
How successful tickets had been found, debunked, and re-discovered
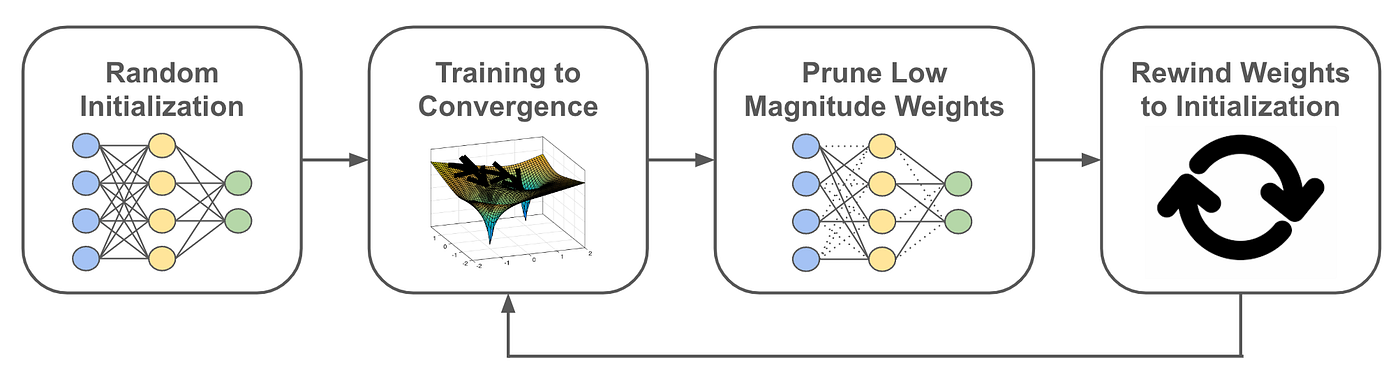
The Lottery Ticket Speculation (LTH) is expounded to neural community pruning and will be concisely summarized by way of the next assertion [1]:
“dense, randomly-initialized, feed-forward networks include subnetworks (successful tickets) that — when skilled in isolation — attain take a look at accuracy corresponding to the unique community in the same variety of iterations.”
Although a bit troublesome to interpret, such an announcement reveals that if we:
- Practice a neural community to convergence
- Prune its weights, yielding a smaller subnetwork
- Rewind subnetwork weights to their unique, randomly-initialized values
- Practice the ensuing subnetwork to convergence
Then, the subnetwork — sometimes known as a “successful ticket” — will obtain testing accuracy that matches or exceeds the efficiency of the unique, dense neural community from which the subnetwork was derived.
Such an statement was intriguing to the deep studying neighborhood, because it means random subnetworks exist inside dense networks that (i) are smaller/extra computationally environment friendly and (ii) will be independently skilled to carry out effectively. If these successful tickets will be recognized simply, neural community coaching price will be drastically lowered by merely coaching the subnetwork as a substitute of the complete, dense mannequin.
The purpose of lowering coaching complexity by way of LTH-inspired findings has not but been realized because of the truth that discovering successful tickets requires full (or partial [2]) pre-training of the dense community, which is a computationally burdensome course of. However, the deep studying neighborhood continues to check the LTH due to its potential to tell and simplify neural community coaching.
Previous to diving into the primary subject, I’m going to supply related background info wanted to know the LTH. I purpose to construct a ground-up understanding of the subject by offering a complete abstract of related context. In some circumstances, nonetheless, offering a full overview of a subject shouldn’t be sensible or inside scope, so I as a substitute present hyperlinks to exterior sources that can be utilized to understand an thought extra deeply.
What’s neural community pruning?
So as to absolutely perceive the LTH, one should be conversant in neural community pruning [3, 4, 5], upon which the LTH is predicated. The fundamental thought behind pruning is to take away parameters from a big, dense community, yielding a (presumably sparse) subnetwork that’s smaller and extra computationally environment friendly. Although I cite among the most helpful papers on neural community pruning right here, quite a few high-quality sources exist on-line which are useful to discover.
