
Information Science
Simple to advanced SQL GROUP BY use-cases, in below 10 minutes

GROUP BY in SQL, Defined
SQL — Structured Question Language — is extensively used device to extract the information from relational database and rework it.
Information transformation is incomplete with out knowledge aggregation, which is necessary idea in SQL. And knowledge aggregation is inconceivable with out GROUP BY! Due to this fact, it is very important grasp GROUP BY to simply carry out all varieties of knowledge transformations and aggregations.
In SQL, GROUP BY is used for knowledge aggregation, utilizing mixture capabilities. similar to SUM(), MIN(), MAX(), AVG() and COUNT() .
However, why are aggregation operate used along side GROUP BY?
In SQL, a GROUP BY clause is used to group the rows collectively. So whenever you use mixture operate on a column, the consequence describes the information for that particular group of rows.
On this article, I’m explaining 5 examples of utilizing GROUP BY clause in SQL question which is able to assist you to make use of GROUP BY with none wrestle.
I stored this text fairly brief, so that you could end it rapidly and grasp one of many necessary ideas in SQL.
You may rapidly navigate to your favourite half utilizing this index.
· GROUP BY with Mixture Features
· GROUP BY with out Mixture Features
· GROUP BY with HAVING
· GROUP BY with ORDER BY
· GROUP BY with WHERE, HAVING and ORDER BY
Notice: I’m utilizing SQLite DB Browser and a self created Gross sales Information created utilizing Faker . You may get it on my Github repo at no cost below the MIT License!
It’s a easy 9999 x 11 dataset as beneath.

Okay, right here we go…
Nicely, earlier than going forward, all the time keep in mind beneath one rule of GROUP BY..
While you use GROUP BY in your SQL question, then every column in SELECT assertion have to be both current in GROUP BY clause or happen as parameter in an aggregated operate.
Now, let’s begin with the only use-case.
That is probably the most generally used situation, the place you apply mixture operate on a number of columns. As talked about above, GROUP BY merely teams the rows collectively which have comparable values within the columns laid out in it.
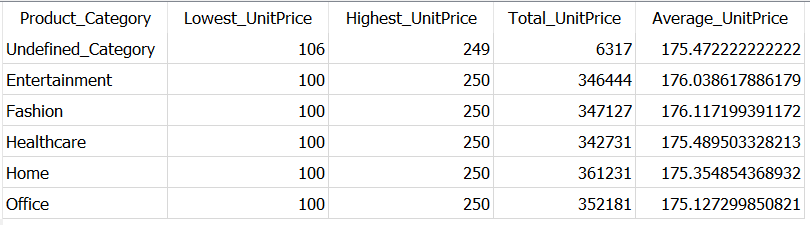
For an occasion, suppose, you need get statistical abstract of unit worth by every product class. This instance particularly explains use all the mixture capabilities.
You may get such statistical abstract utilizing the question —
SELECT Product_Category,
MIN(UnitPrice) AS Lowest_UnitPrice,
MAX(UnitPrice) AS Highest_UnitPrice,
SUM(UnitPrice) AS Total_UnitPrice,
AVG(UnitPrice) AS Average_UnitPrice
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category

