
A ready-to-use template for tokenization and padding of textual content sequences

On this article we’ll see tips on how to extract and apply padding to sequences of tokens to make use of to coach deep studying fashions with Tensorflow.
I’ve already touched on the topic in a earlier article the place I talked about tips on how to convert texts to tensors for deep studying duties, however on this case the main focus shall be on tips on how to accurately format the token sequences for Tensorflow.
This system is crucial to supply our fashions with sequences of uniform size (padded, as a matter of truth) token sequences. Let’s see how.
We’ll use the dataset offered by Sklearn, 20newsgroups, to have fast entry to a physique of textual knowledge. For demonstration functions, I’ll solely use a pattern of 10 texts however the instance will be prolonged to any variety of texts.

We received’t be making use of preprocessing on these texts, because the Tensorflow tokenization course of routinely removes the punctuation for us.
To tokenize means to cut back a sentence into the symbols that kind it. So if we have now a sentence like “Hello, my identify is Andrew.” its tokenized model will merely be [“Hello”, “,”, “my”, “name”, “is”, “Andrew”, “.”]. Observe that tokenization contains punctuation by default.
Making use of tokenization is step one in changing our phrases into numerical values that may be processed by a machine studying mannequin.
Sometimes it’s enough to use .break up() on a string in Python to carry out a easy tokenization. Nonetheless, there are a number of tokenization methodologies that may be utilized. Tensorflow gives a really attention-grabbing API for that and permits you to customise simply this logic. We’ll see it shortly.
As soon as a sentence is tokenized, Tensorflow returns numeric values related to every token. That is sometimes known as word_index, and is a dictionary consisting of phrase and index, {phrase: index}. Every phrase encountered is numbered and that quantity is used to determine that phrase.
A deep studying mannequin will usually need enter of uniform measurement. Which means sentences of various lengths shall be problematic for our mannequin. That is the place padding comes into play.
Let’s take two sentences and their index sequences (excluding punctuation):
- Hello, my identify is Andrew: [43, 3, 56, 6]
- Hello, I’m an analyst and I take advantage of Tensorflow for my deep studying tasks: [43, 11, 9, 34, 2, 22, 15, 4, 5, 8, 19, 10, 26, 27]
The primary is shorter (4 components) than the second (14 components). If we fed the sequences to our mannequin on this approach, it might give us some errors. The sequences should subsequently be normalized in order that they’ve the identical size.
Making use of padding on a sequence interprets in utilizing a predefined numeric worth (normally 0) to deliver the shorter sequences to the identical size because the sequence from the utmost size. So we’ll have this:
- Hello, my identify is Andrew: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 43, 3, 56, 6]
- Hello, I’m an analyst and I take advantage of Tensorflow for my deep studying tasks: [43, 11, 9, 34, 2, 22, 15, 4, 5, 8, 19, 10, 26, 27]
Now each sequences are of the identical size. We will determine tips on how to do padding — whether or not to insert zeros earlier than or after the sequence, straight with Tensorflow’s pad_sequences technique.
Let’s apply now with the code under the tokenization and padding to our knowledge corpus after extracting the sentences from it.
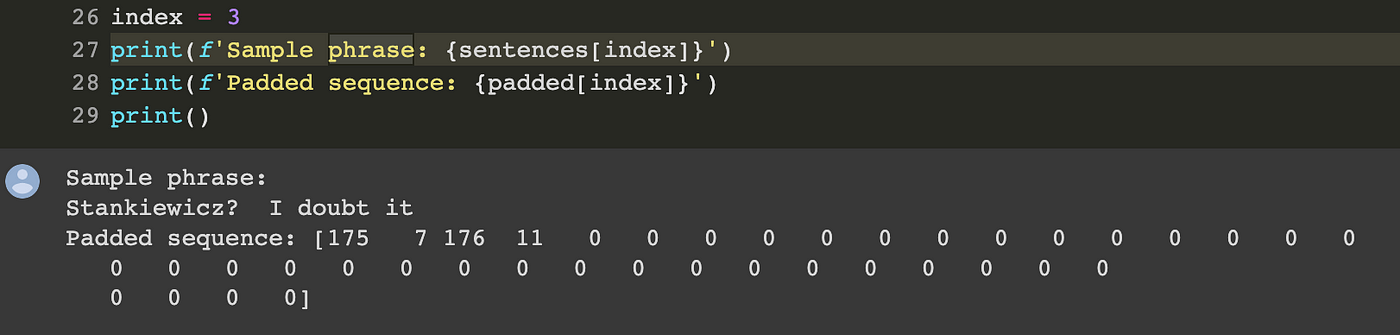
Observe that within the code there may be publish as padding mode. Which means zeros are inserted post-sequence, thus stretching the vector after the tokenized worth and never earlier than.
And right here’s how tokenization and padding are utilized to texts to ship them to a neural community on Tensorflow. You probably have any questions or considerations, depart a remark and I’ll be sure you comply with up.
Till subsequent time!

{kind=link}