
The best way to Keep away from Dropping Worthwhile Information Factors (incl. Cheat Sheet)

One widespread pitfall when merging two DataFrames is unintentionally shedding worthwhile information factors. Generally it’s essential lengthen your preliminary dataset with further data from a second dataset. For this, you may learn the 2 datasets into pandas DataFrames after which mix them with the .merge() methodology into one DataFrame. Nevertheless, relying on the way you merge them, you may find yourself with fewer or extra information factors as anticipated.
Nevertheless, relying on the way you merge them, you may find yourself with fewer or extra information factors as anticipated.
This text will go over the 4 most typical strategies to merge two DataFrames. Since merging pandas DataFrames is much like SQL joins, we are going to use them as analogies [1]. Specifically, we are going to showcase easy methods to conduct:
- LEFT OUTER JOIN (pandas: “left”)
- RIGHT OUTER JOIN (pandas: “proper”)
- FULL OUTER JOIN (pandas: “outer”)
- INNER JOIN (pandas: “interior”)
Additionally, we are going to present you how one can confirm your outcomes.
To elucidate the ideas we are going to use the next two minimal fictional datasets. On this instance, we have now two tables for pandas in zoos. The primary desk comprises the situation details about zoos. The second desk comprises details about which panda is wherein zoo.

The DataFrames are coloured for instance which entries end result from which DataFrame within the following examples. When merging two DataFrames, you seek advice from them as “left” and “proper” DataFrame. On this instance, df1 is the left DataFrame and is coloured in blue. df2 is the appropriate DataFrame and is coloured in yellow. If an entry within the merged DataFrame outcomes from each DataFrames, it will likely be indicated with a inexperienced row background.
- Left DataFrame:
df1, coloured in blue - Proper DataFrame:
df2, coloured in yellow - Key column: Widespread column to merge
df1anddf2on. On this instance, the important thing column is “zoo_id”. - Merged DataFrame:
df_mergedwith rows from left in blue, from proper in yellow, and from each in inexperienced
Let’s take a look on the .merge() methodology and its important parameters. This methodology has extra parameters than these mentioned under. Nevertheless, we are going to solely contact on these which might be related to this text. You may seek advice from the documentation [2] for additional parameters.
DataFrame.merge(proper,
how = "...",
on = None,
indicator = False,
...)
First, you name the .merge() methodology from the left Dataframe df1 and the primary parameter is the left DataFrame df2.
df_merged = df1.merge(df2)
You may additionally merge two DataFrames as follows, the place the primary argument is the left DataFrame and the second argument is the appropriate DataFrame:
df_merged = pd.merge(df1, df2)
Whereas the .merge() methodology is sensible sufficient to seek out the widespread key column to merge on, I might advocate to explicitly outline it with the parameter on. Not solely does it make your code extra readable, however this additionally hastens the execution time.
df_merged = df1.merge(df2,
on = "zoo_id")
If the important thing columns don’t have an equivalent identify in each DataFrames, you need to use the parameters on_left and on_right as an alternative of on.
df_merged = df1.merge(df2,
on_left = "key1",
on_right = "key2")
To point from which DataFrame a row within the merged DataFrame resulted from, we are going to use the parameter indicator = True. This selection will create a brand new column “_merge” within the merged DataFrame as you will note within the following examples. For the common utilization of merging DataFrames, you may omit the indicator parameter.
What in the event you would wish to get the massive image of each panda and each zoo?

For this, you’d use a FULL OUTER JOIN in SQL converse [1].
SELECT *
FROM df1
FULL OUTER JOIN df2
ON df1.zoo_id = df2.zoo_id;
In pandas, you’d use how = "outer" [2].
df_merged = df1.merge(df2,
on = "zoo_id",
how = "outer",
indicator = True)
Under you may see each risk to match every row from each DataFrames through the important thing column. The values 101, 102, and 103 seem in each key columns of each DataFrames. A match with each DataFrames is indicated with a inexperienced dot on the intersection of the 2 DataFrames.
Nevertheless, the worth 104 solely seems in the important thing column of the left DataFrame and the worth 105 solely seems in the important thing column of the appropriate DataFrame. The unrivaled rows are indicated with a blue or yellow dot respectively on the intersection with a line known as “no match”.
A full outer be a part of comprises all of the dots within the under determine.
What in the event you would wish to get the massive image of each panda and each zoo?

