
Knowledge Preparation
As much as 8000 instances quicker than normal capabilities

When coping with smaller datasets it’s simple to imagine that standard Python strategies are fast sufficient to course of information. Nonetheless, with the rise within the quantity of knowledge produced, and usually obtainable for evaluation, it’s changing into extra essential than ever to optimise code to be as quick as attainable.
We are going to subsequently look into how utilizing vectorization, and the numpy library, may help you velocity up numerical information processing.
Python is properly generally known as a wonderful language for information processing and exploration. The primary attraction is that it’s a excessive degree language, so it’s simple and intuitive to grasp and be taught, and fast to jot down and iterate. All of the options you’ll need in case your focus is information evaluation / processing and never writing mountains of code.
Nonetheless, this ease of use comes with a draw back. It’s a lot slower to course of calculations when in comparison with decrease degree languages comparable to C.

Fortuitously, as python is among the chosen languages of the info evaluation and information science communities (amongst many others), there are intensive libraries and instruments obtainable to mitigate the inherent ‘slowness’ of python relating to processing massive quantities of knowledge.
You’ll typically see the time period “vectorization” when speaking about dashing calculations up with numpy. Numpy even has a way known as “vectorize”, as we’ll see later.
A normal Google search will lead to an entire lot of complicated and contradictory details about what vectorization really is, or simply generalised statements that don’t inform you an ideal deal:
The idea of vectorized operations on NumPy permits the usage of extra optimum and pre-compiled capabilities and mathematical operations on NumPy array objects and information sequences. The Output and Operations will velocity up when in comparison with easy non-vectorized operations.
– GeekForGeeks.org — the primary google end result when looking — what’s numpy vectorization?
It simply doesn’t say rather more than: it should get quicker because of optimisations.
What optimisations?
The difficulty is that numpy is a really highly effective, optimised device. When implementing one thing like vectorization, the implementation in numpy contains a variety of properly thought out optimisations, on prime of simply plain previous vectorization. I feel that is the place a variety of the confusion comes from, and breaking down what’s going on (to some extent at the very least) would assist to make issues clearer.
The next sections will breakdown what is often included beneath the generalised “vectorization” umbrella as used within the numpy library.
Understanding what every does, and the way it contributes to the velocity of numpy “vectorized” operations, ought to hopefully assist with any confusion.
Precise vectorization
Vectorization is a time period used exterior of numpy, and in very primary phrases is parallelisation of calculations.
You probably have a 1D array (or vector as they’re additionally identified):
[1, 2, 3, 4]
…and multiply every aspect in that vector by the scalar worth 2, you find yourself with:
[2, 4, 6, 8]
In regular python this could be completed aspect by aspect utilizing one thing like a for loop, so 4 calculations one after the opposite. If every calculation takes 1 second, that might be 4 seconds to finish the calculation and situation the end result.
Nonetheless, numpy will really multiply two vectors collectively [2,2,2,2] and [2,4,6,8](numpy ‘stretches’ the scalar worth 2 right into a vector utilizing one thing known as broadcasting, see the subsequent part for extra on that). Every of the 4 separate calculations is completed all of sudden in parallel. So by way of time, the calculation is accomplished in 1 second (every calculation takes 1 second, however they’re all accomplished on the similar time).
A 4 fold enchancment in velocity simply by way of ‘vectorization’ of the calculation (or, if you happen to like, a type of parallel processing). Please naked in thoughts that the instance I’ve given could be very simplified, but it surely does assist for example what’s going on on a primary degree.
You may see how this might equate to a really massive distinction in case you are coping with datasets with hundreds, if not hundreds of thousands, of components.
Simply remember, the parallelisation isn’t limitless, and depending on {hardware} to some extent. Numpy isn’t in a position to parallelise 100 million calculations all collectively, however it may well cut back the quantity of serial calculations required by a big quantity, particularly when coping with a considerable amount of information.
If you would like a extra detailed rationalization, then I like to recommend this stackoverflow submit, which does an ideal job of explaining in additional element. If you would like much more element then this article, and this article are wonderful.
Broadcasting
Broadcasting is a characteristic of numpy that allows mathematical operations to be carried out between arrays of various sizes. We really did simply that within the earlier part.
The scalar worth 2 was “stretched” into an array stuffed with 2s. That’s broadcasting, and is among the methods wherein numpy prepares information for rather more environment friendly calculations. Nonetheless, saying “it simply creates an array of 2s” is a gross oversimplification, however it isn’t value stepping into the element right here.
Numpy’s personal documentation is definitely fairly clear right here:
The time period broadcasting describes how NumPy treats arrays with completely different shapes throughout arithmetic operations. Topic to sure constraints, the smaller array is “broadcast” throughout the bigger array in order that they’ve appropriate shapes. Broadcasting offers a method of vectorizing array operations in order that looping happens in C as a substitute of Python.
A quicker language