Ideally, the pruned subnetwork ought to carry out equally to the dense community, although this will not be the case if a lot of parameters are eliminated. Thus, the purpose of the pruning course of is to seek out and take away parameters that don’t considerably impair the community’s efficiency.
Generally, neural community pruning follows the three-step technique of pre-training, pruning, and fine-tuning. The dense community is first pre-trained, both partially or to convergence. Then, pruning is carried out on this dense community, and the ensuing subnetwork is additional skilled/fine-tuned after pruning happens.
Completely different Forms of Pruning
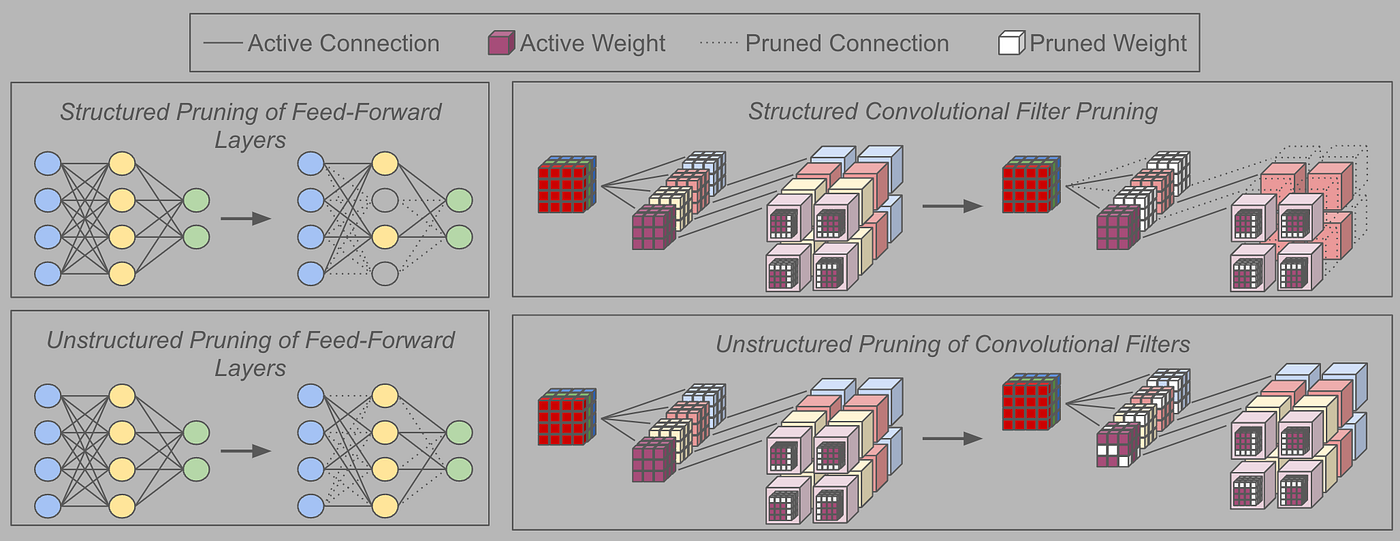
Many methods for neural community pruning exist, however they are often roughly categorized into two teams — structured and unstructured pruning.
Unstructured pruning locations no constraints on the pruning course of. Any and all weights inside the community will be individually pruned/eliminated, which means that the ensuing community is oftentimes sparse after pruning is carried out.
In distinction, structured pruning removes whole “teams” of weights (e.g., convolutional filters, neurons in feed-forward layers, consideration heads in transformers, and many others.) collectively from the underlying community to keep away from sparsity within the ensuing subnetwork. Consequently, the subnetwork is only a smaller, dense mannequin.
