Constructing blocks for state-of-the-art fashions
When speaking about Time Collection, individuals usually are likely to do it in a really sensible data-oriented method: when you try to lookup some definition, you could discover expressions similar to “a sequence of knowledge factors listed (or listed or graphed) in time order” (Wikipedia), “a set of knowledge collected at successive closing dates or over successive durations of time” (Encyclopædia Britannica), “a sequence of knowledge factors that happen in successive order over some time period” (Investopedia).
Reality is, actually every part that may be measured falls below this class; as quickly as we begin paying consideration and observe a phenomenon for a couple of snapshot, we will legitimately cope with it with the established idea of Time Collection modeling.
The one portions I can consider that don’t make sense as Time Collection are the basic bodily constants: the nice previous velocity of sunshine c, the gravitational fixed G, the basic electrical cost e… guys like them actually by no means change, in any respect.
I wish to spend a pair extra sentences on this as a result of I must drive a degree house: we can’t discuss Time Collection and instruments for coping with them below the pretence of completeness.
Certainly, every Time Collection is nothing however a single realization of a selected, probably very complicated bodily course of, with its personal probably infinite set of potential stochastic outcomes.
Realizing the vastness of prospects ought to assist us tone down our want to discover a one-size-fits-all answer for the duties of characterizing, classifying or forecasting Time Collection.

Briefly, forecasting is the duty of predicting future values of a goal Time Collection primarily based on its previous values, values of different associated sequence and options correlating the sequence to one another.
We often denote by Y the goal sequence, and use X for its covariates; in fact, that is arbitrary since all sequence we use will likely be, at the very least in precept, covariates to one another.
It’s as an alternative a significant distinction to indicate by one other letter, say Z, these Time Collection with identified future values: assume calendar options, similar to week numbers and holidays.
These sequence may help at inference in addition to throughout coaching, and should be handled in a different way from the others: for one factor, they don’t require forecasting.
One other naming conference price mentioning pertains to time: the sequence begin at a traditional preliminary time t=0, then we use T to indicate the break up between previous (t=0 to T) and future (t>T), or coaching and testing; h signifies the forecasting horizon, i.e. what number of time models sooner or later we’d like the forecast to achieve (t=T+1 to t=T+h).
Lastly, to account for various subgroups and relations throughout all covariates, forecasting fashions usually permit for the specification of so-called static options (W); these are nothing greater than values labeling every sequence.
For instance, we’d have a set of sequence representing family consumption of electrical energy, whose static options describe the households themselves (variety of occupants, home measurement and so forth).

Discover within the image that each object is denoted in daring, which is often reserved for vectors: it is because, a priori, one also can cope with sequence having a couple of worth for every time step.
We name such multiple-valued sequence multi-variate, versus the extra frequent uni-variate sequence. Right here we’re borrowing from the statistical jargon: in statistics, a multi-variate chance distribution is one which will depend on a couple of random variable.
Classification
At any time when we’ve to face a forecasting drawback, we will instantly begin to shed some mild on it by giving it some labels; for this, we will bear in mind the next classification, primarily based on the definitions we gave thus far:
Knowledge-driven standards
- Availability of covariates or static options.
- Dimension of the information level: uni- or multi-variate.
Downside-driven standards
- Forecast sort, level or probabilistic (quantiles).
- Horizon measurement, i.e. variety of predicted time steps in a single cross.
Time Collection forecasting is a longtime area, wherein an arsenal of statistical instruments and theories had already been identified earlier than the arrival of extra modern Machine Studying methods. We gained’t focus an excessive amount of on these, however it’s nonetheless helpful to run by way of the commonest ones.
Baselines
The very first thing that involves thoughts when interested by future values of one thing absolutely is to take a look at its present worth; on second thought, one would positively have a look at previous values as properly, and accept a median or possibly try to comply with a development.

We name these strategies easy; they’re conceptually necessary as a result of they already inform us that having uneven information (the arrow of time going ahead, versus the uniformity of e.g. tabular information the place each pattern will get handled the identical method) provides a stage of complexity, requiring us to make some assumptions:
- Will the longer term appear like now?
- Does it matter what the previous seemed like? How far again ought to we glance?
- Is the method beneath the outcomes the identical because it was earlier than and as will probably be later?
If the solutions to those questions are all “sure”, i.e. we assume that every one previous data is helpful and there’s a single sample to comply with, we resort to regression strategies to seek out the very best operate to approximate our information, by looking amongst more and more complicated households: linear, polynomial, splines, and so forth.

