A information to understanding, choosing and deploying Massive Language Fashions
Massive Language Fashions (LLMs) are Deep Studying fashions educated to provide textual content. With this spectacular capability, LLMs have turn out to be the spine of contemporary Pure Language Processing (NLP). Historically, they’re pre-trained by tutorial establishments and massive tech corporations equivalent to OpenAI, Microsoft and NVIDIA. Most of them are then made obtainable for public use. This plug-and-play strategy is a vital step in the direction of large-scale AI adoption — as an alternative of spending enormous sources on the coaching of fashions with normal linguistic data, companies can now concentrate on fine-tuning current LLMs for particular use instances.
Nonetheless, choosing the right mannequin to your software could be difficult. Customers and different stakeholders must make their method by way of a vibrant panorama of language fashions and associated improvements. These enhancements deal with completely different parts of the language mannequin together with its coaching knowledge, pre-training goal, structure and fine-tuning strategy — you may write a e book on every of those points. On prime of all this analysis, the advertising and marketing buzz and the intriguing aura of Synthetic Common Intelligence round enormous language fashions obfuscate issues much more.
On this article, I clarify the primary ideas and ideas behind LLMs. The objective is to supply non-technical stakeholders with an intuitive understanding in addition to a language for environment friendly interplay with builders and AI specialists. For broader protection, the article consists of analyses which might be rooted in a lot of NLP-related publications. Whereas we is not going to dive into mathematical particulars of language fashions, these could be simply retrieved from the references.
The article is structured as follows: first, I situate language fashions within the context of the evolving NLP panorama. The second part explains how LLMs are constructed and pre-trained. Lastly, I describe the fine-tuning course of and supply some steering on mannequin choice.
Bridging the human-machine hole
Language is an enchanting talent of the human thoughts — it’s a common protocol for speaking our wealthy data of the world, and in addition extra subjective points equivalent to intents, opinions and feelings. Within the historical past of AI, there have been a number of waves of analysis to approximate (“mannequin”) human language with mathematical means. Earlier than the period of Deep Studying, representations have been primarily based on easy algebraic and probabilistic ideas equivalent to one-hot representations of phrases, sequential chance fashions and recursive constructions. With the evolution of Deep Studying previously years, linguistic representations have elevated in precision, complexity and expressiveness.
In 2018, BERT was launched as the primary LLM on the premise of the brand new Transformer structure. Since then, Transformer-based LLMs have gained robust momentum. Language modelling is particularly engaging because of its common usefulness. Whereas many real-world NLP duties equivalent to sentiment evaluation, info retrieval and data extraction don’t have to generate language, the belief is {that a} mannequin that produces language additionally has the abilities to unravel a wide range of extra specialised linguistic challenges.
Dimension issues
Studying occurs primarily based on parameters — variables which might be optimized throughout the coaching course of to realize the perfect prediction high quality. Because the variety of parameters will increase, the mannequin is ready to purchase extra granular data and enhance its predictions. Because the introduction of the primary LLMs in 2017–2018, we noticed an exponential explosion in parameter sizes — whereas breakthrough BERT was educated with 340M parameters, Megatron-Turing NLG, a mannequin launched in 2022, is educated with 530B parameters — a greater than thousand-fold enhance.