Each structured and unstructured pruning methodologies (depicted within the determine above) are broadly used — neither one is essentially “higher”. Unstructured pruning permits greater sparsity ranges to be reached with out efficiency degradation as a result of it locations fewer constraints on the pruning course of. Nonetheless, structured pruning has the additional benefit of manufacturing dense subnetworks, thus permitting using specialised libraries for sparse matrix multiplication — which usually make community coaching/inference a lot slower — to be prevented.
Iterative Magnitude Pruning (IMP)
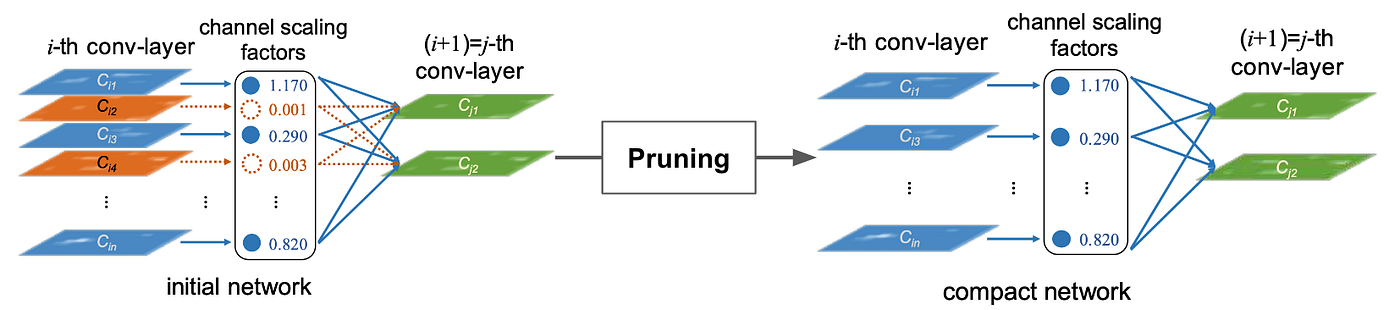
The kind of neural community pruning that’s most commonly-used for finding out the LTH is iterative magnitude pruning (IMP) [4], which operates as follows:
- Start with a fully-trained, dense mannequin
- Choose and prune the bottom magnitude weights within the community
- High-quality-tune/practice the ensuing subnetwork to convergence
- Repeat steps (2)-(3) till the specified pruning ratio is achieved
Though the thought behind IMP is seemingly easy, this method works extremely effectively in observe and has confirmed itself a troublesome baseline to beat [4, 5]. As a result of IMP works so effectively, quite a few useful explanations are out there on-line.
IMP is usually modified when utilized to structured pruning or used on extra advanced community variants. For instance, one variant of IMP for structured filter pruning in convolutional neural networks assigns separate scaling elements to every channel inside the community, then prunes filters primarily based on the magnitude of those elements as a substitute of the weights themselves [8]. See the picture above for a schematic depiction.
Right here, I’ll overview three essential papers related to the LTH. The primary work I contemplate proposes the LTH, whereas the others additional analyze the thought and supply helpful perception. Curiously, the LTH was partially debunked shortly following its proposal, then later confirmed (with modifications) in a followup paper by the unique authors. Competition across the subject led to a whole lot of confusion inside the analysis neighborhood, and I’ll strive my finest to clear up that confusion right here.
The Lottery Ticket Speculation: Discovering Sparse, Trainable Neural Networks [1]
Major Thought. Fashions will be simply pruned to <10% of complete parameters. However, if we:
- Took the construction/structure of a pruned community
- Randomly re-initialized its parameters
- Educated the community from scratch
The subnetwork would carry out poorly. This paper finds that particular subnetworks — known as “successful tickets” — exist inside a randomly-initialized, dense community that, when skilled in isolation, can match the efficiency of the fully-trained dense community. Such a phenomenon was coined because the Lottery Ticket Speculation (LTH), as defined within the preliminary paragraph of this overview.
