
The speedy development of data-intensive use instances equivalent to simulations, streaming purposes (like IoT and sensor feeds), and unstructured knowledge has elevated the significance of performing quick database operations equivalent to writing and studying knowledge—particularly when these purposes start to scale. Nearly any part in a system can doubtlessly change into a bottleneck, from the storage and community layers by the CPU to the applying GUI.
As we mentioned in “Optimizing metadata efficiency for web-scale purposes,” one of many principal causes for knowledge bottlenecks is the way in which knowledge operations are dealt with by the info engine, additionally known as the storage engine—the deepest a part of the software program stack that kinds and indexes knowledge. Information engines had been initially created to retailer metadata, the important “knowledge concerning the knowledge” that firms make the most of for recommending motion pictures to look at or merchandise to purchase. This metadata additionally tells us when the info was created, the place precisely it’s saved, and rather more.
Inefficiencies with metadata typically floor within the type of random learn patterns, sluggish question efficiency, inconsistent question conduct, I/O hangs, and write stalls. As these issues worsen, points originating on this layer can start to trickle up the stack and present to the tip consumer, the place they’ll present in type of sluggish reads, sluggish writes, write amplification, area amplification, lack of ability to scale, and extra.
New architectures take away bottlenecks
Subsequent-generation knowledge engines have emerged in response to the calls for of low-latency, data-intensive workloads that require vital scalability and efficiency. They allow finer-grained efficiency tuning by adjusting three kinds of amplification, or writing and re-writing of information, which are carried out by the engines: write amplification, learn amplification, and area amplification. In addition they go additional with extra tweaks to how the engine finds and shops knowledge.
Speedb, our firm, architected one such knowledge engine as a drop-in substitute for the de facto business commonplace, RocksDB. We open sourced Speedb to the developer neighborhood based mostly on expertise delivered in an enterprise version for the previous two years.
Many builders are aware of RocksDB, a ubiquitous and interesting knowledge engine that’s optimized to take advantage of many CPUs for IO-bound workloads. Its use of an LSM (log-structured merge) tree-based knowledge construction, as detailed within the earlier article, is nice for dealing with write-intensive use instances effectively. Nonetheless, LSM learn efficiency will be poor if knowledge is accessed in small, random chunks, and the difficulty is exacerbated as purposes scale, significantly in purposes with giant volumes of small information, as with metadata.
Speedb optimizations
Speedb has developed three strategies to optimize knowledge and metadata scalability—strategies that advance the state-of-the-art from when RocksDB and different knowledge engines had been developed a decade in the past.
Compaction
Like different LSM tree-based engines, RocksDB makes use of compaction to reclaim disk area, and to take away the previous model of information from logs. Additional writes eat up knowledge assets and decelerate metadata processing, and to mitigate this, knowledge engines carry out the compaction. Nonetheless, the 2 principal compaction strategies, leveled and common, influence the flexibility of those engines to successfully deal with data-intensive workloads.
A short description of every methodology illustrates the problem. Leveled compaction incurs very small disk area overhead (the default is about 11%). Nonetheless, for giant databases it comes with an enormous I/O amplification penalty. Leveled compaction makes use of a “merge with” operation. Particularly, every degree is merged with the following degree, which is normally a lot bigger. Because of this, every degree provides a learn and write amplification that’s proportional to the ratio between the sizes of the 2 ranges.
Common compaction has a smaller write amplification, however ultimately the database wants full compaction. This full compaction requires area equal or bigger than the entire database measurement and will stall the processing of latest updates. Therefore common compaction can’t be utilized in most real-time excessive efficiency purposes.
Speedb’s structure introduces hybrid compaction, which reduces write amplification for very giant databases with out blocking updates and with small overhead in extra area. The hybrid compaction methodology works like common compaction on all the upper ranges, the place the dimensions of the info is small relative to the dimensions of all the database, and works like leveled compaction solely within the lowest degree, the place a good portion of the up to date knowledge is stored.