Except we all know for some cause about some most popular household of capabilities to look into, we’ll simply decide the optimum operate with respect to information. This, although, once more stems just a few doubts:
- Can we count on the newer traits to proceed indefinitely?
- Will previous peaks and valleys occur once more?
- Does it even make sense for the sequence to achieve these values that regression predicts for the longer term?
Decomposition strategies
It needs to be clear now that we can’t depend on information alone, we’d like at the very least come contextual data on the method that generates it.
Decomposition strategies go on this path, being most helpful once we know that the sequence comes from a course of having some form of periodicity.
In probably the most traditional of those strategies, the Season-Pattern-The rest decomposition, we search for a slow-changing clean baseline (development), then flip to quick repeating parts (seasonalities), and eventually we deal with the remainder of the sign as random noise (the rest).

Decomposition strategies give us extra freedom for utilizing our information about information to forecast its future: for instance, in tourism-related information we might look forward to finding weekly (weekends) or yearly (summers) patterns: encoding these periodicities into the mannequin reassures us that forecasts will likely be much less “dumb” and extra “knowledgeable”.
SARIMAX strategies
Lastly for this overview of classical forecasting strategies, SARIMAX strategies are an much more versatile framework permitting to pick parts that finest approximate the Time Collection.
The letters making the SARIMAX acronym signify analytical blocks that we will compose collectively into the equations of the mannequin:
- Seasonal if the Time Collection has a periodic part;
- (Vector) if the Time Collection is multivariate;
- Auto-Regressive if the Time Collection will depend on its earlier values;
- Built-in if the Time Collection is non-stationary (e.g. it has a development);
- Transferring Common if the Time Collection will depend on earlier forecast errors;
- eXogenous variables if there are covariates to take advantage of.
SARIMAX fashions have been extremely profitable whereas being conceptually fairly easy, and finest signify how one ought to cope with a forecasting drawback: use all data you’ve gotten about the issue to limit the category of fashions to look into, then search for the very best approximation of your information mendacity inside that class.
Many latest assessment papers [2][3][4] have outlined how, after a too lengthy interval of basic lack of curiosity from practitioners, Machine Studying fashions and particularly Neural Networks have gotten ever extra central within the Time Collection forecasting discourse.
To grasp why Deep Studying particularly is very fitted to this drawback, we will tie a conceptual thread that hyperlinks classical methods to the newest and profitable architectures.

The affordable effectiveness of Deep Studying
Because it stands, we all know that many sorts of Neural Community are common approximators of any (fairly outlined) operate, supplied they’re fed with sufficient information and reminiscence [5][6][7].
This in fact makes them a superb candidate for any supervised studying drawback, the place the purpose is certainly to study a operate that satisfies identified input-output associations.
Sadly, although, theoretical properties like common approximation usually fail to be related in follow, the place the theory hypotheses don’t maintain: particularly, we by no means have sufficient information and reminiscence to efficiently carry out a studying process with any generic common structure.
There’s although one other weapon in Neural Networks’ arsenal, and that’s the chance of injecting data about an issue a priori, in a method that helps the mannequin study the specified operate as if we had extra information or computational time to spend.
We are able to do that by configuring the structure of the community, i.e. by designing specific community connectivity and form relying on the issue at hand: this quantities to basically constraining the search house of doable capabilities and imposing a computational movement that ends in optimum parameters of the community.
From this concept, and years of analysis on this path, a taxonomy of community buildings and the associated drawback they successfully resolve is being compiled; the strategy is considerably artisanal and heuristic at instances, however generalizing and stylish mathematical theories are rising as properly [8].

The important thing benefit of Deep Studying just isn’t, then, its universality, however reasonably its versatility and modularity: the power to simply play with a community by extending it, composing it, and rewiring its nodes is essential for locating the suitable candidate mannequin for a selected drawback.
Furthermore, when such mannequin has been discovered, modularity can streamline the transition to related issues with out shedding all acquired experience (see switch studying).
All of those options make Deep Studying the proper successor to classical methods, persevering with the development of rising mannequin complexity and specialization but additionally bringing large boosts in universality and flexibility.