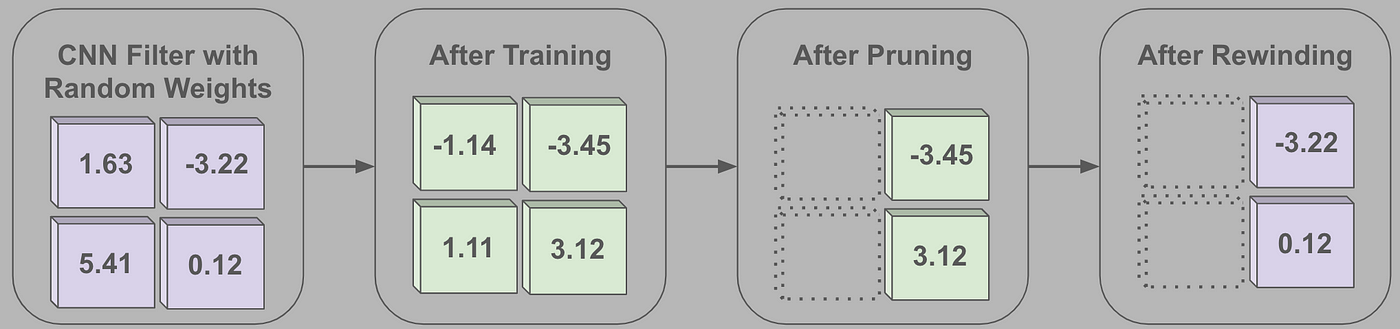
Methodology. To confirm the LTH, authors undertake an unstructured pruning method. The pruning approach used is sort of much like IMP with one minor distinction. Particularly, to provide successful tickets, the authors proceed as follows:
- Start with a fully-trained, dense mannequin
- Choose and prune the bottom magnitude weights within the community
- Rewind remaining subnetwork parameters to their preliminary, random values
- Practice the subnetwork to convergence
- Repeat steps (2)-(4) till the specified pruning ratio is achieved
The primary distinction between the methodology above and IMP is the rewinding of mannequin parameters. As a substitute of merely fine-tuning present mannequin parameters after pruning, parameters are reset to their unique, random values.
On this manner, the successful ticket — each its construction and its weights — exists inside the randomly-initialized dense community. Thus, this subnetwork is proven to have received the “initialization lottery”, as it may be skilled from scratch to greater accuracy than that of a fully-trained dense community or randomly re-initialized subnetwork with the identical construction.
Findings.
- The LTH is empirically validated utilizing fully-connected networks and small-scale CNNs on MNIST and CIFAR10 datasets. Successful tickets which are 10–20% of the unique community dimension are discovered to persistently exist.
- Successful tickets are proven to have higher generalization properties than the unique dense community in lots of circumstances.
- Randomly re-initializing successful tickets previous to coaching is damaging to efficiency. Rewinding parameters to their preliminary, random values is crucial to matching or exceeding dense community efficiency.
Rethinking the Worth of Community Pruning [5]
Major Thought. Put merely, this paper exhibits that subnetworks which are randomly re-initialized and skilled from scratch carry out equally to subnetworks obtained by way of IMP. Such a outcome contradicts earlier findings within the neural community pruning literature [1, 4], revealing that coaching giant, overparameterized fashions shouldn’t be really essential to acquiring a extra environment friendly subnetwork.
Though this result’s extra related to normal neural community pruning (i.e., not the LTH specifically), the outcomes on this paper display that:
- Rewinding subnetwork parameters to their preliminary values shouldn’t be a crucial element of the LTH methodology — the identical outcomes will be obtained by randomly re-initializing subnetwork parameters throughout iterative pruning.
- The LTH is a phenomenon that can’t be replicated in large-scale experiments with structured pruning and sophisticated community architectures.