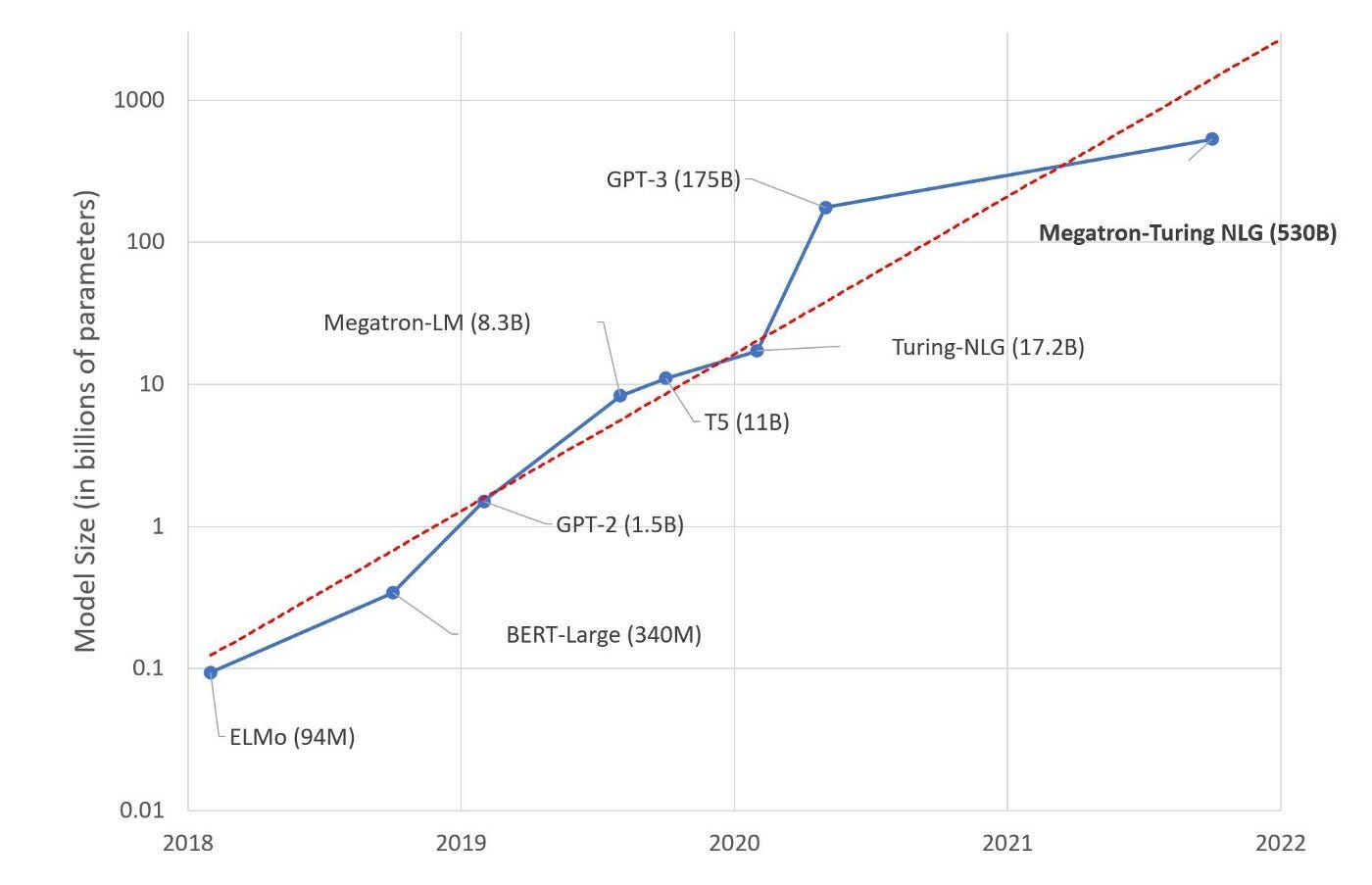
Thus, the mainstream retains wowing the general public with ever greater quantities of parameters. Nonetheless, there have been essential voices declaring that mannequin efficiency is just not growing on the identical charge as mannequin measurement. On the opposite facet, mannequin pre-training can depart a substantial carbon footprint. Downsizing efforts have countered the brute-force strategy to make progress in language modelling extra sustainable.
The lifetime of a language mannequin
The LLM panorama is aggressive and improvements are short-lived. The next chart reveals the top-15 hottest LLMs within the timespan 2018–2022, together with their share-of-voice over time:

We will see that almost all fashions fade in reputation after a comparatively quick time. To remain cutting-edge, customers ought to monitor the present improvements and consider whether or not an improve can be worthwhile.
Most LLMs observe an analogous lifecycle: first, on the “upstream”, the mannequin is pre-trained. As a result of heavy necessities on knowledge measurement and compute, it’s largely a privilege of huge tech corporations and universities. Not too long ago, there have additionally been some collaborative efforts (e.g. the BigScience workshop) for the joint development of the LLM area. A handful of well-funded startups equivalent to Cohere and AI21 Labs additionally present pre-trained LLMs.