We’re solely now getting to know how shaping a Neural Community’s structure adjustments the lessons of capabilities it approximates finest, however it’s clear that tailoring it to a selected class of issues by imposing a sure form and construction is immensely useful: certainly, this follow has the benefit of pointing the community in direction of the suitable path from the beginning, thus lowering the time and assets spent on fallacious paths.
Now, what are probably the most helpful components for constructing Deep Studying fashions that may sort out the toughest forecasting issues?
As we stated earlier than, every forecasting drawback requires its recipe; it’s subsequently instructive to take a look at just a few chosen community buildings and see how they handle particular options of the issue by shaping the computational movement and the ensuing educated mannequin.

Please word that we’ll solely give a really concise description of the architectures we’re going to speak about, after which solely deal with how they handle studying particular options of a Time Collection.
Unsurprisingly, there are various assets on the market protecting the extra technical and mathematical particulars; for instance, Dive Into Deep Studying [15] could be very complete and may cowl all primary ideas and definitions.
Convolutional Neural Networks
Convolutional networks, or CNNs, have been round for fairly a very long time and proved profitable for a lot of supervised studying duties.
Their most hanging achievement is studying picture options, similar to classifying footage primarily based on whether or not one thing particular is depicted within them.
Extra typically, a CNN is helpful every time our information at hand:
- could be meaningfully represented in tensor kind: 1D array, 2D matrix…,
- comprises significant patterns in factors which can be shut to one another within the tensor, however independently of the place within the tensor they’re.
It’s straightforward to see how picture classification fits this method:
- footage are naturally matrices of pixels, and
- the classification is often primarily based on the presence of an object within it, which is depicted as a gaggle of adjoining pixels.
Be aware that the “meaningfulness” will depend on the issue we try to resolve, since patterns and representations might make sense just for sure targets.
For instance, think about the issue of appropriately assigning well-known work to their painter, or the artwork motion they belong to: it’s not apparent that patterns of adjoining pixels may help with classification, since for instance detecting an object could be helpful for some (renaissance artists did a variety of portraits), however not for others (how wouldn’t it assist with extra modern genres?) [16].
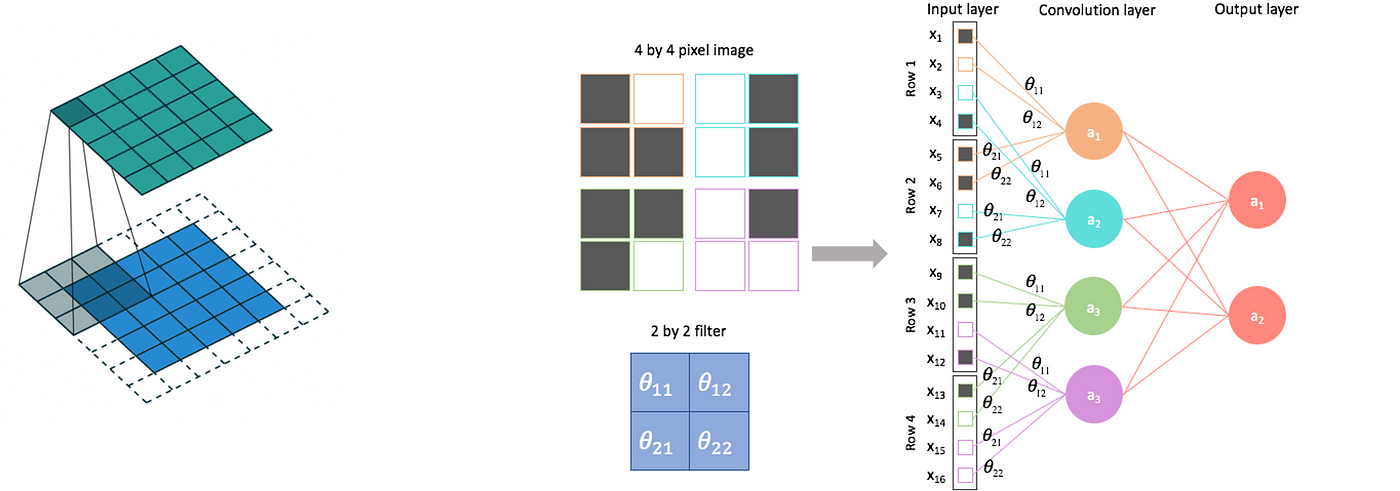
Briefly, a CNN can study the above-mentioned native patterns by making use of a convolution with shared weights: every node in a convolutional layer is the dot product between a window of adjoining nodes from the earlier layer (pixels, within the case of an image) and a matrix of weights.