Methodology. In contrast to the unique LTH publication, the authors inside this work utilized structured pruning approaches within the majority of their experiments. Although unstructured pruning is adopted in some circumstances, structured pruning is extra generally utilized in larger-scale experiments (e.g., structured filter pruning with convolutional networks [4]), making such an method extra applicable.
A big number of community pruning approaches are explored (see Part 4 headers and descriptions in [5]) that carry out:
- Pre-defined construction pruning: prune every layer a hard and fast, uniform quantity
- Automated construction pruning: dynamically resolve how a lot every layer ought to be pruned as a substitute of pruning layers uniformly
- Unstructured IMP: see the earlier dialogue on IMP for an outline
For every of those approaches, the authors comply with the previously-described three-step pruning course of. For the third step, ensuing subnetworks are skilled starting with numerous totally different parameter initializations:
- Rewinding subnetwork parameters to their preliminary, random values
- Retaining/fine-tuning present subnetwork parameters
- Randomly re-initializing subnetwork parameters
The authors discover that randomly re-initializing subnetwork parameters after pruning matches or exceeds the efficiency of different approaches in a majority of circumstances. Thus, for such large-scale experiments, the LTH couldn’t be validated.
Findings.
- A random re-initialization of subnetwork parameters is enough to attain aggressive subnetwork efficiency, revealing that the LTH doesn’t maintain within the larger-scale experiments explored on this work.
- The disparity in findings between the LTH and this paper could also be attributable to (i) principally utilizing structured pruning for evaluation, (ii) utilizing bigger fashions and datasets, or (iii) distinction in optimization and hyperparameter settings.
- The parameters of successful tickets or high-performing subnetworks obtained from neural community pruning aren’t important, revealing that neural community pruning could also be not more than an alternate type of Neural Structure Search.
Linear Mode Connectivity and the Lottery Ticket Speculation [6]
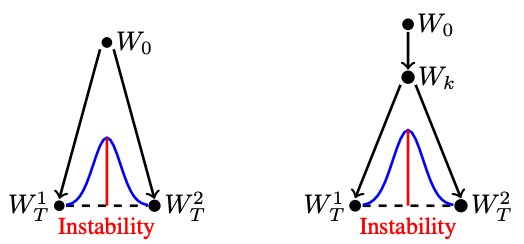
Major Thought. This work explores the issue outlined within the paper above — why does the LTH not maintain in large-scale experiments? The authors discover that successful tickets can’t be found in large-scale experiments utilizing the methodology proposed in [1]. Particularly, such subnetworks don’t obtain accuracy that matches or exceeds that of the dense community.
Curiously, nonetheless, if one modifies this process to rewind weights to some early coaching iteration ok — somewhat than strictly to initialization — the ensuing subnetwork performs effectively. Thus, the LTH nonetheless holds in large-scale experiments if the methodology is barely modified as follows:
- Start with a fully-trained, dense mannequin
- Choose and prune the bottom magnitude weights within the community
- Rewind subnetwork parameters to values at coaching iteration ok
- Practice the subnetwork to convergence
- Repeat steps (2)-(4) till the specified pruning ratio is achieved
As a result of such subnetworks aren’t found inside the randomly-initialized, dense community, the authors confer with them as “matching” subnetworks as a substitute of successful tickets.
Methodology. To find this attention-grabbing weight rewinding property inside the LTH, the authors undertake a novel type of instability evaluation primarily based upon linear mode connectivity. Their methodology of research performs the next steps:
- Create two copies of a community.
- Practice these networks independently with totally different random seeds, such that the networks expertise totally different random noise and knowledge ordering throughout coaching with stochastic gradient descent.
- Decide if the 2 ensuing networks are linearly linked by a area of non-increasing error.
In observe, the ultimate step within the methodology above is carried out by simply testing a hard and fast variety of linearly-interpolated factors between the weights of the 2 networks. At every of those factors, the error of the interpolated community is examined to make sure it doesn’t exceed the common error values of the particular networks.
