A concise, methodical information, from analysis query definition to community construction estimation.

This text explores the methods for setting up community buildings from textual content information. It’s the second a part of the sequence on textual content community evaluation in Python. As a previous, please learn my opening article that describes the principle ideas of textual content community evaluation (the article is right here). We’ll observe the steps outlined by (Borsoom et al., 2021) and briefly launched within the earlier article.

Additional steps past defining the analysis query rely on the construction of our information. Due to this fact the key query to ask proper at the start is: What’s the enter to the community mannequin?
We’d work with:
- uncooked, unprocessed information
- cleaned information with nodes-edges construction
We are able to additionally flip the primary into the second and rework the uncooked information, clear it and create the nodes-edges construction.
First, let’s begin with a query to reply:
Analysis query: what terminology is shared between analysis fields in journal article titles?
Analysis Articles Dataset from Kaggle containing abstracts for journal articles on six subjects (Laptop Science, Arithmetic, Physics, Statistics, Quantitative Biology, and Quantitative Finance) is a good choice to illustrate coding in Python. The info license is right here.
Here’s what it appears to be like like:

Textnets has been developed on account of Bail’s (2016) PNAS paper. It exists each in Python and R implementations. By default, it makes use of the Leiden algorithm for neighborhood detection in textual content information. This group of algorithms helps uncover the construction of huge and sophisticated networks and determine teams of nodes which can be related amongst themselves however sparsely related to the remainder of the community (see Traag et al., 2019, Yang et al., 2016). Be taught extra about different detection algorithms right here.
Implementation
Let’s see the way it works. First, we import Textnets and Pandas, and browse the information. You will need to set index_col='research_field' to attract the graph appropriately (see the whole code on my GitHub). Subsequent, we construct the corpus from the column of article titles. We use a subset representing 10 article titles from every analysis discipline to make the community for illustration easier.
Textnets then removes cease phrases, applies stemming, removes punctuation marks, numbers, URLs, and the like, and creates a textual content community. mind_docs specifies the minimal variety of paperwork a time period should seem in to be included within the community.
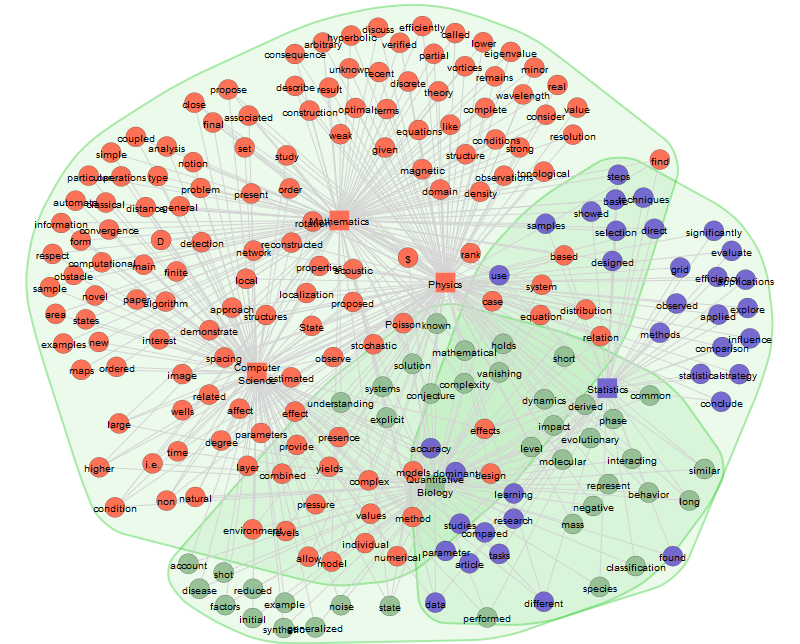
Now, let’s plot the community. The show_clusterschoices marks the partitions discovered by the Leiden detection algorithm. It identifies doc–time period teams that seem to type a part of the identical theme within the texts.
Right here is the online we get:

Findings
We are able to clearly distinguish key phrases which can be shared by multiple analysis discipline. These are, e.g., “time” and “danger” (Quantitative Finance — Laptop science), “deep” and “empirical” (Arithmetic — Statistics — Laptop Science), — Arithmetic), or “topic” and “reminiscence” (Quantitative Biology — Laptop Science).
These findings strongly rely on the pattern measurement. The richer dataset we have now, the extra exact outcomes we get hold of. We are able to draw the community construction in lots of different methods, relying on the analysis query we set at the start. Check out the Textnets tutorial right here.
We are able to work with information with a transparent nodes-edges construction that always entails cleansing and pre-processing. To discover attainable situations, let’s use the IMDb 50K Film Opinions dataset, which accommodates film evaluations, and their evaluated sentiment (optimistic/detrimental). The info license is right here.
NetworkX is a Python library for the creation and research of advanced networks. It’s a extremely developed package deal containing in depth documentation that attracts networks in lots of tutorials and e-books. Hagberg et al. (2008), who co-authored the package deal, current the interior NetworkX construction. It might probably show varied community buildings; textual content information normally require some transformation to function the enter.
Textual content networks are sometimes used to show key phrase co-occurrences in a textual content (Shim et al., 2015; Krenn and Zeilinger, 2020, and lots of others). We’ll use the identical strategy, and, for instance use case, we have an interest within the associations of film reviewers to the well-known Matrix movie.
The info consists of two units of nodes: the monitored film title (Matrix) and a bunch of chosen film titles that reviewers could affiliate with Matrix. Edges are represented by co-occurrences of the nodes in the identical assessment. The sting solely exists if a reviewer mentions the monitored and an related film title in the identical assessment.
The analysis query: which fashionable sci-fi motion pictures are primarily related to Matrix?
The information has the next construction:

Implementation
After studying the information, let’s do some easy transformation and exploratory steps that helps us to grasp the graph and plot it propperly.
- Calculate edge measurement
To quantify edges, we create a separate column edge_width in our information with the dimensions for each edge within the node2 column.
2. Create the graph and print the nodes and edges to forestall attainable misinterpretations
3. Plot a community chart
After a quick inspection that no surprising errors happen, we transfer on, form the unique G graph right into a star graph, hold the properties of the graph in choices, and plot it with matplotlib.
The code plots this lovely community star graphics:

Findings: the information shouldn’t be very wealthy for film titles, however the community evaluation means that the reviewer’s largely affiliate Matrix with Thor and Tron. It appears apparent after a quick information inspection with such a small dataset. Think about, nonetheless, that you’ve got a bigger dataset with a substantial quantity of nodes. Right here, community evaluation enormously helps to explain the dataset.
This text couldn’t present a wholly exhausting assessment of textual content community development strategies. I’ve omitted an in depth overview of varied community buildings since there are a number of sources on the web. As a substitute, it outlined a few methodological factors on this space.
To summarize, listed here are a number of tricks to observe:
- First, clearly outline the analysis query in your specific challenge. Textual content community evaluation is an empirical strategy to supply the solutions.
- Subsequent, check out the dataset construction. If the analysis query requires information transformation, do it.
- The created community may not be the ultimate output of the evaluation however slightly an object for extra advanced investigations: graphics, machine studying mannequin, forecasting, and so on.
The whole code is on my GitHub.
The next article on this sequence will shed extra mild on easy and extra advanced graphs for textual content information evaluation. The ultimate piece will discover the latest state-of-the-art software of semantic networks for forecasting. Keep up to date!
PS: You’ll be able to subscribe to my e mail checklist to get notified each time I write a brand new article. And if you’re not a Medium member but, you’ll be able to be a part of right here.
[1] Bail, A., C. 2016. Combining pure language processing and community evaluation to look at how advocacy organizations stimulate dialog on social media. Proceedings of the Nationwide Academy of Sciences, vol. 113, no. 42.
[2] Borsboom, et al. 2021. Community evaluation of multivariate information in psychological science. Nature Opinions, vol. 1, no. 58.
[3] Hagberg, A., A., Schult, D., A., Swart, P., J. 2008. Exploring community construction, dynamics, and performance utilizing NetworkX, in Proceedings of the seventh Python in Science Convention (SciPy2008), Gäel Varoquaux, Travis Vaught, and Jarrod Millman (Eds), (Pasadena, CA USA), pp. 11–15, Aug 2008.
[4] Krenn, M., Zeilinger, A. 2020. Predicting analysis developments with semantic and neural networks with an software in quantum physics. Proceedings of the Nationwide Academy of Sciences, vol. 117, no. 4.
[5] Shim, J., Park, C., Wilding, M. 2015. Figuring out coverage frames by semantic community evaluation: an examination of nuclear vitality coverage throughout six international locations. Coverage Sciences, vol. 48.
[6] Traag, V. A., Waltman, L., Van Eck, N. J. 2019. From Louvain to Leiden: guaranteeing well-connected communities. Scientific Studies, vol. 9, no. 5233.
[7] Yang, Z., Algesheimer, R., Tessone, C. J. 2016. A Comparative Evaluation of Neighborhood Detection Algorithms on Synthetic Networks. Scientific Studies, vol. 6, no. 30750.

{kind=link}