As you see within the above question, you used two columns — Product_Category and UnitPrice — And the later is all the time utilized in a mixture capabilities. Due to this fact, GROUP BY clause comprises just one remaining column.
You may discover, the primary file in Product_Category is NULL, which suggests GROUP BY mixed all of the NULL values in Product_Category in single group. This aligns with the SQL normal as specified by Microsoft —
“If a grouping column comprises NULL values, all NULL values are thought of equal and they’re collected right into a single group.”
Additionally, by default, the consequence desk is ordered in Ascending order of the columns in GROUP BY with NULL (if current) on the high. Should you don’t need NULL to be a part of your consequence desk, you’ll be able to anytime use COALESCE operate and provides a significant title for NULL, as proven beneath.
SELECT COALESCE(Product_Category,'Undefined_Category') AS Product_Category,
MIN(UnitPrice) AS Lowest_UnitPrice,
MAX(UnitPrice) AS Highest_UnitPrice,
SUM(UnitPrice) AS Total_UnitPrice,
AVG(UnitPrice) AS Average_UnitPrice
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category
 An necessary level to notice right here —
An necessary level to notice right here —
Though
COALESCEis utilized on Product_Category column, you aren’t really aggregating values from this column. So, it have to be the a part of GROUP BY.
On this approach, you’ll be able to add as many columns you want within the SELECT assertion, apply mixture operate on some or all columns and point out the remaining column names within the GROUP BY clause, to get the specified outcomes.
Nicely, this was about utilizing GROUP BY together with aggregation operate. However, you can too use this clause with out mixture capabilities, as defined additional.
Though a lot of the occasions GROUP BY is used together with mixture capabilities, it might probably nonetheless nonetheless used with out mixture capabilities — to search out distinctive data.
For instance, suppose you need to retrieve all of the distinctive mixtures of Sales_Manager and Product_Category. Utilizing GROUP BY, that is very simple. All it is advisable do is, point out all of the column names in GROUP BY which you point out within the SELECT, as proven beneath.
SELECT Product_Category,
Sales_Manager
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category,
Sales_Manager

At this level, some may argue that, the identical outcomes may be obtained utilizing DISTINCT key phrase earlier than column names.
Nonetheless, listed below are the 2 important the explanation why you must select GROUP BY over DISTINCT to get distinctive data.
- Outcomes obtained by GROUP BY clause are by default ordered in ascending order. So, you don’t must type the data individually.
- DISTINCT may be costly if you find yourself engaged on dataset with hundreds of thousands of rows and your SQL question comprises JOINs
So, utilizing GROUP BY does an superior job to get distinctive data from the database effectively, even in case you are utilizing a number of JOINs within the question.
You may examine one other fascinating use-case of GROUP BY clause in one in every of my earlier article —
Shifting forward, let’s be taught extra about how one can restrict the output obtained by GROUP BY clause, in an environment friendly approach.
In SQL, HAVING works on the identical logic as WHERE clause, the one distinction is that it filters a bunch of data, fairly than filtering each different file.
For example suppose you need to get the distinctive data with Product class, gross sales supervisor & transport price, the place transport price is greater than 34.
This may be achieved utilizing WHERE in addition to HAVING clause as given beneath.
-- WHERE clauseSELECT Product_Category,
Sales_Manager,
Shipping_Cost
FROM Dummy_Sales_Data_v1
WHERE Shipping_Cost >= 34
GROUP BY Product_Category,
Sales_Manager,
Shipping_Cost-- HAVING clauseSELECT Product_Category,
Sales_Manager,
Shipping_Cost
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category,
Sales_Manager,
Shipping_Cost
HAVING Shipping_Cost >= 34

Though above each queries generate the identical output, the logic is completely totally different. The WHERE clause is executed earlier than GROUP BY, so primarily it scans complete dataset for the given situation.
Nonetheless, HAVING is executed after GROUP BY, so it scans comparatively small variety of data as rows are already grouped collectively. So HAVING is a time-saver.
Nicely, let’s say you aren’t a lot involved about effectivity. However, now you need all of the product classes and gross sales supervisor the place whole transport price is greater than 6000. And that is when HAVING comes helpful.
Right here, to filter the data right here it is advisable use the situation SUM(Shipping_Cost) > 6000 and you cannot use any mixture operate within the WHERE clause.
You should utilize HAVING like beneath on this scenario —
SELECT Product_Category,
Sales_Manager,
SUM(Shipping_Cost) AS Total_Cost
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category,
Sales_Manager
HAVING SUM(Shipping_Cost) > 6000
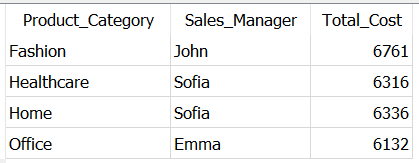
As you used aggregation on Shipping_Cost, you don’t want to say it in GROUP BY. Logically, all of the rows grouped collectively primarily based on product class and gross sales supervisor after which HAVING scans for the given situation in all these teams.
Due to this fact, HAVING used along side GROUP BY is an optimized option to filter rows primarily based on a situation.
Additional, though GROUP BY arranges the data in ascending or alphabetical order, typically you may need to organize the data as per aggregated columns. And that’s when ORDER BY jumps in.
In SQL, ORDER BY is used to type the outcomes and by default it kinds them in ascending order. Nonetheless, to get the lead to descending order, it is advisable merely add key phrase DESC after column names in ORDER BY clause.
Let’s proceed with the above instance. You may see the final result’s ordered in ascending (alphabetical) order, first by column Product_Category after which by Sales_Manager. Nonetheless, the values in final column — Total_Cost — should not ordered.
This may be particularly achieved utilizing ORDER BY clause, as talked about beneath.
SELECT Product_Category,
Sales_Manager,
SUM(Shipping_Cost) AS Total_Cost
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category,
Sales_Manager
ORDER BY Total_Cost DESC