Certainly, performing this product for all same-sized home windows within the authentic layer quantities to making use of a convolution operation: the convolving matrix, which is similar all through the operation, is made from learnable community parameters that are thus shared between the nodes.
This manner, translation invariance is enforced: the community learns to affiliate native patterns to the specified output, irrespective of the place of the sample contained in the tensor.
See right here [11] for a superb and extra intensive rationalization.
However can we efficiently apply a CNN in a Time Collection setting?
Nicely, absolutely the 2 essential situations talked about originally should maintain:
- a Time Collection is of course an ordered 1D array, and
- often factors which can be shut in time kind fascinating patterns (traits, peaks, oscillations).
By sliding its convolutional array alongside the time axis, a CNN is usually capable of decide up repeating patterns in a sequence similar to it may detect objects in an image.
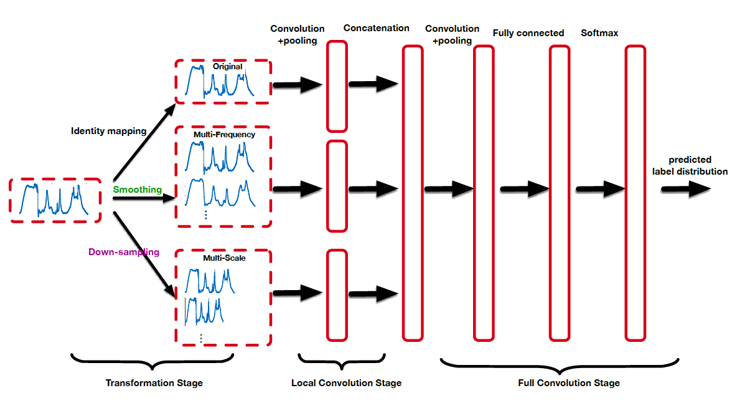
Furthermore, we will trick a CNN into studying totally different buildings by modifying its enter sequence by way of well-known Time Collection manipulation methods.
For instance, by sub-sampling a sequence we will make a convolutional layer detect patterns at totally different time scales; by making use of transformations within the frequency area we will make it study clean, de-noised patterns [12].
Recurrent Neural Networks
If CNNs discovered their candy spot in Pc Imaginative and prescient purposes, the place photos and movies are the commonest information codecs, Recurrent Neural Networks appear significantly appropriate for Time Collection purposes.
Nonetheless, probably the most hanging successes of RNNs arguably come from the sector of Pure Language Processing, in duties similar to machine translation or speech recognition [17].
Certainly, whereas CNNs search for native buildings inside multi-dimensional ordered information, RNNs deal with a single dimension and search for patterns of longer length.
The flexibility to detect patterns that span throughout nice lengths is especially helpful when coping with sure sorts of Time Collection, specifically people who current low-frequency cycles and seasonalities or these having long-range auto-correlations.
A primary RNN layer performing on ordered 1D enter information has a one-to-one affiliation between these information factors and the nodes of the layer; on prime of this, intra-layer connections kind a sequence that follows the ordering of the enter information.
The coaching course of consists of splitting the sequential information into sliding, overlapping chunks (of the identical size because the variety of hidden states): they’re fed sequentially, linked by the recurrent intra-layer connections that propagate by way of them.
We frequently denote layer nodes as latent or hidden states h; they encode significant data from their correspondent enter information level, mediating it with the recursive sign from earlier hidden states.

