
R has quite a few fast, elegant methods to hitch information frames by a typical column. I’d like to indicate you three of them:
- base R’s
merge()perform, - dplyr’s be part of household of capabilities, and
- information.desk’s bracket syntax.
Get and import the info
For this instance I’ll use considered one of my favourite demo information units — flight delay instances from the U.S. Bureau of Transportation Statistics. If you wish to comply with alongside, head to http://bit.ly/USFlightDelays and obtain information for the timeframe of your selection with the columns Flight Date, Reporting_Airline, Origin, Vacation spot, and DepartureDelayMinutes. Additionally get the lookup desk for Reporting_Airline.
Or, obtain these two information units — plus my R code in a single file and a PowerPoint explaining several types of information merges — right here:
Consists of a number of information information, a PowerPoint, and R script to accompany InfoWorld article. Sharon Machlis
To learn within the file with base R, I’d first unzip the flight delay file after which import each flight delay information and the code lookup file with learn.csv(). When you’re operating the code, the delay file you downloaded will probably have a unique title than within the code beneath. Additionally, be aware the lookup file’s uncommon .csv_ extension.
unzip("673598238_T_ONTIME_REPORTING.zip")
mydf <- learn.csv("673598238_T_ONTIME_REPORTING.csv",
sep = ",", quote=""")
mylookup <- learn.csv("L_UNIQUE_CARRIERS.csv_",
quote=""", sep = "," )
Subsequent, I’ll take a peek at each information with head():
head(mydf)
FL_DATE OP_UNIQUE_CARRIER ORIGIN DEST DEP_DELAY_NEW X
1 2019-08-01 DL ATL DFW 31 NA
2 2019-08-01 DL DFW ATL 0 NA
3 2019-08-01 DL IAH ATL 40 NA
4 2019-08-01 DL PDX SLC 0 NA
5 2019-08-01 DL SLC PDX 0 NA
6 2019-08-01 DL DTW ATL 10 NAhead(mylookup)
Code Description
1 02Q Titan Airways
2 04Q Tradewind Aviation
3 05Q Comlux Aviation, AG
4 06Q Grasp Prime Linhas Aereas Ltd.
5 07Q Aptitude Airways Ltd.
6 09Q Swift Air, LLC d/b/a Jap Air Traces d/b/a Jap
Merges with base R
The mydf delay information body solely has airline info by code. I’d like so as to add a column with the airline names from mylookup. One base R manner to do that is with the merge() perform, utilizing the fundamental syntax merge(df1, df2). It doesn’t matter the order of knowledge body 1 and information body 2, however whichever one is first is taken into account x and the second is y.
If the columns you need to be part of by don’t have the identical title, you’ll want to inform merge which columns you need to be part of by: by.x for the x information body column title, and by.y for the y one, equivalent to merge(df1, df2, by.x = "df1ColName", by.y = "df2ColName").
It’s also possible to inform merge whether or not you need all rows, together with ones with no match, or simply rows that match, with the arguments all.x and all.y. On this case, I’d like all of the rows from the delay information; if there’s no airline code within the lookup desk, I nonetheless need the data. However I don’t want rows from the lookup desk that aren’t within the delay information (there are some codes for previous airways that don’t fly anymore in there). So, all.x equals TRUE however all.y equals FALSE. Full code:
joined_df <- merge(mydf, mylookup, by.x = "OP_UNIQUE_CARRIER",
by.y = "Code", all.x = TRUE, all.y = FALSE)
The brand new joined information body features a column referred to as Description with the title of the airline primarily based on the service code.
head(joined_df) OP_UNIQUE_CARRIER FL_DATE ORIGIN DEST DEP_DELAY_NEW X Description 1 9E 2019-08-12 JFK SYR 0 NA Endeavor Air Inc. 2 9E 2019-08-12 TYS DTW 0 NA Endeavor Air Inc. 3 9E 2019-08-12 ORF LGA 0 NA Endeavor Air Inc. 4 9E 2019-08-13 IAH MSP 6 NA Endeavor Air Inc. 5 9E 2019-08-12 DTW JFK 58 NA Endeavor Air Inc. 6 9E 2019-08-12 SYR JFK 0 NA Endeavor Air Inc.