Clearly, the final column is now organized within the descending order. Additionally, you’ll be able to see that, now there is no such thing as a particular order for values in first two columns. And that’s as a result of, you included them solely in GROUP BY however not in within the ORDER BY clause.
This drawback may be solved by mentioning them within the ORDER BY clause, as beneath —
SELECT Product_Category,
Sales_Manager,
SUM(Shipping_Cost) AS Total_Cost
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category,
Sales_Manager
ORDER BY Product_Category,
Sales_Manager,
Total_Cost DESC

Now, the primary two columns are organized within the ascending order and solely the final column — Total_Cost — is organized within the descending order. And it’s as a result of the key phrase DESC is used solely after this column title.
You may organize a SQL consequence dataset by a number of columns in numerous orders i.e. organize some columns in ascending and the remaining in descending order. However, take note of the order wherein the column names are talked about in ORDER BY, because it adjustments the consequence set.
On this case it is very important perceive how GROUP BY labored. Did you ask your self a query —
Why you’ll be able to’t see all of the values within the
Total_Costcolumn in descending order

It’s as a result of solely the primary two columns are talked about in GROUP BY. All of the data are organized in teams primarily based on values in these two columns solely and whole price is calculated by aggregating values in Shipping_Cost column.
So, in the end, whole price values within the consequence are organized primarily based on these teams and never on complete desk.
Going forward, let’s discover an instance which is able to additional assist you to grasp the distinction between filtering data and when to make use of WHERE and HAVING along side GROUP BY.
As you already learn all of the ideas within the article up to now, let’s straight begin with an instance.
Suppose you need to get the checklist of gross sales managers and product classes for all of the orders that are Not Delivered to buyer. On the similar time, you need to show solely these gross sales managers who spent greater than 1600 USD on transport merchandise in a selected product class.
Now, you’ll be able to resolve this drawback with the beneath 3 steps —
- Filter all of the data utilizing situation
Standing = ‘Not Delivered’. As this can be a non aggregated column, you should utilize WHERE for that. - Filter data primarily based on whole transport price utilizing situation
SUM(Shipping_Cost) > 1600. As that is an aggregated column, you must use HAVING for that. - To calculate whole transport price, it is advisable group the data by gross sales supervisor and product class, utilizing
GROUP BY
In case you are following alongside, your question ought to seem like —
SELECT Sales_Manager,
Product_Category,
SUM(Shipping_Cost) AS Total_Cost
FROM Dummy_Sales_Data_v1
WHERE Standing = 'Not Delivered'
GROUP BY Sales_Manager,
Product_Category
HAVING SUM(Shipping_Cost) > 1600

It offers out all of the distinctive mixtures of gross sales supervisor and product classes satisfying the situations talked about within the instance.
You may discover, the primary two columns are organized in ascending order. Additionally, the 2 rows encircled in pink, reveals ascending order of product class for similar gross sales supervisor. That is the proof that, GROUP BY arranges the data in ascending order by default.
That’s all about GROUP BY!

{kind=link}