every thing described by the abstraction above. It’s an effective way for an information scientist to create standalone tasks, however it nonetheless lacks a path from its growth to manufacturing.
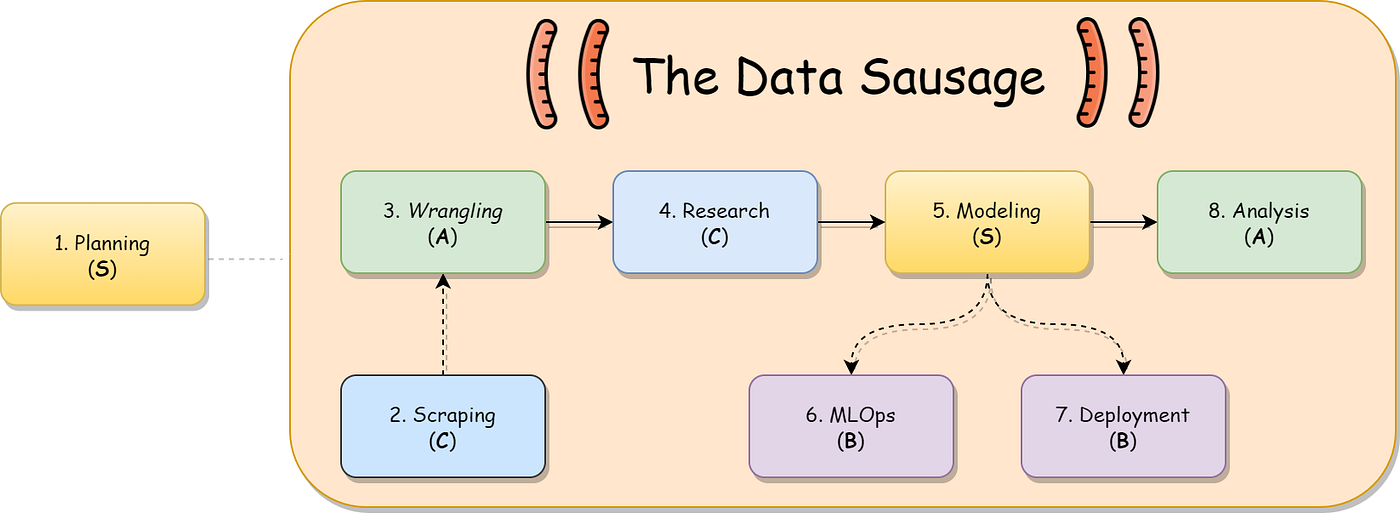
Let’s dissect the aforementioned sausage. You might discover that there’s an overlap between the OSEMN steps and people mentioned right here on this story:
- All of it begins with the planning part, the place you describe the target of your undertaking, the inputs and outputs of every processing step, and the roles of your group in them.
- If we don’t have the uncooked information at hand we should scrape (Get hold of) it from someplace, be it from an API or a webpage.
- Formatting that uncooked information is completed in the course of the wrangling (Scrub) part.
- Typically we want that state-of-the-art mannequin, and that’s made in the course of the analysis part.
- With every thing in place, we will begin modeling (Discover/Mannequin).
- Off to the engineering a part of city! We have to deal with the lifecycle of our mannequin utilizing MLOps…
- And deploy our resolution in a production-level setting.
- Lastly, we collect our enriched information and analyze (iNterpret) it utilizing dashboards and experiences.
Planning (S — Should-have)
Planning an information undertaking means placing on paper the street that uncooked data must path as a way to turn out to be actionable data. That is performed via conferences and a superb quantity of documentation (textual and visible) describing what are the enterprise wants, the way you translate these wants via science and engineering work, what’s the general scope of the undertaking, and who’s accountable for what.
This can be a group effort: the scientist is aware of what fashions could possibly be used for the duty; the engineer is aware of handle information and ship it from one course of to the opposite; the PM scopes and timeboxes. A generalist is normally extra useful right here in comparison with a specialist: linking know-how from a number of realms can lower the possibility of making siloed institutional data.