Joins with dplyr
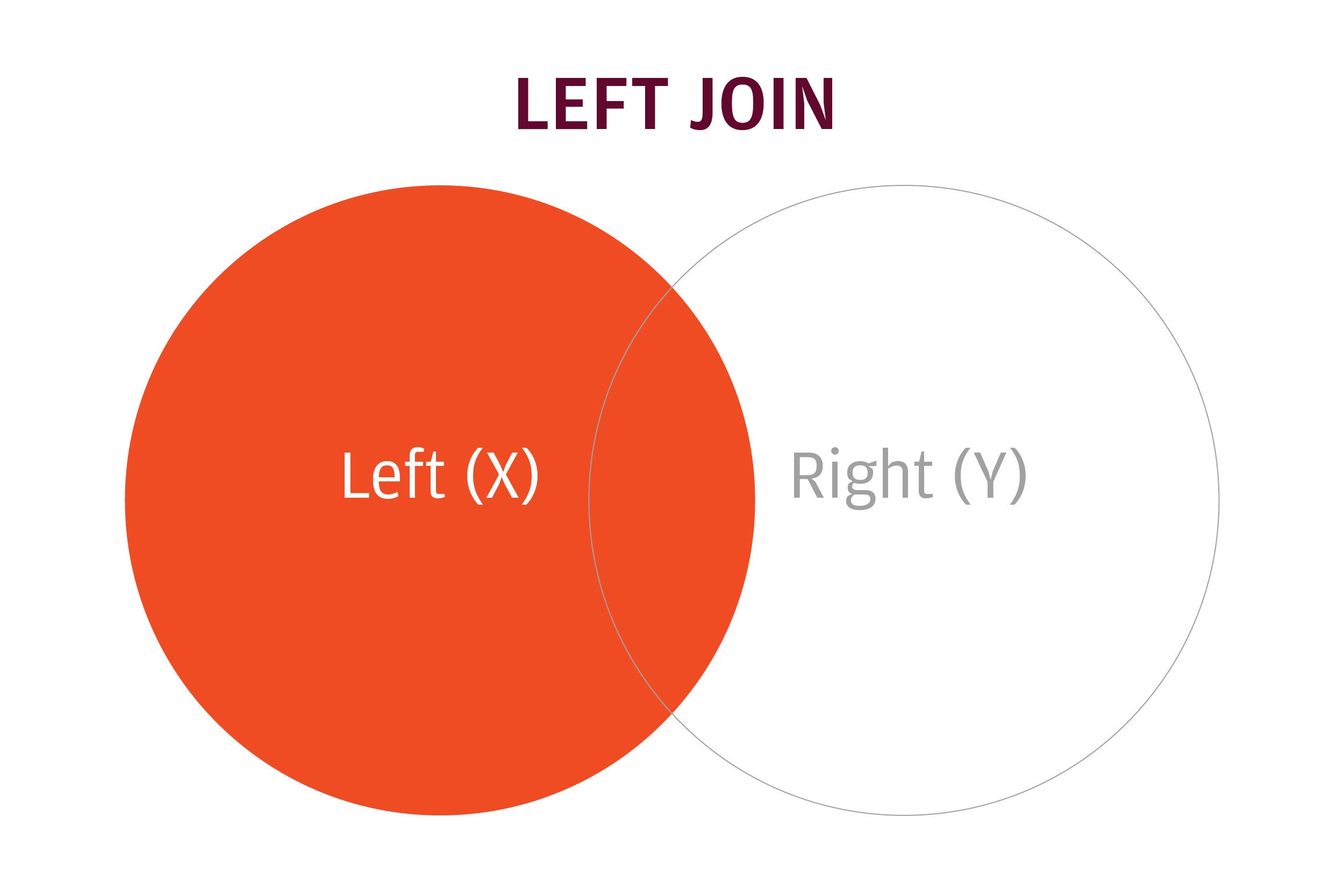
dplyr makes use of SQL database syntax for its be part of capabilities. A left be part of means: Embody the whole lot on the left (what was the x information body in merge()) and all rows that match from the correct (y) information body. If the be part of columns have the identical title, all you want is left_join(x, y). In the event that they don’t have the identical title, you want a by argument, equivalent to left_join(x, y, by = c("df1ColName" = "df2ColName")) .