After the discharge, the mannequin is adopted and deployed on the “downstream” by application-focussed builders and companies. At this stage, most fashions require an additional fine-tuning step to particular domains and duties. Others, like GPT-3, are extra handy in that they will study a wide range of linguistic duties instantly throughout prediction (zero- or few-shot prediction).
Lastly, time knocks on the door and a greater mannequin comes across the nook — both with an excellent bigger variety of parameters, extra environment friendly use of {hardware} or a extra elementary enchancment to the modelling of human language. Fashions that caused substantial improvements may give start to complete mannequin households. For instance, BERT lives on in BERT-QA, DistilBERT and RoBERTa, that are all primarily based on the unique structure.
Within the subsequent sections, we’ll take a look at the primary two phases on this lifecycle — the pre-training and the fine-tuning for deployment.
Most groups and NLP practitioners is not going to be concerned within the pre-training of LLMs, however fairly of their fine-tuning and deployment. Nonetheless, to efficiently decide and use a mannequin, it is very important perceive what’s going on “below the hood”. On this part, we’ll take a look at the fundamental substances of an LLM:
- Coaching knowledge
- Enter illustration
- Pre-training goal
- Mannequin structure (encoder-decoder)
Every of those will have an effect on not solely the selection, but additionally the fine-tuning and deployment of your LLM.
Coaching knowledge
The info used for LLM coaching is usually textual content knowledge masking completely different kinds, equivalent to literature, user-generated content material and information knowledge. After seeing a wide range of completely different textual content sorts, the ensuing fashions turn out to be conscious of the advantageous particulars of language. Aside from textual content knowledge, code is frequently used as enter, instructing the mannequin to generate legitimate applications and code snippets.
Unsurprisingly, the standard of the coaching knowledge has a direct affect on mannequin efficiency — and in addition on the required measurement of the mannequin. In case you are sensible in getting ready the coaching knowledge, you’ll be able to enhance mannequin high quality whereas decreasing its measurement. One instance is the T0 mannequin, which is 16 occasions smaller than GPT-3 however outperforms it on a spread of benchmark duties. Right here is the trick: as an alternative of simply utilizing any textual content as coaching knowledge, it really works instantly with activity formulations, thus making its studying sign way more focussed. Determine 3 illustrates some coaching examples.

A closing word on coaching knowledge: we frequently hear that language fashions are educated in an unsupervised method. Whereas this makes them interesting, it’s technically flawed. As a substitute, well-formed textual content already offers the mandatory studying indicators, sparing us the tedious means of handbook knowledge annotation. The labels to be predicted correspond to previous and/or future phrases in a sentence. Thus, annotation occurs robotically and at scale, making potential the comparatively fast progress within the area.
Enter illustration
As soon as the coaching knowledge is assembled, we have to pack it into kind that may be digested by the mannequin. Neural networks are fed with algebraic constructions (vectors and matrices), and the optimum algebraic illustration of language is an ongoing quest — reaching from easy units of phrases to representations containing extremely differentiated context info. Every new step confronts researchers with the infinite complexity of pure language, exposing the constraints of the present illustration.
The essential unit of language is the phrase. Within the beginnings of NLP, this gave rise to the naive bag-of-words illustration that throws all phrases from a textual content collectively, irrespectively of their ordering. Contemplate these two examples:

Within the bag-of-words world, these sentences would get precisely the identical illustration since they include the identical phrases. Clearly, it embraces solely a small a part of their that means.
Sequential representations accommodate details about phrase order. In Deep Studying, the processing of sequences was initially carried out in order-aware Recurrent Neural Networks (RNN).[2] Nonetheless, going one step additional, the underlying construction of language is just not purely sequential however hierarchical. In different phrases, we’re not speaking about lists, however about bushes. Phrases which might be farther aside can even have stronger syntactic and semantic ties than neighbouring phrases. Contemplate the next instance:

Right here, her refers to the lady. When an RNN reaches the tip of the sentence and eventually sees her, its reminiscence of the start of the sentence would possibly already be fading, thus not permitting it to get better this relationship.