The toolkit of somebody who’s concerned in planning contains:
- Undertaking administration instruments (JIRA, Taiga, Notion) to plan out duties and goals;
- Diagramming instruments (Miro, Lucidchart, diagrams.internet) to create visible documentation;
- A undertaking description template (Request For Feedback) to comply with via. The hyperlink under is an instance of an information science undertaking RFC: the summary a part of the modeling could be very effectively described, however it might additionally use timeboxing and a nicer step-by-step implementation description.
Scraping (C — Situational)
In some circumstances, you received’t have the uncooked information you want at hand. This implies it’s worthwhile to make a course of that scrapes that information from an information vendor via an API, and even from the Internet itself.
That is one thing that’s extra associated to the software program engineering of us however generally is a good asset to an information scientist that’s serious about making PoCs out of mainly something they need (respecting your nation’s legal guidelines about private information, in fact).
The toolkit of a scraper contains:
- A scraping framework (Scrapy, Puppeteer) that may be deployed simply;
- A language to question HTML paperwork (XPath or CSS);
- Pipelines to save lots of uncooked information domestically or within the cloud (Scrapy Pipelines, AWS Firehose, GCP Dataflow);
- Uncooked information question and administration (AWS Glue/Athena).
Wrangling (A — Helps your day by day work)
The act of wrangling information means punching the information till it matches your database modeling. Normalization, mapping, cleansing, structuring… All of it falls below the umbrella of information wrangling.
Information engineers are normally those which might be principally accountable for your fundamental information wrangling actions, managing the lineage of your tables and their structural integrity.
However we will additionally examine this exercise to the pre-processing information scientists normally do over their datasets as a way to practice and predict fashions: L2 normalization, one-hot encoding… it’s native wrangling (used solely within the mannequin context) as an alternative of world wrangling (utilized by anybody within the firm).
The toolkit of a wrangler contains boots, a lasso, and:
- SQL. Most work of a wrangler shall be performed over SQL queries, deriving information via views and procedures, and basic optimization. Attending to know the syntax of a few databases (PostgreSQL, MySQL, Presto) and figuring out a software for managing your information mannequin (DBT) will bless your day by day life;
- Information manipulation libraries to your chosen language (e.g., Pandas for Python, Spark in Scala);
- Information validation ideas and instruments (Nice Expectations, Pytest).
Analysis (C — Situational)
Most information science tasks don’t must have state-of-the-art accuracy metrics. For those who do, we have to analysis and go deep into the educational papers and blogs to craft a mannequin that will get near the duty goal.
In principle, the sort of analysis must be performed by ML researchers and information scientists which might be targeted on that area of educational data. In follow, information scientists are normally anticipated to assist with different sides of the undertaking (wrangling, deployment, evaluation) and likewise do analysis, making information science growth a tad extra difficult.
Your day by day life as a researcher includes:
- Understanding search and catalog tutorial articles (Mendeley, arXiv, Google Scholar);
- Having some know-how of a neural community modeling framework (Pytorch, Tensorflow, Keras);
- Utilizing GPU-accelerated processing to hurry up these heavy networks (CUDA/NVIDIA, ROCm/AMD);
- Utilizing all of the instruments associated to modeling…
Modeling (S — Should-have)
That is the crux of the undertaking and the vast majority of the day by day lifetime of an information scientist: creating fashions that generate data from information. This may be performed utilizing ML for extra difficult duties, however can be performed utilizing fundamental statistics, aggregations, and variable combos! Typically an Excel sheet with a number of calculations might be the perfect resolution to your drawback.
However other than fundamental statistical data, what instruments do it’s worthwhile to do modeling?