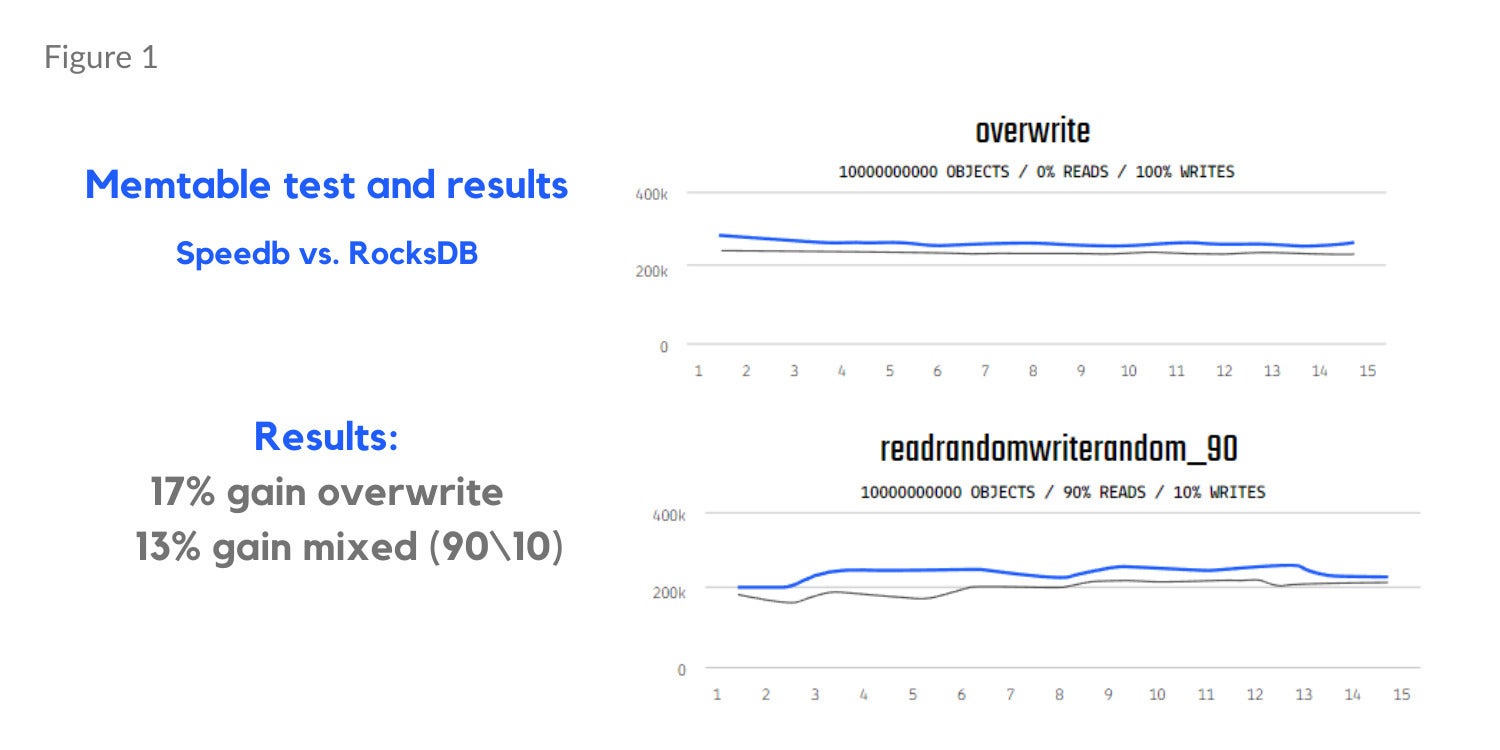
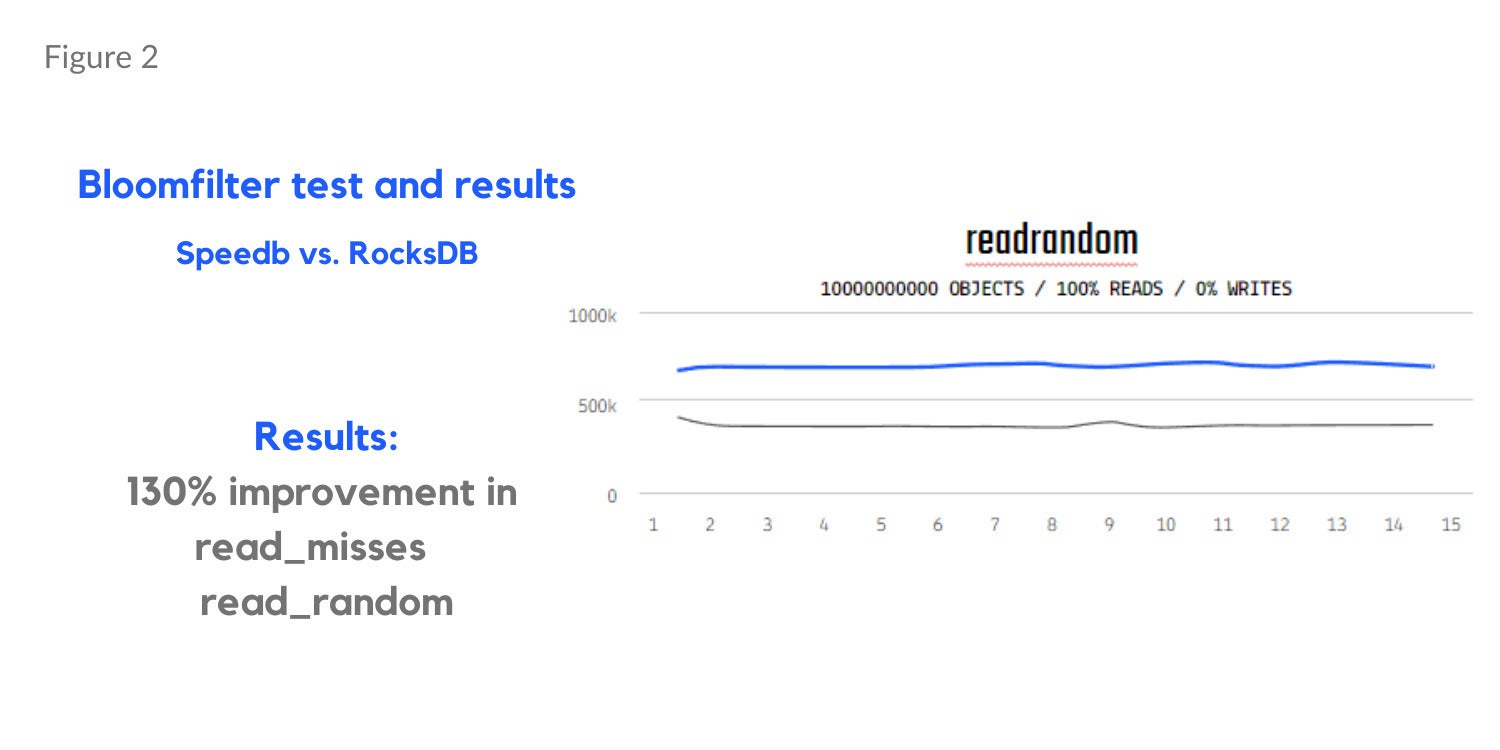
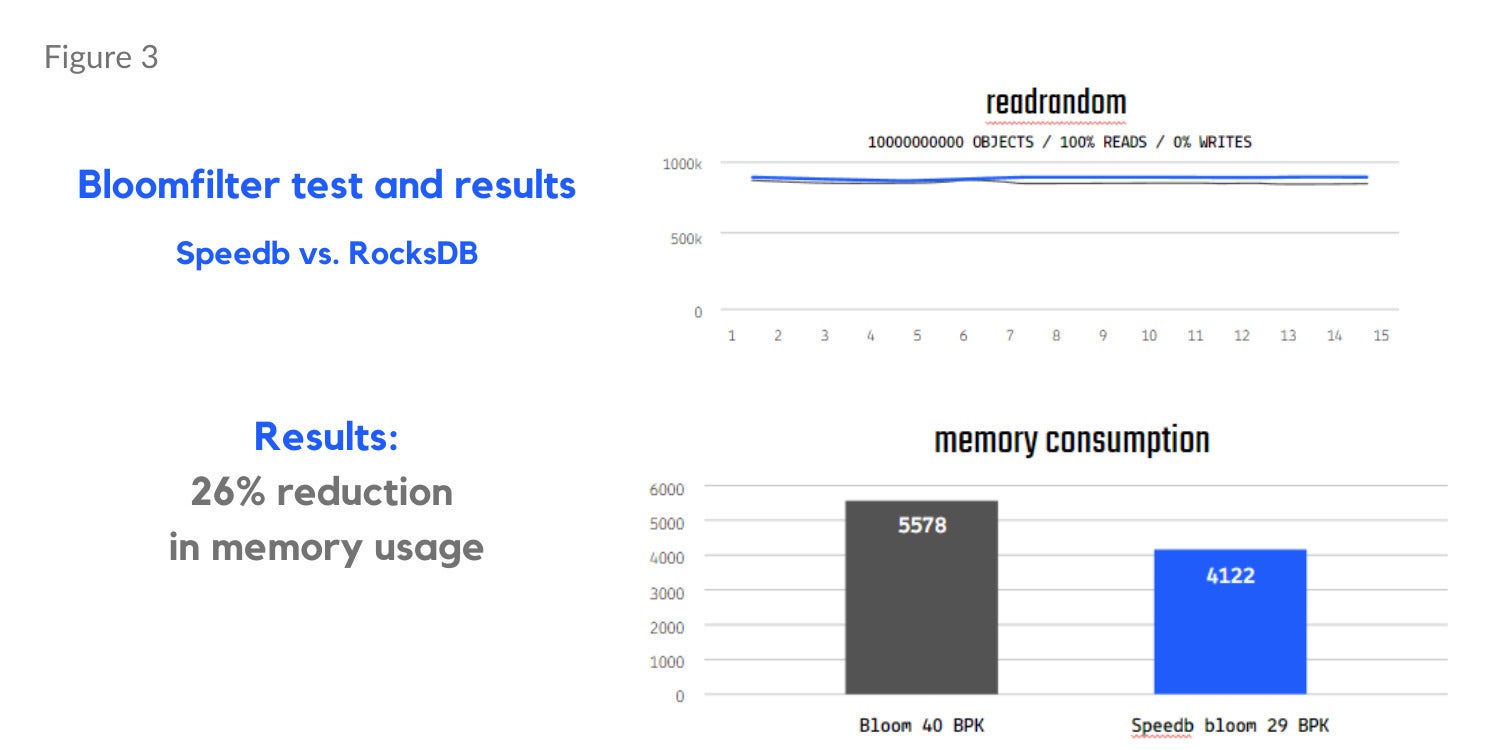
Memtable testing (Determine 1 beneath) exhibits a 17% acquire in overwrite and 13% acquire in blended learn and write workloads (90% reads, 10% writes). Separate bloom filter assessments outcomes present a 130% enchancment in learn misses in a learn random workload (Determine 2) and a 26% discount in reminiscence utilization (Determine 3).
Exams run by Redis display elevated efficiency when Speedb changed RocksDB within the Redis on Flash implementation. Its testing with Speedb was additionally agnostic to the applying’s learn/write ratio, indicating that efficiency is predictable throughout a number of completely different purposes, or in purposes the place the entry sample varies over time.
 Speedb
SpeedbDetermine 1. Memtable testing with Speedb.
 Speedb
SpeedbDetermine 2. Bloom filter testing utilizing a learn random workload with Speedb.
 Speedb
SpeedbDetermine 3. Bloom filter testing exhibiting discount in reminiscence utilization with Speedb.
Reminiscence administration
The reminiscence administration of embedded libraries performs an important position in software efficiency. Present options are complicated and have too many intertwined parameters, making it troublesome for customers to optimize them for his or her wants. The problem will increase because the setting or workload modifications.