As detailed within the quote from numpy’s personal documentation within the earlier part, numpy makes use of pre-compiled and optimised C capabilities to execute calculations.
As C is a decrease degree language, there’s rather more scope for optimisation of calculations. This isn’t one thing you must take into consideration, because the numpy library does that for you, however it’s one thing you profit from.
Homogeneous information varieties
In python you may have the flexibleness to specify lists with a combination of various datatypes (strings, ints, floats and so on.). When coping with information in numpy, the info is homogeneous (i.e. all the identical kind). This helps velocity up calculations as the info kind doesn’t should be discovered on the fly like in a python checklist.
This will after all additionally been seen as a limitation, because it makes working with combined information varieties harder.
Placing all of it collectively
As beforehand talked about, it’s fairly widespread for the entire above (and extra) to be grouped collectively when speaking about vectorization in numpy. Nonetheless, as vectorization can be utilized in different contexts to explain extra particular operations, this may be fairly complicated.
Hopefully, it’s all a bit of bit clearer as to what we’re coping with, and now we will transfer on to the sensible aspect.
How a lot distinction does numpy’s implementation of vectorization actually make?
To display the effectiveness of vectorization in numpy we’ll examine just a few completely different generally used strategies to use mathematical capabilities, and likewise logic, utilizing the pandas library.
pandas is a quick, highly effective, versatile and straightforward to make use of open supply information evaluation and manipulation device, constructed on prime of the Python programming language.
Pandas is broadly used when coping with tabular information, and can be constructed on prime of numpy, so I feel it serves as an ideal medium for demonstrating the effectiveness of vectorization.
All of the calculations that comply with can be found in a colab pocket book

The information
The information can be a easy dataframe with two columns. Each columns can be comprised of 1 million rows of random numbers taken from a standard distribution.
df = pd.DataFrame({‘series1’:np.random.randn(1000000), ‘series2’:np.random.randn(1000000)})
which leads to:
The manipulation
Then the above dataframe can be manipulated by two completely different capabilities to create a 3rd column ‘series3’. It is a quite common operation in pandas, for instance, when creating new options for machine or deep studying:
Perform 1 — a easy summation
def sum_nums(a, b):
return a + b
Perform 2 — logic and arithmetic
def categorise(a, b):
if a < 0:
return a * 2 + b
elif b < 0:
return a + 2 * b
else:
return None
Every of the above capabilities can be utilized utilizing completely different strategies (some vectorized, some not) to see which performs the calculations over the 1 million rows the quickest.
The strategies and the outcomes
The processing strategies that comply with are organized so as of velocity. Slowest first.
Every technique was run a number of instances utilizing the timeit library, and for each of the capabilities talked about within the earlier part. As soon as for the slower strategies, as much as 1000 instances for the quicker strategies. This ensures the calculations don’t run too lengthy, and we get sufficient iterations to common out the run time per iteration.
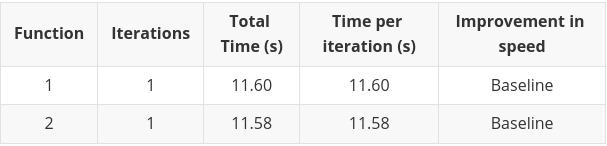
The pandas apply technique
The pandas apply technique could be very easy and intuitive. Nonetheless, it’s also one of many slowest methods of making use of calculations on massive datasets.
There isn’t a optimisation of the calculation. It’s principally performing a easy for loop. This technique ought to be prevented except the necessities of the operate rule out all different strategies.
# Perform 1
series3 = df.apply(lambda df: sum_nums(df['series1'],df['series2']),axis=1)# Perform 2
series3 = df.apply(lambda df: categorise(df['series1'],df['series2']),axis=1)
Itertuples
Itertuples, in some easy implementations, is even slower than the apply technique, however on this case it’s used with checklist comprehension, so achieves nearly a 20 instances enchancment in velocity over the apply technique.
Itertuples removes the overhead of coping with a pandas Sequence and as a substitute makes use of named tuples for the iteration¹. As beforehand talked about, this explicit implementation additionally advantages from the velocity up checklist comprehension offers, by eradicating the overhead of appending to a list².
Be aware: there’s additionally a operate known as iterrows, however it’s at all times slower, and subsequently ignored for brevity.
# Perform 1
series3 = [sum_nums(a, b) for a, b in df.itertuples(index=False)]# Perform 2
series3 = [categorise(a, b) for a, b in df.itertuples(index=False)]

