When Tachyum unveiled the idea of its Prodigy Common Processor at Sizzling Chips 18, it made fairly a splash with a chip designed to run any code utilizing a dynamic binary translator. It demonstrated excessive efficiency when executing each native and translated code. It took the corporate some time to design the precise {hardware}, taking pre-orders on analysis kits (opens in new tab); the corporate additionally discloses the precise specs of its Prodigy. They definitely look spectacular, however they’re additionally scary with a 950W thermal design energy per chip.
Formidable Efficiency at Formidable Energy
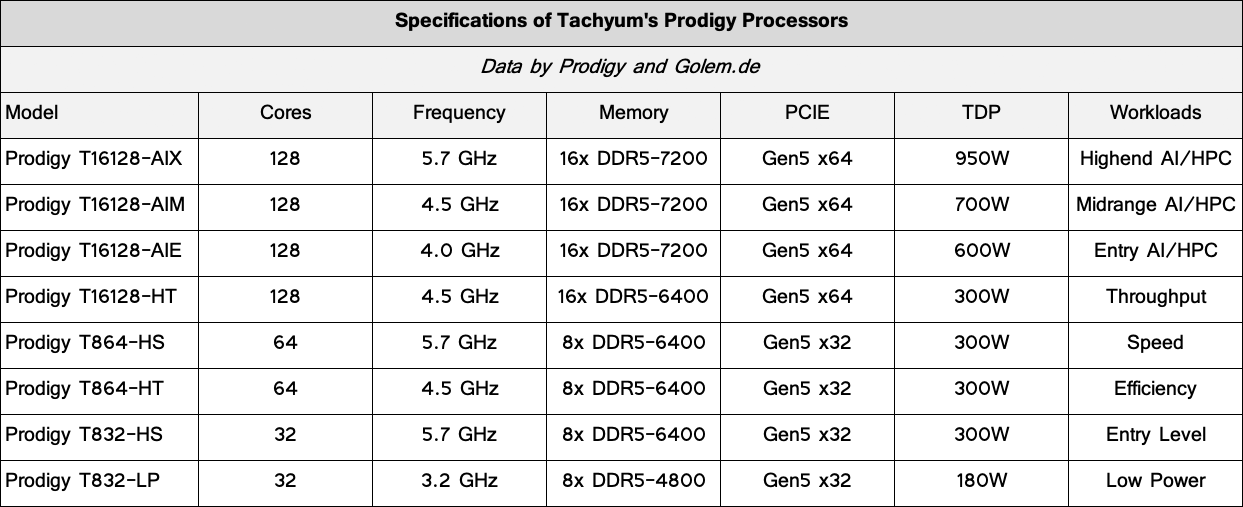
Every Tachyum Prodigy processor has as much as 128 proprietary cores mated with 16 DDR5 reminiscence channels (for a 1,024-bit interface) supporting as much as 7200 MT/s information switch fee (and due to this fact offering as much as 921.6 GBps of bandwidth) in addition to 64 PCIe 5.0 lanes. As well as, the chip helps as much as 8TB of DDR5 reminiscence in complete, which is consistent with what we’ll see with upcoming server CPUs from different makers. As for clock charges, Tachyum’s Prodigy is designed to run as much as 5.7 GHz and is a product of TSMC’s performance-optimized N5P course of expertise.
(Picture credit score: Golem.de)
On the subject of efficiency, Tachyum expects its flagship Prodigy T16128-AIX processor (opens in new tab) to supply as much as 90 FP64 TFLOPS for HPC in addition to as much as 12 ‘AI PetaFLOPS’ for inference and coaching, presumably when operating native code and consuming as much as 950W (and utilizing liquid cooling), based on specs printed (opens in new tab) by the corporate and at Golem.de (opens in new tab). In the meantime, Tachyum’s Prodigy processors can work in 2-way and 4-way configurations. To place the numbers into context, AMD’s Intuition MI250X has a peak throughput of 96 FP64 TFLOPS for HPC at about 560W. In distinction, Nvidia’s H100 SXM5 can present as much as 20 INT8/FP8 PetaOPS/PetaFLOPS for AI (as much as 40 PetaOPS/PetaFLOPS with sparsity) at 700W. But, neither compute GPUs perform for general-purpose workloads. And that is precisely when it will get fascinating.
A New CPU Is Born
Tachyum’s Prodigy is a common homogeneous processor packing as much as 128 proprietary 64-bit VLIW cores that characteristic two 1024-bit vector models per core and one 4096-bit matrix unit per core. As well as, every core incorporates a 64KB instruction cache, a 64KB information cache, 1MB L2 cache, and might make the most of unused L2 caches of different cores as a sufferer L3 cache.
(Picture credit score: Tachyum)
Tachyum’s VLIW cores are in-order cores, however when compiler makers correct optimizations, they’ll assist 4-way out-of-order points, based on Radoslav Danilak, chief government and co-founder of Tachuym, who spoke with Golem.de (opens in new tab). He additionally re-emphasized that the Prodigy instruction set structure can obtain a really excessive instruction stage parallelism with software program utilizing so-called poison bits.



{kind=link}