As a sanity verify, the anticipated size of the merged DataFrame needs to be longer than or equal to the size of the longer DataFrame. The merged DataFrame df_merged has a complete of seven rows: 4 from each, one from left solely, and two from proper solely as indicated within the column _merge.
Whereas the inexperienced rows include no NULL values, the blue and yellow rows have lacking values. Because the inexperienced rows end result from each DataFrames, every column has a price. Nevertheless, because the left DataFrame df2 didn’t include any pandas residing within the zoo with the zoo_id = 104, the column panda_name is nan for row 4. The identical goes for the yellow rows 5 and 6 since df1 didn’t include any details about the zoo with the zoo_id = 105.
However what in the event you would wish to have a look at solely zoos which home pandas?

For this, you’d use an INNER JOIN in SQL converse [1].
SELECT *
FROM df1
INNER JOIN df2
ON df1.zoo_id = df2.zoo_id;
In pandas, you’d use how = "interior" [2].
df_merged = df1.merge(df2,
on = "zoo_id",
how = "interior",
indicator = True)
Within the under determine, you may once more see the matches as described for the FULL OUTER JOIN. Nevertheless, an INNER JOIN solely considers the inexperienced dots, which point out {that a} worth is current in each key columns of each DataFrames. The unrivaled values (blue and yellow dots from FULL OUTER JOIN) are excluded as illustrated within the above panda Venn diagram.
However what in the event you would wish to have a look at solely zoos which home pandas?
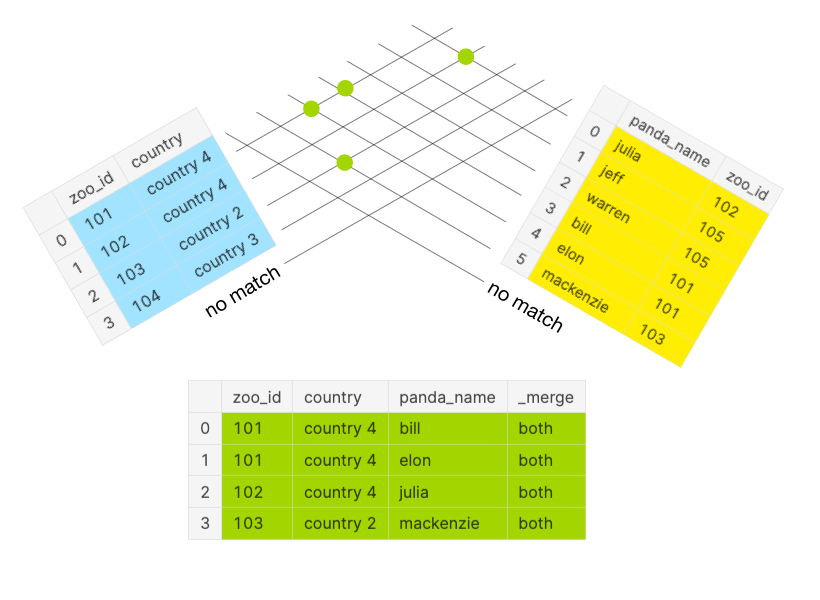
As a sanity verify, the anticipated size of the merged DataFrame needs to be longer than or equal to the size of the shorter DataFrame. The merged DataFrame df_merged has a complete of 4 rows: 4 from each as indicated within the column _merge.
Now, let’s say you’d wish to know for each zoo which pandas it homes. E.g., with this data, you may calculate, what number of pandas every zoo has.

For this, you’d use a LEFT OUTER JOIN in SQL converse [1].
SELECT *
FROM df1
LEFT OUTER JOIN df2
ON df1.zoo_id = df2.zoo_id;
In pandas, you’d use how = "left" [2].
df_merged = df1.merge(df2,
on = "zoo_id",
how = "left",
indicator = True)
Within the under determine, you may once more see the matches as described for the FULL OUTER JOIN. Nevertheless, a LEFT OUTER JOIN solely considers the inexperienced and blue dots as illustrated within the above panda Venn diagram. The unrivaled values from the appropriate DataFrame (yellow dots from FULL OUTER JOIN) are excluded.
Let’s say you’d wish to calculate what number of pandas every zoo has.
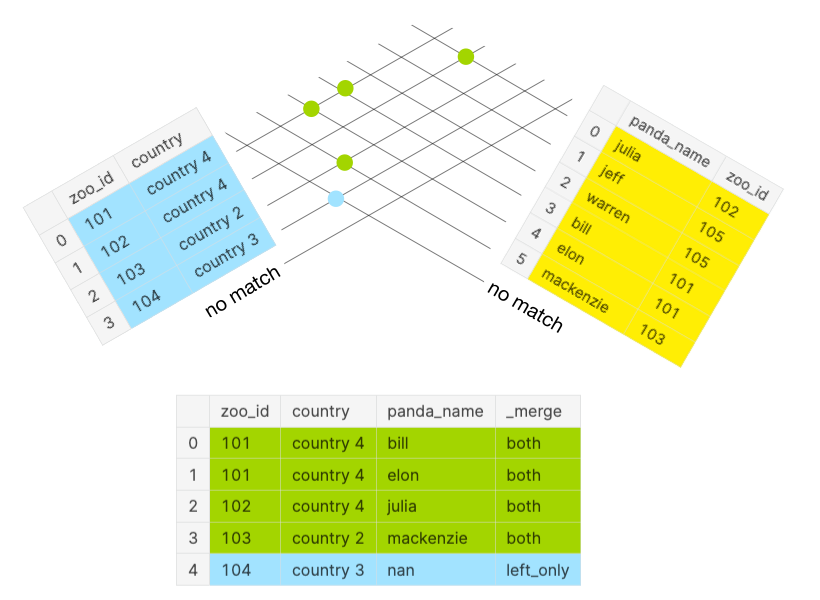
As a sanity verify, the anticipated size of the merged DataFrame needs to be longer than or equal to the size of the left DataFrame. The merged DataFrame df_merged has a complete of 5 rows: 4 from each and one from left solely as indicated within the column _merge.
Lastly, let’s say you’d wish to know for each panda wherein zoo it lives.