To resolve these long-distance dependencies, extra complicated neural constructions have been proposed to construct up a extra differentiated reminiscence of the context. The thought is to maintain phrases which might be related for future predictions in reminiscence whereas forgetting the opposite phrases. This was the contribution of Lengthy-Quick Time period Reminiscence (LSTM)[3] cells and Gated Recurrent Models (GRUs)[4]. Nonetheless, these fashions don’t optimise for particular positions to be predicted, however fairly for a generic future context. Furthermore, because of their complicated construction, they’re even slower to coach than conventional RNNs.
Lastly, individuals have executed away with recurrence and proposed the consideration mechanism, as included within the Transformer structure.[5] Consideration permits the mannequin to focus backwards and forwards between completely different phrases throughout prediction. Every phrase is weighted based on its relevance for the particular place to be predicted. For the above sentence, as soon as the mannequin reaches the place of her, lady may have a better weight than at, even if it’s a lot farther away within the linear order.
Up to now, the eye mechanism comes closest to the organic workings of the human mind throughout info processing. Research have proven that spotlight learns hierarchical syntactic constructions, incl. a spread of complicated syntactic phenomena (cf. the Primer on BERTology and the papers referenced therein). It additionally permits for parallel computation and, thus, sooner and extra environment friendly coaching.
Pre-training aims
With the suitable coaching knowledge illustration in place, our mannequin can begin studying. There are three generic aims used for pre-training language fashions: sequence-to-sequence transduction, autoregression and auto-encoding. All of them require the mannequin to grasp broad linguistic data.
The unique activity addressed by the encoder-decoder structure in addition to the Transformer mannequin is sequence-to-sequence transduction: a sequence is transduced right into a sequence in a special illustration framework. The classical sequence-to-sequence activity is machine translation, however different duties equivalent to summarisation are continuously formulated on this method. Word that the goal sequence is just not essentially textual content — it may also be different unstructured knowledge equivalent to photographs in addition to structured knowledge equivalent to programming languages. An instance of sequence-to-sequence LLMs is the BART household.
The second activity is autoregression, which can also be the unique language modelling goal. In autoregression, the mannequin learns to foretell the following output (token) primarily based on earlier tokens. The educational sign is restricted by the unidirectionality of the enterprise — the mannequin can solely use info from the precise or from the left of the expected token. This can be a main limitation since phrases can rely each on previous in addition to on future positions. For example, think about how the verb written impacts the next sentence in each instructions:

Right here, the place of paper is restricted to one thing that’s writable, whereas the place of scholar is restricted to a human or, anyway, one other clever entity able to writing.
Lots of the LLMs making right this moment’s headlines are autoregressive, incl. the GPT household, PaLM and BLOOM.
The third activity — auto-encoding — solves the problem of unidirectionality. Auto-encoding is similar to the training of classical phrase embeddings.[6] First, we corrupt the coaching knowledge by hiding a sure portion of tokens — sometimes 10–20% — within the enter. The mannequin then learns to reconstruct the right inputs primarily based on the encircling context, taking into consideration each the previous and the next tokens. The everyday instance of auto-encoders is the BERT household, the place BERT stands for Bidirectional Encoder Representations from Transformers.
Mannequin structure (encoder-decoder)
The essential constructing blocks of a language mannequin are the encoder and the decoder. The encoder transforms the unique enter right into a high-dimensional algebraic illustration, additionally known as a “hidden” vector. Wait a minute — hidden? Effectively, in actuality there aren’t any large secrets and techniques at this level. After all you’ll be able to take a look at this illustration, however a prolonged vector of numbers is not going to convey something significant to a human. It takes the mathematical intelligence of our mannequin to take care of it. The decoder reproduces the hidden illustration in an intelligible kind equivalent to one other language, programming code, a picture and so forth.
