Multi-Chassis Hyperlink Aggregation (MLAG) – the flexibility to terminate a Port Channel/Hyperlink Aggregation Group on a number of switches – is among the extra convoluted bridging applied sciences. In spite of everything, it’s not trivial to steer two containers to behave like one and deal with the myriad nook circumstances appropriately.
On this sequence of deep dive weblog posts, we’ll discover the intricacies of MLAG, beginning with the info aircraft concerns and the management aircraft necessities ensuing from the info aircraft quirks. If you happen to surprise why we’d like all that complexity, keep in mind that Ethernet networks nonetheless attempt to emulate the historical thick yellow cable that would lose some packets however might by no means reorder packets or ship duplicate packets.
To make issues worse, some purposes working straight on high of Ethernet would abruptly drop their classes when confronted with a single reordered or duplicated packet, making IEEE extraordinarily cautious. In recent times, they relaxed a bit – the 802.1AX-2020 commonplace claims to offer “low threat of duplication or misordering” – however it’s nonetheless dangerous type to mess issues up. Who is aware of, even a UDP-based software with out application-level sequence numbers might get confused.
All through the sequence, we’ll use a easy topology with two switches in an MLAG cluster and three varieties of nodes hooked up to them:
- Hosts with a single uplink linked to one of many switches – X and Y
- Hosts linked to each switches with a hyperlink aggregation group (LAG) – A and B
- Host with a failed LAG member – C
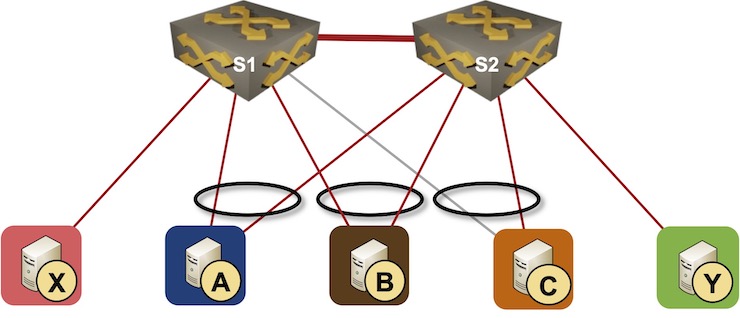
Easy MLAG topology
The nodes which have functioning hyperlinks with a single member of an MLAG cluster are generally known as orphan nodes. We’ll use that time period no matter whether or not the node is utilizing LACP or not – the orphan nodes in our topology are X, Y, and C (as a result of the hyperlink between S1 and C is down).
MLAG members want a data-plane path between them to ahead frames between orphan nodes (instance: between X and Y). Standalone MLAG implementations often use a devoted peer hyperlink. Some implementations use the community core (cloth) to trade knowledge between MLAG members; we’ll dive into the complexities of changing a peer hyperlink with a material interconnect in a future weblog submit.
Peer Hyperlink Failure
Implementations utilizing a peer hyperlink can’t stay with out it; it’s essential to make the peer hyperlink as dependable as potential. Most design guides inform you to make use of a number of parallel hyperlinks in a LAG (as a result of we’re in a bridged world) linked to a number of linecards in case you use a chassis change.
Even then, what ought to we do if a peer hyperlink fails? The minority a part of the cluster has to take away straight linked LAG member hyperlinks from the hyperlink aggregation teams, and the best manner to try this is to close them down.
The “shut down the LAG members” strategy might need unintended penalties. In our state of affairs, if S2 decides it has to try this, C will get disconnected from the community. Sadly, we will do nothing about that.
Smarter MLAG implementations (instance: Cumulus Linux) attempt to get better from the catastrophe if they’re moderately certain that the first MLAG member might need failed. In that case, the secondary MLAG member has to:
- Drop from the cluster
- Cease utilizing cluster-wide LACP system ID and system MAC handle
- Revert to the native LACP system ID and system MAC handle.
- Restart LACP classes utilizing a distinct system ID hoping that the distant nodes don’t get confused.
Correctly carried out distant nodes would renegotiate LACP session with the standalone former member of the MLAG cluster in the event that they misplaced contact with the first MLAG member, or reject the try and renegotiate the LACP session if the first MLAG member remains to be operational (and we skilled community partitioning).
.
Lastly, how do you determine which a part of a two-node cluster is within the minority? Welcome to the By no means Take Two Chronometers to the Sea land. MLAG implementations go to nice lengths attempting to determine whether or not the opposite cluster member failed (by which case the LAG members ought to stay lively) or whether or not the opposite node remains to be lively, however not reachable over the failed peer hyperlink.
Utilizing BFD throughout cloth uplinks is fairly frequent and doesn’t rely on help of third-party units. Some implementations additionally attempt to attain the opposite MLAG member over the hooked up LAGs. This may solely work if the distant gadget is keen to resend the probe onto one other LAG member by way of its management aircraft – an IEEE bridge shouldn’t be imagined to ahead a packet to a hyperlink by way of which it has been acquired, and the entire LAG is handled as a single hyperlink. There is no such thing as a commonplace strategy to ship probes by way of LAG-attached purchasers; distributors supporting this performance have developed incompatible proprietary options.
In our topology, S1 and S2 can’t use BFD as they don’t have cloth uplinks. They may attempt to ship probes by way of A and B, however that will solely work if A and B assisted them, which implies that S1, S2, A, and B must be switches from the identical vendor.
Primary Management Airplane Setup
Earlier than discussing the data-plane particulars, we have now to get working hyperlink aggregation teams between S1/S2 and A, B, and C. S1 and S2 should faux they’re a single gadget – they need to use the identical LACP system ID and the identical system MAC handle. To get that achieved, we’d like a control-plane protocol that can:
- Confirm that the opposite switches within the MLAG cluster work as anticipated.
- Agree on the IEEE bridge and LACP parameters (system ID, system precedence, and port precedence) with the opposite cluster members. Multi-Chassis LACP (mLACP) Software Procedures a part of RFC 7275 (ICCP) describes a pattern implementation.
- Trade port/LAG state between MLAG cluster members to determine orphan nodes.
ICCP is a control-plane protocol that does all the above, however we would want extra. We’ll uncover the extra control-plane options wanted in an MLAG cluster whereas determining tips on how to make layer-2 and layer-3 forwarding work.
Revision Historical past
- 2022-06-01
- Up to date the what can secondary change do after peer hyperlink failure a part of the weblog submit primarily based on suggestions by Erik Auerswald. Additionally added just a few extra particulars on peer failure detection.

{kind=link}