- Fundamental modeling frameworks for widespread domains (scikit-learn to your run-of-the-mill modeling, spaCy for language processing, OpenCV for pc imaginative and prescient, and pre-trained mannequin libraries like Keras Purposes);
- Superior automation instruments to your day by day modeling duties (Pycaret and AutoML for pre-processing and mannequin choice, SweetViz for exploratory information evaluation);
- Information manipulation instruments like Pandas and Dask are wanted right here as effectively;
- Parallel processing is important if in case you have an excessive amount of information: Spark is the simplest solution to obtain that, and Databricks may help you with geared notebooks and managed clusters.
- Different pocket book serving instruments might be helpful as effectively (JupyterLab, Sagemaker).
MLOps
MLOps is the junction between Machine Studying and DevOps: instruments and methods that handle the total lifecycle of an information software. From information ingestion to deployment, it’s the glue that joins all of the steps on this story with observability practices, deployment insurance policies, and information validation.
That is one thing that everybody concerned in information tasks ought to know in passing: information scientists which might be conscious of MLOps will create maintainable fashions with correct logging, modular design, and experiment monitoring; information engineers will have the ability to simply orchestrate these fashions and deploy them in a steady style.
There are a few libraries and instruments that make MLOps approach simpler.
- The fundamentals of MLOps lie in storing your ML experiment parameters and outcomes. To take action, you should utilize Weights & Biases or mlflow: each are simply built-in into your mannequin coaching code and should yield attention-grabbing experiences proper out of the bat.
- In case you are utilizing Kubernetes in your ML pipelines, it is best to look to Kubeflow: it takes care of the total lifecycle of a mannequin utilizing all of the scalability of K8s.
- In case you are already utilizing Airflow in some capability, try Metaflow. It permits you to modularize your coaching steps utilizing DAG-like code.
- If you wish to focus on a cloud supplier, it’s also possible to go for their very own ML deployment suites like AWS Sagemaker or GCP Datalab.
Deployment
Within the Deployment stage, we have to get our mannequin to manufacturing grafting it to the present structure. That is primarily an information engineering duty, however information scientists have to be all the time able to work along with them to adapt their codes: putting in a GPU-powered library in a Docker setting, ensuring the AWS Batch job is utilizing 100% of the processing energy of its occasion.
One of the best ways to talent up on this step is figuring out the final archetypes of pipeline instruments and what would their parallels be in different clouds. Satish Chandra Gupta has an superior Medium article about it, go test it out!
- Often, ML-related issues ought to run in Docker pictures: numerous system and Python libraries should be pre-installed for a coaching/inference code to run correctly.
- You possibly can execute these codes in EC2/Compute machines by hand, wrap them in Serverless providers equivalent to AWS Batch or GCP Cloud Features, use exterior platforms equivalent to Databricks and set off notebooks via Airflow…
- To make your deployment appear to be a microservice, you may outline enter and output channels utilizing message queue methods equivalent to ActiveMQ, Kafka, SQS, Pub/Sub.
- To place this all in manufacturing, Infrastructure as Code (IaC) instruments are important for a sane CI/CD course of: Terraform and the Serverless bundle are nice companions to your infrastructure and software deploys.
Evaluation
It’s the top of the pipeline! With all this processed information, we will begin munching it into digestible dashboards and experiences so we will derive actionable insights from it. On this half, we’re capable of join enterprise metrics to modeling metrics: does our mannequin outcomes delivers to our shopper the characteristic we’re anticipating?
The duty for this half is especially on the fingers of information analysts, with talents that contain statistics (to grasp the information), dashboarding (to create experiences), and person expertise (to create good experiences). Information scientists are additionally a part of this course of via storytelling, explaining their mannequin outcomes and goals.
- The most effective information evaluation instruments are the suites we’re already conversant in: Tableau, Looker, PowerBI. These are expensive however well-worth their licensing charges. Apache Superset is an open-source various.
- Dashboarding instruments are additionally nice for the evaluation course of: I’ve personally used lots of Metabase, with connectors to all types of databases and a easy deployment script. You may as well be serious about Redash and Google Information Studio.
- However one of the best software for this step is just not a concrete one: enterprise area data is important to see the connections between the wants of the shoppers and potential data-related options.

{kind=link}