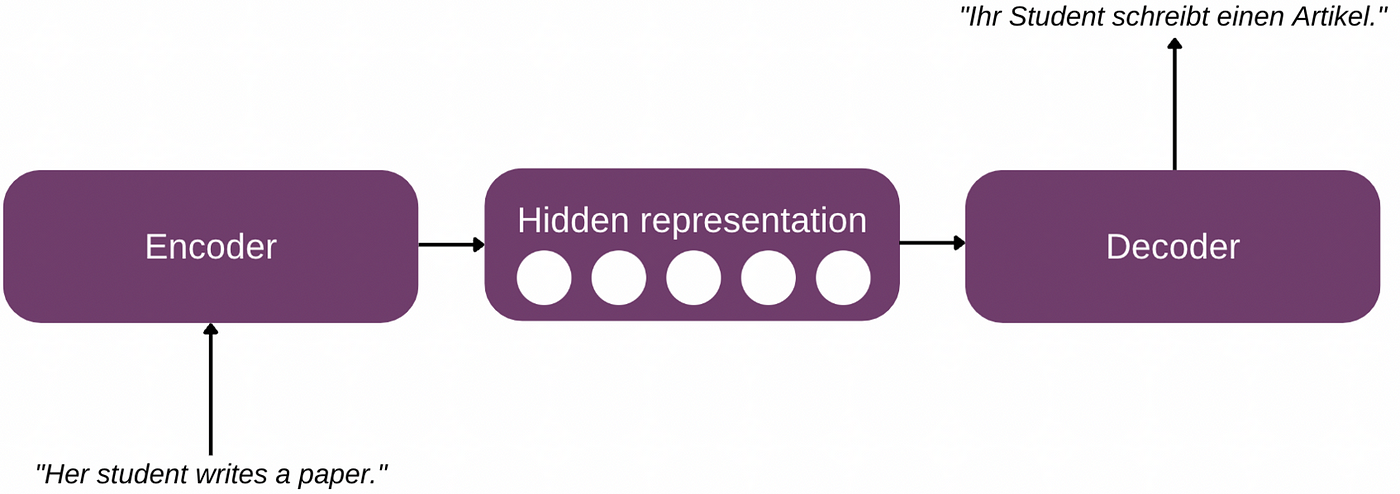
The encoder-decoder structure was initially launched for Recurrent Neural Networks. Because the introduction of the attention-based Transformer mannequin, conventional recurrence has misplaced its reputation whereas the encoder-decoder concept lives on. Most Pure Language Understanding (NLU) duties depend on the encoder, whereas Pure Language Technology (NLG) duties want the decoder and sequence-to-sequence transduction requires each parts.
We is not going to go into the main points of the Transformer structure and the eye mechanism right here. For many who wish to grasp the main points, be ready to spend an excellent period of time to wrap your head round it. Past the unique paper, [7] and [8] present wonderful explanations. For a light-weight introduction, I like to recommend the corresponding sections in Andrew Ng’s Sequence fashions course.
Superb-tuning
Language modelling is a strong upstream activity — when you’ve got a mannequin that efficiently generates language, congratulations — it’s an clever mannequin. Nonetheless, the enterprise worth of getting a mannequin effervescent with random textual content is proscribed. As a substitute, NLP is usually used for extra focused downstream duties equivalent to sentiment evaluation, query answering and data extraction. That is the time to use switch studying and reuse the prevailing linguistic data for extra particular challenges. Throughout fine-tuning, a portion of the mannequin is “freezed” and the remaining is additional educated with domain- or task-specific knowledge.
Express fine-tuning provides complexity on the trail in the direction of LLM deployment. It could additionally result in mannequin explosion, the place every enterprise activity requires its personal fine-tuned mannequin, escalating to an unmaintainable number of fashions. So, of us have made an effort to eliminate the fine-tuning step utilizing few- or zero-shot studying (e.g. in GPT-3 [9]). This studying occurs on-the-fly throughout prediction: the mannequin is fed with a “immediate” — a activity description and probably a number of coaching examples — to information its predictions for future examples.