By performing instability evaluation as described above, the authors uncover that networks develop into secure early in coaching, however not at initialization. Moreover, matching subnetworks are all the time secure, revealing that matching subnetworks can’t be derived from randomly-initialized, unstable parameters. Such an statement explains why the LTH solely holds when weights are rewound to some early coaching iteration and never all the way in which to initialization.
Findings.
- The LTH doesn’t maintain at scale. However, “matching” subnetworks will be found by modifying the LTH to rewind weights to some early iteration of coaching, as a substitute of all the way in which to initialization.
- Solely very small-scale networks and datasets (e.g., LeNet on MNIST) are secure at initialization, which explains why the unique LTH formulation [1] might solely be verified on such small-scale datasets.
- Given such modifications to the LTH, matching subnetworks will be discovered persistently even in large-scale experiments with state-of-the-art convolutional neural community architectures on ImageNet.
By finding out the LTH, we have now realized about a number of helpful ideas:
- Neural Community Pruning: generates a smaller, environment friendly community from a fully-trained dense community by eradicating unneeded weights
- Structured vs. Unstructured Pruning: two classes of pruning methodologies that place totally different constraints on the pruning course of
- Iterative Magnitude Pruning: a easy, but efficient, pruning methodology that iteratively discards lowest-magnitude weights within the community
- Linear Mode Connectivity: a property used to explain a community that’s “secure” to the noise from coaching with stochastic gradient descent.
Within the work that was overviewed, we first realized that — in small-scale experiments — dense, randomly-initialized neural networks include subnetworks (i.e., successful tickets) that may be found with IMP and skilled in isolation to attain excessive accuracy [1].
This discovering was later contradicted by analysis displaying that, in large-scale experiments, such successful tickets will be randomly re-initialized and nonetheless obtain comparable accuracy, revealing that there’s nothing particular about these successful tickets aside from the community construction found by IMP [5].
Such contradictory outcomes had been settled when it was proven that though successful tickets might not exist in randomly-initialized dense networks, matching subnetworks (i.e., subnetworks that match or exceed dense community efficiency) will be discovered by way of IMP in networks which have been skilled a small quantity [6]. Thus, the LTH remains to be legitimate at scale given some slight modifications.
Conclusion
Thanks a lot for studying this text. In case you appreciated it, please subscribe to my Deep (Studying) Focus publication, the place I contextualize, clarify, and look at a single, related subject in deep studying analysis each two weeks. Be happy to comply with me on medium or go to my web site, which has hyperlinks to my social media and different content material. If in case you have any suggestions/suggestions, contact me immediately or depart a remark.
Bibliography
[1] Frankle, Jonathan, and Michael Carbin. “The lottery ticket speculation: Discovering sparse, trainable neural networks.” arXiv preprint arXiv:1803.03635 (2018).
[2] You, Haoran, et al. “Drawing early-bird tickets: In the direction of extra environment friendly coaching of deep networks.” arXiv preprint arXiv:1909.11957 (2019).
[3] LeCun, Yann, John Denker, and Sara Solla. “Optimum mind harm.” Advances in neural info processing programs 2 (1989).
[4] Li, Hao, et al. “Pruning filters for environment friendly convnets.” arXiv preprint arXiv:1608.08710 (2016).
[5] Liu, Zhuang, et al. “Rethinking the worth of community pruning.” arXiv preprint arXiv:1810.05270 (2018).
[6] Frankle, Jonathan, et al. “Linear mode connectivity and the lottery ticket speculation.” Worldwide Convention on Machine Studying. PMLR, 2020.
[7] You, Haoran, et al. “Drawing early-bird tickets: In the direction of extra environment friendly coaching of deep networks.” arXiv preprint arXiv:1909.11957 (2019).
[8] Liu, Zhuang, et al. “Studying environment friendly convolutional networks via community slimming.” Proceedings of the IEEE worldwide convention on laptop imaginative and prescient. 2017.

{kind=link}