For Time Collection forecasting functions, the output nodes of a recurrent layer could be educated to study an n-step-ahead prediction, for any selection of n, in order that the ordered output represents a full forecast path; most of the time, although, an RNN is only a module in a extra complicated structure.
In any case, the thought is to course of and retain details about the previous in order that at any level in the course of the coaching course of the algorithm can entry stated data and use it.
As in CNNs, this can be a type of weight sharing, since all chunks of the Time Collection enter the identical structure; for a similar cause, translation invariance assures that independently of when a sure sample occurred, the mannequin will nonetheless be capable of affiliate it to the noticed output worth.
In a plain RNN, hidden states are linked to enter nodes and one another utilizing traditional activation capabilities and linear scalar merchandise; various totally different extra complicated “flavours”, similar to LSTMs and GRUs, have emerged in response to some identified limitations similar to vanishing gradients [18][19].
Briefly, the vanishing gradient impact happens throughout backpropagation, when composing small derivatives with the product rule in an extended computation chain can lead to infinitesimal updates in some nodes’ parameters, successfully halting the coaching algorithm [20].


Consideration Mechanisms
Consideration Mechanisms had been born within the context of NLP for the duty of neural machine translation, the place the thought of a single world mannequin able to translating any sentence from a given language required a extra complicated approach than these obtainable on the time [22].
AMs are sometimes present in Encoder-Decoder architectures, the place they permit to seize principally related data.

The overall concept of an consideration mechanism, certainly, is that treating all bits of a temporal information sequence as in the event that they’re all equally necessary could be wasteful if not deceptive for a mannequin.
Some phrases could be basic for understanding the tone and context of a sentence: they should be thought of at the side of most different phrases in the identical sentence.
In sensible phrases the mannequin wants to remain alert, being able to pay extra consideration to those phrases and to make use of them to affect its translation of others in the identical sentence.
In Time Collection purposes, the same argument could be made about moments in time which can be crucial and influential for future improvement of the sequence: structural development adjustments, sudden spikes (outliers), unusually lengthy low-valued durations… are simply a number of the patterns that may be helpful to detect in some contexts.

That’s principally what an AM does: it takes any given piece of enter information (generally known as question) and considers all doable input-output pairs (known as keys and values respectively) conditionally on the presence of the question itself.

Within the course of, the mannequin computes consideration scores that signify the significance of the question as context for every key.
Be aware that the scoring operate could be fastened (e.g. computing the gap between question and key within the sequence), or, extra curiously, parameterized as a way to be learnable.
Consideration scores are often normalized into weights and used for a weighted common of values, which can be utilized because the output of the mechanism.

Residual Networks
Residual Networks are equipment to present modules, offering what known as a skip connection: the enter will get transported in parallel with the computation that occurs to it within the block, and the 2 variations are then mixed on the output (often with an addition or a subtraction, with distinct results).
Within the case of an addition, for instance, the introduction of a skip connection successfully makes it such that the skipped block switches from studying some authentic transformation f(x) to its residual, f(x)-x.

They had been first launched by making use of them to CNNs [21], however these days they’re principally in every single place since they supply clear benefits with out including an excessive amount of computation or complexity.
From the look of them, RNs are a quite simple idea; it’s possibly not apparent what it achieves, although, so let’s now break down their strengths.
- Facilitating data unfold: as talked about earlier than, lengthy chains of computation can undergo from vanishing gradients; a residual connection gives a further time period to the gradient that doesn’t comprise the chain product of derivatives given by the skipped block.
- Avoiding accuracy saturation: it has been proven [21] that including residual blocks helps mitigate this impact, which consists in blocking the same old enhancements that come from including extra layers and generally may even trigger deterioration as an alternative (“degradation”).
- Offering on/off switches: the truth that the skipped block learns the residual f(x)-x opens a brand new chance for the mannequin, specifically to set all parameters of the block such that f(x)=0 and the mixed output equals x. That is in fact an id, which means that the mixed block is successfully turned off.
- Decomposing an enter: one other impact of studying residuals is that when you cleverly assemble residual blocks in sequence (“cascading” blocks), then the n-th block could be made to study the results of eradicating the earlier n-1 blocks from the enter. In different phrases, every block is studying slightly piece of the specified consequence, which could be recovered by including collectively the items on the finish. Furthermore, we will tailor every cascading block to study totally different items, in order that we successfully obtain identified Time Collection decompositions, such because the STR or a Fourier rework [9].

Hopefully, it’s clear at this level that Deep Studying is on a profitable path so far as Time Collection forecasting goes.
This path represents a historical past of more and more complicated and tailor-made fashions, specializing in several sub-classes of Time Collection, and it is just being populated by Neural Networks since not too long ago; classical statistical fashions pre-date them, however nonetheless confirmed a bent to get increasingly more handcrafted for particular predictive duties.
Sooner or later, and this consideration absolutely applies to different fields of Statistical Studying (particularly Machine Studying), it’s crucial for the considerably artisanal strategy generally used at present to create space for a mathematical framework that may systematically hyperlink the options of a prediction drawback to the very best architectures for fixing it.