For this, you’d use a RIGHT OUTER JOIN in SQL converse [1].
SELECT *
FROM df1
RIGHT OUTER JOIN df2
ON df1.zoo_id = df2.zoo_id;
In pandas, you’d use how = "proper" [2].
df_merged = df1.merge(df2,
on = "zoo_id",
how = "proper",
indicator = True)
Within the under determine, you may once more see the matches as described for the FULL OUTER JOIN. Nevertheless, a RIGHT OUTER JOIN solely considers the inexperienced and yellow dots as illustrated within the above panda Venn diagram. The unrivaled values from the left DataFrame (blue dots from FULL OUTER JOIN) are excluded.
Let’s say you’d wish to know for each panda wherein zoo it lives.
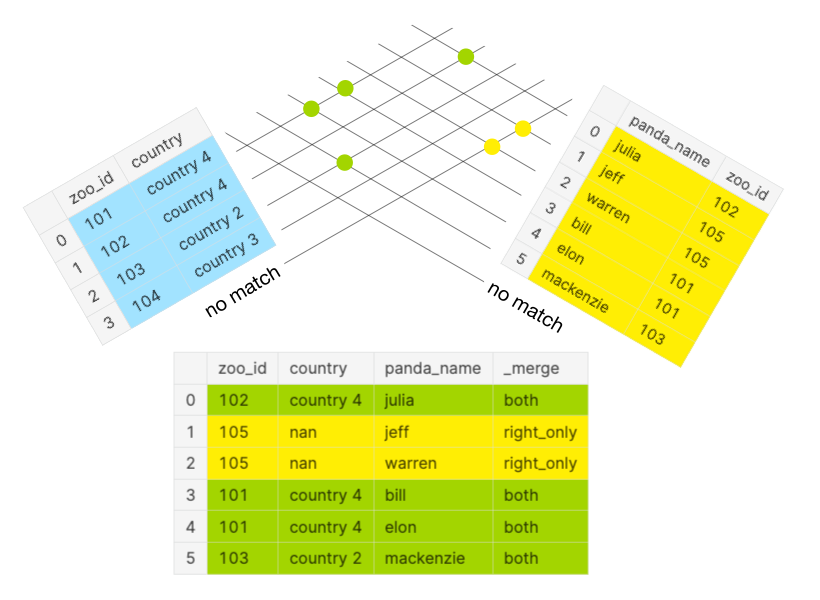
As a sanity verify, the anticipated size of the merged DataFrame needs to be longer than or equal to the size of the appropriate DataFrame. The merged DataFrame df_merged has a complete of six rows: 4 from each and two from proper solely as indicated within the column _merge.
This text (actually) illustrated easy methods to merge two pandas DataFrames with the .merge() methodology. Specifically, we checked out easy methods to conduct the commonest forms of SQL joins in pandas: FULL OUTER JOIN, INNER JOIN, LEFT OUTER JOIN, and RIGHT OUTER JOIN.
Under you will discover a visible abstract of this text as a cheat sheet:

[1] “pandas 1.4.2 documentation”, “Comparability with SQL.” pandas.pydata.org. https://pandas.pydata.org/docs/getting_started/comparability/comparison_with_sql.html#be a part of (accessed July 13, 2022)
[2] “pandas 1.4.2 documentation”, “pandas.DataFrame.merge.” pandas.pydata.org. https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.merge.html (accessed July 13, 2022)

{kind=link}