Whereas a lot faster to implement, the comfort issue of zero- or few-shot studying is counterbalanced by its decrease prediction high quality. In addition to, many of those fashions have to be accessed by way of cloud APIs. This is perhaps a welcome alternative initially of your growth — nevertheless, at extra superior phases, it might flip into one other undesirable exterior dependency.
Selecting the correct mannequin to your downstream activity
Trying on the steady provide of latest language fashions on the AI market, choosing the precise mannequin for a particular downstream activity and staying in synch with the state-of-the-art could be difficult.
Analysis papers usually benchmark every mannequin towards particular downstream duties and datasets. Standardised activity suites equivalent to SuperGLUE and BIG-bench permit for unified benchmarking towards a mess of NLP duties and supply a foundation for comparability. Nonetheless, we must always remember that these checks are ready in a extremely managed setting. As of right this moment, the generalisation capability of language fashions is fairly restricted — thus, the switch to real-life datasets would possibly considerably have an effect on mannequin efficiency. The analysis and choice of an applicable mannequin ought to contain experimentation on knowledge that’s as shut as potential to the manufacturing knowledge.
As a rule of thumb, the pre-training goal offers an essential trace: autoregressive fashions carry out effectively on textual content era duties equivalent to conversational AI, query answering and textual content summarisation, whereas auto-encoders excel at “understanding” and structuring language, for instance for sentiment evaluation and numerous info extraction duties. Fashions supposed for zero-shot studying can theoretically carry out all types of duties so long as they obtain applicable prompts — nevertheless, their accuracy is usually decrease than that of fine-tuned fashions.
To make issues extra concrete, the next chart reveals how fashionable NLP duties are related to outstanding language fashions within the NLP literature. The associations are computed primarily based on a number of similarity and aggregation metrics, incl. embedding similarity and distance-weighted co-occurrence. Mannequin-task pairs with increased scores, equivalent to BART / Textual content Summarization and LaMDA / Conversational AI, point out an excellent match primarily based on historic knowledge.

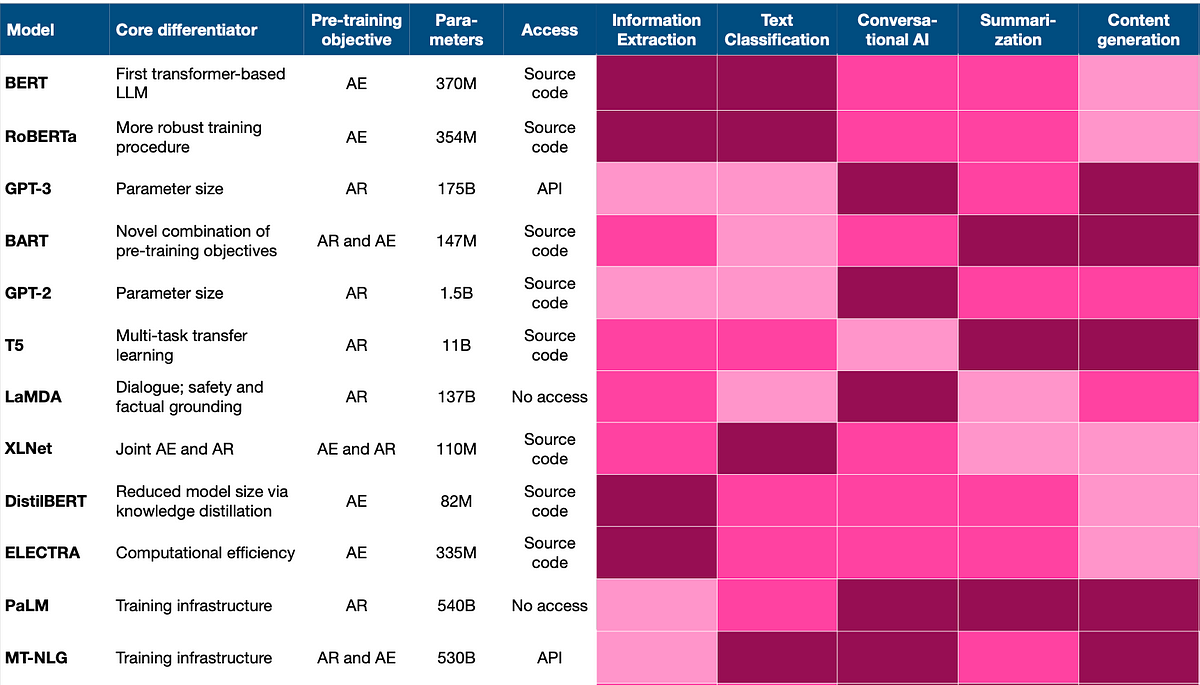
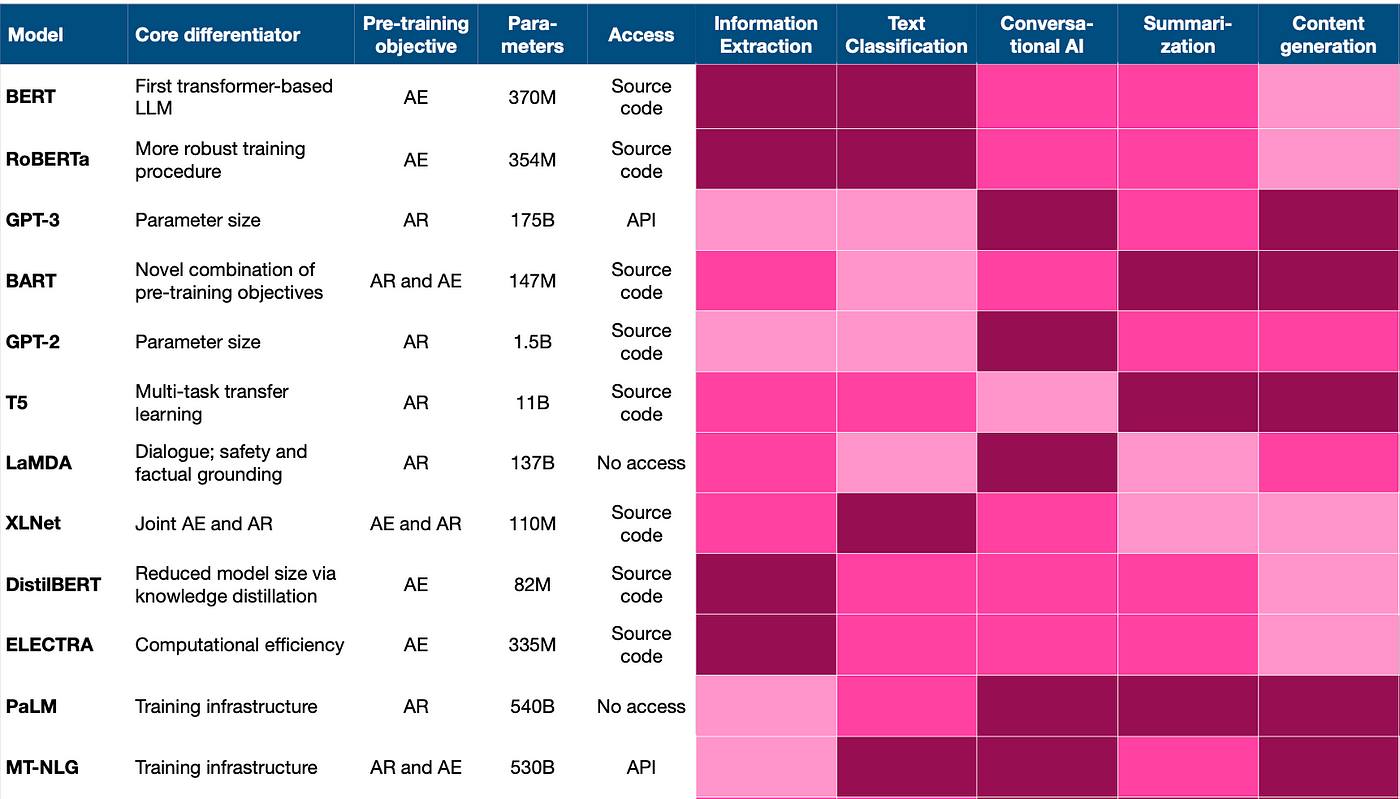
On this article, we’ve lined the fundamental notions of LLMs and the primary dimensions the place innovation is going on. The next desk offers a abstract of the important thing options for the most well-liked LLMs:

Let’s summarise some normal tips for the choice and deployment of LLMs:
1. When evaluating potential fashions, be clear about the place you’re in your AI journey:
- At first, it is perhaps a good suggestion to experiment with LLMs deployed by way of cloud APIs.
