
On this article we’ll discover easy methods to standardize knowledge in Python.

Desk of Contents
- Introduction
- What’s standardization
- Standardization instance
- The best way to standardize knowledge in Python
- Conclusion
One of many first steps in function engineering for a lot of machine studying fashions is guaranteeing that the information is scaled correctly.
Some fashions, reminiscent of linear regression, KNN, and SVM, for instance, are closely affected by options with completely different scales.
Different, reminiscent of resolution bushes, bagging, and boosting algorithms typically don’t require any knowledge scaling.
The extent of impact of options’ scales on the talked about fashions is excessive, and options with bigger ranges of values will play a much bigger function within the resolution making of the algorithm since impacts they produce have bigger impact on the outputs.
In such circumstances, we flip to function scaling to assist us discover frequent stage for all these options to be evaluated equally when coaching the mannequin.
Two of the preferred function scaling methods are:
- Z-Rating Standardization
- Min-Max Normalization
On this article, we’ll talk about easy methods to carry out z-score standardization of knowledge utilizing Python.
To proceed following this tutorial we’ll want the next two Python libraries: sklearn and pandas.
Should you don’t have them put in, please open “Command Immediate” (on Home windows) and set up them utilizing the next code:
pip set up sklearn
pip set up pandas
In statistics and machine studying, knowledge standardization is a technique of changing knowledge to z-score values based mostly on the imply and normal deviation of the information.
The ensuing standardized worth reveals the variety of normal deviations the uncooked worth is away from the imply.
Mainly every worth of a given function of a dataset might be transformed to a consultant variety of normal deviations that it’s away from the imply of the function.
This may permit us to match a number of options collectively and get extra related data since now all the information might be on the identical scale.
The standardized knowledge could have imply equal to 0 and the values will typically vary between -3 and +3 (since 99.9% of the information is inside 3 normal deviations from the imply assuming your knowledge follows a standard distribution).
Let’s check out the z-score components:
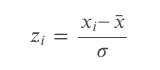
For every function we’ll compute its imply and normal deviation. Then we’ll subtract the imply from every statement and divide it by normal deviation to get the standardized values.
On this part we’ll check out a easy instance of knowledge standardization.
Take into account the next dataset with costs of various apples:
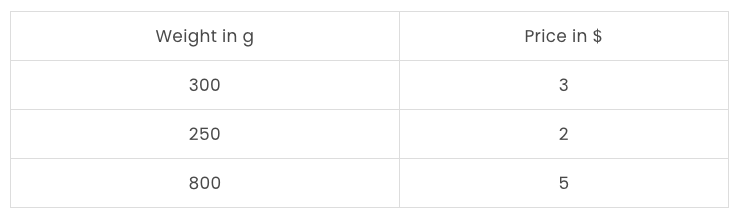
And plotting this dataset ought to appear to be this:
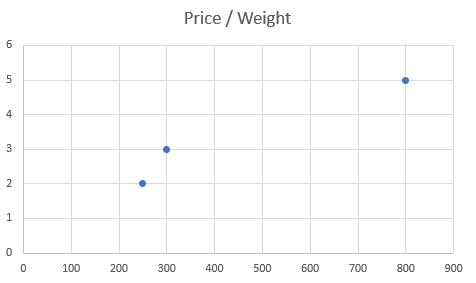
Right here we see a a lot bigger variation of the burden evaluate to cost, however it seems to appears like this due to completely different scales of the information.
The costs vary is between $2 and $5, whereas the burden vary is between 250g and 800g.
Let’s standardize this knowledge!
Begin with the burden function:
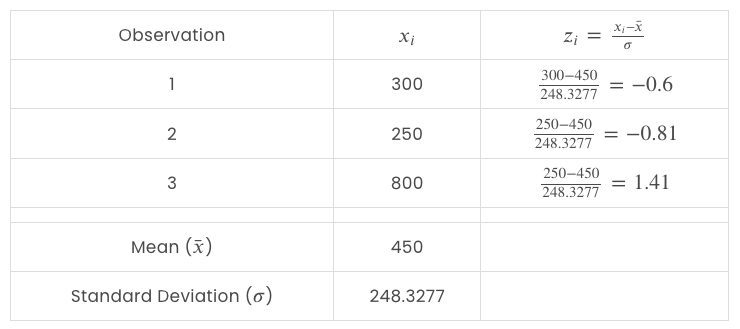
And do the identical for the value function:
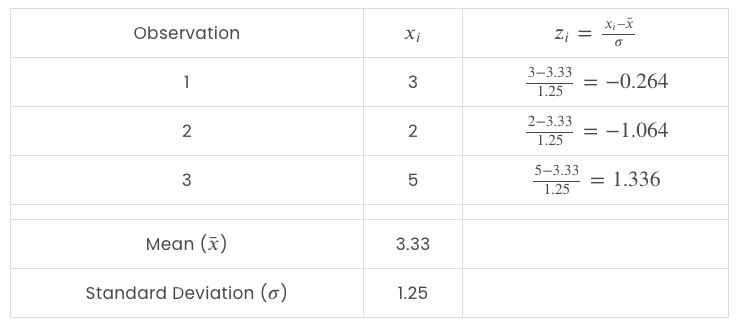
And mix the 2 options into one dataset:

We will now see that the size of the options within the dataset could be very comparable, and when visualizing the information, the unfold between the factors might be smaller:
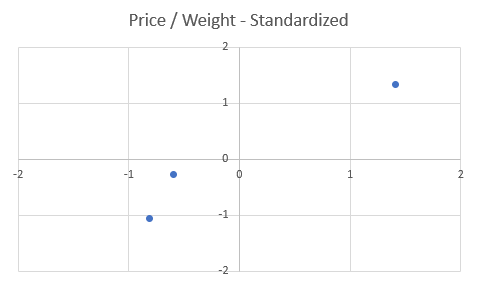
The graph appears virtually similar with the one distinction being the size of the every axis.
Now let’s see how we will recreate this instance utilizing Python!
Let’s begin by making a dataframe that we used within the instance above:
And it’s best to get:
weight value
0 300 3
1 250 2
2 800 5
As soon as now we have the information prepared, we will use the StandardScaler() class and its strategies (from sklearn library) to standardize the information:
And it’s best to get:
[[-0.60404045 -0.26726124]
[-0.80538727 -1.06904497]
[ 1.40942772 1.33630621]]
As you’ll be able to see, the above code returned an array, so the final step can be to transform it to dataframe:
And it’s best to get:
weight value
0 -0.604040 -0.267261
1 -0.805387 -1.069045
2 1.409428 1.336306
which is similar to the consequence within the instance which we calculated manually.
On this tutorial we mentioned easy methods to standardize knowledge in Python.
Knowledge standardization is a vital step in knowledge preprocessing for a lot of machine studying algorithms.
It’s typically a required preprocessing step that adjusts the ranges of options within the enter knowledge to be sure that options with bigger ranges don’t take away all of the explainability of the mannequin by affecting the space metric.
The choice to standardize the information or not primarily relies on the mannequin you might be constructing as a few of them might be simply affected by knowledge ranges (OLS, SVM, and extra), whereas there are fashions that aren’t affected (Logistic regression, Tree based mostly fashions, and extra).
Be happy to depart feedback beneath when you’ve got any questions or have options for some edits and take a look at extra of my Machine Studying articles.

{kind=link}