A sensible information with examples
Within the earlier submit associated to knowledge cleansing and have engineering, we went by means of a few operation (apply, map, and many others.) examples and their simulated runtimes.
On this article, I’ll share different examples which have helped in my work, and hopefully, might assist yours too. We’ll be going by means of examples of…
- Pandas show settings
- Purposeful patterns
- Compiling common expressions
- Dictionary comprehension
- defaultdict
…utilizing the identical iaito dataset. These examples are under no circumstances complete, however they need to assist get you began exploring their purposes.
A brief recap in regards to the dataset; the dataset was began again in 2012 whereas serving to fellow iaidoka members with the interpretation of iaito order particulars. Every report accommodates the iaito half specs per proprietor. For privateness, delicate data such because the proprietor’s full identify and tackle are by no means captured within the dataset. The dataset will be accessed from my GitHub repo.
Pandas show settings
Pandas has an in depth record of choices. The extra widespread ones that we most likely encounter and use ought to be max_rows or max_columns. When studying a doubtlessly lengthy desk, some columns could be truncated as ‘…’. To mitigate that, we will set it such that every one columns are displayed (i.e. pd.set_option('show.max_columns', None)).
import pandas as pd
pd.set_option('show.max_columns', None)df = pd.read_excel('project_nanato2022_Part1.xlsx',)
To evaluation the primary or final n rows of the info body, utilizinghead or tail involves thoughts.
show(df.head()) # check out first default = 5 rows
df.tail() # check out final 5 rows
Don’t get me improper, I’m all for utilizing head() and tail(), and I nonetheless use them as a go-to technique to test if derived knowledge body copies are right. However with the setting above, we have compacted the info body show to indicate each first and final ‘n’ rows – reaching the identical consequence with lesser code.
pd.set_option('show.max_rows', 10) # set show to 10 rowsdf = pd.read_excel('project_nanato2022_Part1.xlsx')
df
One other facet value contemplating whereas coping with a number of recordsdata is the processes concerned in analyzing these recordsdata, and the potential file sizes. If the info is clear, however we’ll wish to get higher sensing of the info traits, then limiting the variety of rows (i.e. information) is healthier for managing giant file sizes.
# restrict to five rows
df_limited = pd.read_excel('project_nanato2022_Part1.xlsx',nrows=5)
df_limited
- One other minor facet simply as simply neglected is the repeated calling of capabilities for comfort. I do know — I have a tendency to make use of this liberally. One instance is
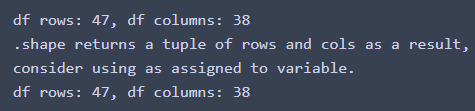
df.form. Step one to shifting away from that is remembering the traits of the output (tuple of row and column depend on this case). We might name it as soon as and entry the outcomes after assigning them to a variable.
print(f'df rows: {df.form[0]}, df columns: {df.form[1]}')
print('.form returns a tuple of rows and cols consequently, nconsider utilizing as assigned to a variable.')
res_shape = df.form
print(f'df rows: {res_shape[0]}, df columns: {res_shape[1]}')
Purposeful Sample
Arranging code in a purposeful sample enhances the flexibleness and ease with which how we might modify code for knowledge cleansing or transformation downstream. Given the typically ambiguous nature concerned in knowledge cleansing, I don’t at all times do it initially, however attempt to implement them when refactoring to reinforce reusability. We’ll use the cleansing of column names for example.
# preliminary column names
ini_cols = df.columns
ini_cols

Relating to these column headers, we’ll wish to
- take away commas (i.e. punctuation(s))
- exchange whitespaces with underscores
- lowercase them
Let’s check out the implementation within the earlier article. The variety of rows displayed is adjusted to 1 for brevity. Renaming isn’t accomplished in place for this instance.
pd.set_option('show.max_rows', 1) # 1 row for simpler studying
# lowercase, drop commas, exchange newline & areas with underscores
col_names = []
for outdated in df.columns:
new = re.sub( r"[,]" ,'',outdated.strip())
new = re.sub( r"[ns/]" ,'_',new)
col_names.append(new.decrease())
df.rename(columns=dict(zip(df.columns, col_names)), )