Notice the syntax for by: It’s a named vector, with each the left and proper column names in citation marks.
Replace: The improvement model of dplyr has an extra by syntax: left_join(x, y, by = join_by(df1ColName == df2ColName)). As a substitute of a named vector with quoted column names, the brand new join_by() perform makes use of unquoted column names and the == boolean operator.
If you would like to do this out, you may set up the dplyr dev model (1.0.99.90 as of this writing) with devtools::install_github("tidyverse/dplyr") or remotes`::install_github("tidyverse/dplyr").
 IDG
IDGA left be part of retains all rows within the left information body and solely matching rows from the correct information body.
The code to import and merge each information units utilizing left_join() is beneath. It begins by loading the dplyr and readr packages after which reads within the two information with read_csv(). When utilizing read_csv(), I don’t must unzip the file first.
library(dplyr)
library(readr)
mytibble <- read_csv("673598238_T_ONTIME_REPORTING.zip")
mylookup_tibble <- read_csv("L_UNIQUE_CARRIERS.csv_")
joined_tibble <- left_join(mytibble, mylookup_tibble,
by = c("OP_UNIQUE_CARRIER" = "Code"))
read_csv() creates tibbles, that are a sort of knowledge body with some additional options. left_join() merges the 2. Check out the syntax: On this case, order issues. left_join() means embrace all rows on the left, or first, information set, however solely rows that match from the second. And, as a result of I want to hitch by two in a different way named columns, I included a by argument.
The brand new be part of syntax within the development-only model of dplyr can be
joined_tibble2 <- left_join(mytibble, mylookup_tibble,
by = join_by(OP_UNIQUE_CARRIER == Code))
Since most individuals probably have the CRAN model, nonetheless, I’ll use dplyr’s authentic named-vector syntax in the remainder of this text, till join_by() turns into a part of the CRAN model.
We will take a look at the construction of the outcome with dplyr’s glimpse() perform, which is one other approach to see the highest few gadgets of a knowledge body.
glimpse(joined_tibble) Observations: 658,461 Variables: 7 $ FL_DATE <date> 2019-08-01, 2019-08-01, 2019-08-01, 2019-08-01, 2019-08-01… $ OP_UNIQUE_CARRIER <chr> "DL", "DL", "DL", "DL", "DL", "DL", "DL", "DL", "DL", "DL",… $ ORIGIN <chr> "ATL", "DFW", "IAH", "PDX", "SLC", "DTW", "ATL", "MSP", "JF… $ DEST <chr> "DFW", "ATL", "ATL", "SLC", "PDX", "ATL", "DTW", "JFK", "MS… $ DEP_DELAY_NEW <dbl> 31, 0, 40, 0, 0, 10, 0, 22, 0, 0, 0, 17, 5, 2, 0, 0, 8, 0, … $ X6 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,… $ Description <chr> "Delta Air Traces Inc.", "Delta Air Traces Inc.", "Delta Air …
This joined information set now has a brand new column with the title of the airline. When you run a model of this code your self, you’ll most likely discover that dplyr was manner quicker than base R.
Subsequent, let’s take a look at a super-fast approach to do joins.

{kind=link}