- Upon getting discovered product-market match, think about internet hosting and sustaining your mannequin in your facet to have extra management and additional sharpen mannequin efficiency to your software.
2. To align along with your downstream activity, your AI group ought to create a short-list of fashions primarily based on the next standards:
- Benchmarking ends in the tutorial literature, with a spotlight in your downstream activity
- Alignment between the pre-training goal and downstream activity: think about auto-encoding for NLU and autoregression for NLG
- Earlier expertise reported for this model-task mixture (cf. Determine 5)
4. The short-listed fashions must be then examined towards your real-world activity and dataset to get a primary feeling for the efficiency.
5. Normally, you’re prone to obtain a greater high quality with devoted fine-tuning. Nonetheless, think about few-/zero-shot-learning if you happen to don’t have the inner tech expertise or finances for fine-tuning, or if you have to cowl a lot of duties.
6. LLM improvements and tendencies are short-lived. When utilizing language fashions, keep watch over their lifecycle and the general exercise within the LLM panorama and be careful for alternatives to step up your sport.
Lastly, pay attention to the constraints of LLMs. Whereas they’ve the superb, human-like capability to provide language, their total cognitive energy is galaxies away from us people. The world data and reasoning capability of those fashions are strictly restricted to the knowledge they discover on the floor of language. Additionally they can’t situate info in time and would possibly give you outdated info with out blinking a watch. In case you are constructing an software that depends on producing up-to-date and even unique data, think about combining your LLM with extra multimodal, structured or dynamic data sources.
[1] Victor Sanh et al. 2021. Multitask prompted coaching allows zero-shot activity generalization. CoRR, abs/2110.08207.
[2] Yoshua Bengio et al. 1994. Studying long-term dependencies with gradient descent is troublesome. IEEE Transactions on Neural Networks, 5(2):157–166.
[3] Sepp Hochreiter and Jürgen Schmidhuber. 1997. Lengthy short-term reminiscence. Neural Computation, 9(8): 1735–1780.
[4] Kyunghyun Cho et al. 2014. On the properties of neural machine translation: Encoder–decoder approaches. In Proceedings of SSST-8, Eighth Workshop on Syntax, Semantics and Construction in Statistical Translation, pages 103–111, Doha, Qatar.
[5] Ashish Vaswani et al. 2017. Consideration is all you want. In Advances in Neural Data Processing Techniques, quantity 30. Curran Associates, Inc.
[6] Tomas Mikolov et al. 2013. Distributed representations of phrases and phrases and their compositionality. CoRR, abs/1310.4546.
[7] Jay Jalammar. 2018. The illustrated transformer.
[8] Alexander Rush et al. 2018. The annotated transformer.
[9] Tom B. Brown et al. 2020. Language fashions are few-shot learners. In Proceedings of the thirty fourth Worldwide Convention on Neural Data Processing Techniques, NIPS’20, Purple Hook, NY, USA. Curran Associates Inc.
[10] Jacob Devlin et al. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Convention of the North American Chapter of the Affiliation for Computational Linguistics: Human Language Applied sciences, Quantity 1 (Lengthy and Quick Papers), pages 4171–4186, Minneapolis, Minnesota.
[11] Julien Simon 2021. Massive Language Fashions: A New Moore’s Regulation?
[12] Underlying dataset: greater than 320k articles on AI and NLP revealed 2018–2022 in specialised AI sources, expertise blogs and publications by the main AI suppose tanks.
All photographs except in any other case famous are by the creator.

{kind=link}