- Now, let’s break it up into a number of methods we’d improve it. Firstly, we might derive reusable regex objects utilizing
compile. Here is an instance of compiling the common expression, adopted by the handbook calling of the substitution of the sample.
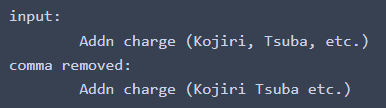
comma_ = re.compile( r"[,]" ) # compile the common expressiontest_string_ = ini_cols[29]
print(f'enter:nt{test_string_}')res_string_ = comma_.sub('', test_string_.strip())
print(f'comma eliminated:nt{res_string_}')
We might then implement this by making the sequence of operations to be utilized as an iterable. We’d…
- Compile all of the common expressions;
- Create a listing of the operations;
- Lastly, apply as a perform
# compile common expressions
comma_ = re.compile( r"[,]" )
whitespaces_ = re.compile( r"[ns/]" )# capabilities
def remove_comma(val):
return comma_.sub('', val)def replace_whitespaces(val):
return whitespaces_.sub('_', val)def clean_headers(headers, op_seq):
cleaned_cols = []
for val in headers:
for op in op_seq:
val = op(val)
cleaned_cols.append(val)
return cleaned_cols# sequence of operations as a listing
op_seq = [str.strip, remove_comma, replace_whitespaces, str.lower]
# implement on df column headers
res = clean_headers(df.columns, op_seq)
df.rename(columns=dict(zip(df.columns, res)), inplace=True)
df

Dictionary Comprehension
Just like a listing comprehension, the syntax seems like this:

with if-else situations, it might be:

We’ll get a subset of the info. Say we wish to create a column with salutation inferred from the proprietor’s gender (i.e. add ‘Mr.’ if gender is ‘M’, ‘Ms.’ if gender is ‘F’, use 5 rows of knowledge for brevity).
pd.set_option('show.max_rows', 10) # set show to 10 rows
df_subset = df.iloc[:5][['owner', 'gender']].copy()
One implementation could be:
identify = {}
for i in vary(len(df_subset)):
if df_subset['gender'][i] == 'M':
identify[i] = 'Mr. ' + df_subset['owner'][i]
else:
identify[i] = 'Ms. ' + df_subset['owner'][i]df_dict = pd.DataFrame.from_dict(identify, orient='index',columns=['name'])
df_dict

With dictionary comprehension:
name2 = {i:'Mr. ' + df_subset['owner'][i]
if df_subset['gender'][i] == 'M'
else 'Ms. ' + df_subset['owner'][i]
for i in vary(len(df_subset))
}df_dict2 = pd.DataFrame.from_dict(name2, orient='index',columns=['name2'])
df_dict2
Defaultdict
Setting values in a dictionary generally entails referencing them from one other assortment. The logic typical entails setting a key-value pair if the worth isn’t within the dictionary, or including to the worth sequence if the secret is already current. The default worth is taken into account as setting a key-value pair if the worth isn’t within the dictionary for this occasion. Getting default values within the dictionary will be facilitated through the use of defaultdict from collections. A hypothetical use case might be answering: “Generate the record of tsuba selections per mannequin.”
# prep the info to work with
tsuba_codes = df['tsuba'].apply(lambda x: x.cut up(' ')[0])
model_series = df['model']print(tsuba_codes.distinctive())
print(model_series.distinctive())

Utilizing for loops:
model_tsuba = {}
for mannequin, code in record(zip(model_list, tsuba_codes)):
if mannequin not in model_tsuba:
model_tsuba[ model ] = [code]
if code not in model_tsuba[model]: # avoids duplicate tsuba code
model_tsuba[ model ].append(code)for okay, v in model_tsuba.objects():
v.type()
print(f'{okay}: {", ".be a part of(ele for ele in v)}')

from collections import defaultdictmodel_tsuba2 = defaultdict(record)
for mannequin, code in record(zip(model_list, tsuba_codes)):
model_tsuba2[model] = record(set(model_tsuba2[model] + [code]))for okay, v in model_tsuba2.objects():
v.type()
print(f"{okay}: {', '.be a part of(ele for ele in v)}")