Record comprehension
The earlier itertuples instance additionally used checklist comprehension, but it surely appears this explicit resolution utilizing ‘zip’ as a substitute of itertuples is about twice as quick.
The primary cause for that is the extra overhead launched by the itertuples technique. Itertuples really makes use of zip internally, so any extra code to get to the purpose the place zip is utilized is simply pointless overhead.
An awesome investigation into this may be present in this article. By the way, it additionally explains why iterrows is slower than itertuples.
# Perform 1
series3 = [sum_nums(a, b) for a, b in zip(df['series1'],df['series2'])]# Perform 2
series3 = [categorise(a, b) for a, b in zip(df['series1'],df['series2'])]

Numpy vectorize technique
It is a little bit of an odd one. The tactic itself is named ‘vectorize’, however the fact is it’s no the place close to as quick because the full-on optimised vectorization that we’ll see within the strategies that comply with. Even numpy’s personal documentation states:
The vectorize operate is supplied primarily for comfort, not for efficiency. The implementation is actually a for loop.
– numpy.org
Nonetheless, it’s true that the syntax used to implement this operate is very simple and clear. On prime of that, the tactic really does an ideal job of dashing up the calculation, extra so than any technique we’ve got tried up until now.
It is usually extra versatile than the strategies that comply with, and so is less complicated to implement in numerous conditions with none messing about. Numpy vectorize is subsequently an ideal technique to make use of, and extremely really helpful.
It’s simply value allowing for that though this technique is fast, it isn’t even shut to what’s achievable with the totally optimised strategies we’re about to see, so it mustn’t simply be your go to technique in all conditions.
# Perform 1
series3 = np.vectorize(sum_nums)(df['series1'],df['series2'])# Perform 2
series3 = np.vectorize(categorise)(df['series1'],df['series2'])

Pandas vectorization
Now we come to full on optimised vectorization.
The distinction in velocity is evening and day in comparison with any technique earlier than, and a primary instance of all of the optimisations mentioned in earlier sections of this text working collectively.
The pandas implementation continues to be an implementation of numpy beneath the hood, however the syntax could be very, very straight ahead. If you happen to can specific your required calculation this fashion, you possibly can’t do a lot better by way of velocity with out developing with a considerably extra difficult implementation.
Roughly, 7000 instances quicker than the apply technique, and 130 instances quicker than the numpy vectorize technique!
The draw back, is that such easy syntax doesn’t permit for classy logic statements to be processed.
# Perform 1
series3 = df['series1'] + df['series2']# Perform 2
# N/A as a easy operation isn't attainable because of the included logic within the operate.

Numpy vectorization
The ultimate implementation is as shut as we will get to implementing uncooked numpy while nonetheless having the inputs from a pandas dataframe.
Even so, by stripping away any pandas overhead within the calculation, a 15% discount in processing time is achieved when in comparison with the pandas implementation.
That’s 8000 instances quicker than the apply technique.
# Perform 1
series3 = np.add(df['series1'].to_numpy(),df['series2'].to_numpy())# Perform 2
# N/A as a easy operation isn't attainable because of the included logic within the operate.

I hope this text has helped to make clear a few of the jargon that exists particularly in relation to vectorization, and subsequently allowed you to have a greater understanding of which strategies could be most acceptable relying in your explicit scenario.
As a normal rule of thumb in case you are coping with massive datasets of numerical information, vectorized strategies in pandas and numpy are your good friend:
- If the calculation permits, attempt to use numpy’s inbuilt mathematical functions³
- Pandas’ mathematical operations are additionally a sensible choice
- If you happen to require extra difficult logic, use numpy’s vectorize⁴ technique
- Failing the entire above, it’s a case of deciding precisely what performance you want, and selecting one of many slower strategies as acceptable (checklist comprehension, intertuples, apply)
If you end up in a scenario the place you want each velocity and extra flexibility, then you might be in a very area of interest scenario. Chances are you’ll want to begin trying into implementing your personal parallelisation, or writing your personal bespoke numpy functions⁵. All of which is feasible.
1 https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.itertuples.html
2 Mazdak, Why is a listing comprehension a lot quicker than appending to a listing? (2015), stackoverflow.com
3 https://numpy.org/doc/secure/reference/routines.math.html
4 https://numpy.org/doc/secure/reference/generated/numpy.vectorize.html
5 https://numpy.org/doc/secure/person/c-info.ufunc-tutorial.html


{kind=link}