Speedb took a holistic strategy when redesigning the reminiscence administration to be able to simplify the use and improve useful resource utilization.
A grimy knowledge supervisor permits for an improved flush scheduler, one which takes a proactive strategy and improves the general reminiscence effectivity and system utilization, with out requiring any consumer intervention.
Working from the bottom up, Speedb is making extra options self-tunable to realize efficiency, scale, and ease of use for a wide range of use instances.
Circulation management
Speedb redesigns RocksDB’s circulate management mechanism to get rid of spikes in consumer latency. Its new circulate management mechanism modifications the speed in a fashion that’s much more average and extra precisely adjusted for the system’s state than the previous mechanism. It slows down when crucial and hastens when it might. By doing so, stalls are eradicated, and the write efficiency is steady.
When the basis trigger of information engine inefficiencies is buried deep within the system, discovering it could be a problem. On the similar time, the deeper the basis trigger, the better the influence on the system. Because the previous saying goes, a series is simply as sturdy as its weakest hyperlink.
Subsequent-generation knowledge engine architectures equivalent to Speedb can enhance metadata efficiency, cut back latency, speed up search time, and optimize CPU consumption. As groups increase their hyperscale purposes, new knowledge engine expertise shall be a important aspect to enabling modern-day architectures which are agile, scalable, and performant.
Hilik Yochai is chief science officer and co-founder of Speedb, the corporate behind the Speedb knowledge engine, a drop-in substitute for RocksDB, and the Hive, Speedb’s open-source neighborhood the place builders can work together, enhance, and share information and greatest practices on Speedb and RocksDB. Speedb’s expertise helps builders evolve their hyperscale knowledge operations with limitless scale and efficiency with out compromising performance, all whereas continually striving to enhance the usability and ease of use.
—
New Tech Discussion board supplies a venue to discover and focus on rising enterprise expertise in unprecedented depth and breadth. The choice is subjective, based mostly on our choose of the applied sciences we consider to be necessary and of biggest curiosity to InfoWorld readers. InfoWorld doesn’t settle for advertising collateral for publication and reserves the fitting to edit all contributed content material. Ship all inquiries to newtechforum@infoworld.com.
Copyright © 2023 IDG Communications, Inc.

{kind=link}