
On a recent trip to my hometown in Eastern Canada, my father picked me up at the airport. One of the first things he asked me was, “Is AI going to take everyone’s jobs?”.
When AI, generative AI, and large language models (LLM) have become topics of conversation within the senior citizen community of rural Canada, you know it’s on everyone’s minds. Generative AI, and especially the use of LLMs, is the “new new thing”. It dominates my X (i.e. Twitter) feed and nearly every conversation I have about technology.
There’s justifiably a ton of excitement about the power of generative AI, reminiscent of the introduction of the Internet or the first smartphone. Generative AI is poised to transform how we build products, design drugs, write content, and interact with technology. But as the utilization of AI grows, many governments and companies have raised concerns about the privacy and compliance issues that adopters of these technologies face.
The core challenge posed by generative AI right now is that unlike conventional applications, LLMs have no “delete” button. There’s no straightforward mechanism to “unlearn” specific information, no equivalent to deleting a row in your database’s user table. In a world where the “right to be forgotten” is central to many privacy regulations, using LLMs presents some difficult challenges.
So what does all this mean for businesses that are building new AI-powered applications or AI models?
In this post, we’ll explore this question and attempt to provide answers. We’ll examine the potential impact of generative AI, ongoing compliance hurdles, and a variety of privacy strategies. Finally, we’ll examine a novel approach grounded in the IEEE’s recommended architecture for securely storing, managing, and utilizing sensitive customer PII (Personally Identifiable Information)—the data privacy vault.
Generative AI’s privacy and compliance challenges
Think about the next situation: You’ve got simply copied and pasted delicate contract particulars into an LLM to get some fast help with routine contract due diligence. The LLM serves its function, however here is the catch: relying on the way it’s configured, that confidential contract knowledge may linger throughout the LLM, accessible to different customers. Deleting it is not an possibility, predicting its future use—or misuse—turns into a frightening job, and retraining the LLM to “roll it again” to its state earlier than you shared these delicate contract particulars may be prohibitively costly.
The one foolproof answer?
Maintain delicate knowledge distant from LLMs.
Delicate data, together with inner firm venture names, core mental property, or private knowledge like birthdates, social safety numbers, and healthcare data, can inadvertently discover its approach into LLMs in a number of methods:
- Coaching knowledge: LLMs are educated and honed on expansive datasets that always include PII. With out strong anonymization or redaction measures in place, delicate knowledge turns into a part of the mannequin’s coaching dataset, that means that this knowledge can probably resurface later.
- Inference: LLMs generate textual content primarily based on consumer inputs or prompts. Very like coaching knowledge, a immediate containing delicate knowledge seeps into the mannequin and might affect the generated content material, probably exposing this knowledge.
Privacy laws
AI knowledge privateness is a formidable problem for any firm considering investing in generative AI expertise. Current momentary bans of ChatGPT in Italy and by corporations like Samsung have pushed these issues to the forefront for companies seeking to put money into generative AI.
Even outdoors of generative AI, there are rising issues about defending knowledge privateness. Meta was lately fined $1.3 billion by the European Union (EU) for its non-compliant transfers of delicate knowledge to the U.S. And this isn’t simply a difficulty for corporations doing enterprise within the EU.
There are actually greater than 100 international locations with some type of privateness regulation in place. Every nation’s privateness rules embrace distinctive and nuanced necessities that place quite a lot of restrictions on the use and dealing with of delicate knowledge. The commonest restrictions relate to cross-border knowledge transfers, the place delicate knowledge may be saved, and to particular person knowledge topic rights such because the “proper to be forgotten.”
One of many largest shortcomings of LLMs is their incapability to selectively delete or “unlearn” particular knowledge factors, akin to a person’s title or date of beginning. This limitation presents important dangers for companies leveraging these techniques.
For instance, privateness rules in Europe, Argentina, and the Philippines (simply to call just a few) all assist a person’s “proper to be forgotten.” This grants people the proper to have their private data eliminated or erased from a system. With out an LLM delete button, there’s no approach for a enterprise to handle such a request with out retraining their LLM from scratch.
Think about the European Union’s Basic Knowledge Safety Regulation (GDPR), which grants people the proper to entry, rectify, and erase their private knowledge—a job that turns into daunting if that knowledge is embedded inside an LLM. GDPR additionally empowers people with the proper to object to automated decision-making, additional complicating compliance for corporations that use LLMs.
Knowledge localization necessities pose one other problem for customers of LLMs. These necessities pertain to the bodily location the place buyer knowledge is saved. Totally different international locations and areas have exact legal guidelines dictating how buyer knowledge needs to be dealt with, processed, saved, and safeguarded. This poses a big problem when utilizing an LLM used for a corporation’s international buyer base.
Knowledge Topic Entry Requests (DSARs) underneath GDPR and different legal guidelines add one other layer of complexity. Within the EU and California, people (i.e., “knowledge topics”) have the proper to request entry to their private knowledge, however complying with such requests proves difficult if that knowledge has been processed by LLMs.
Contemplating the intricate privateness and compliance panorama and the complexity of LLMs, probably the most sensible method to sustaining compliance is to stop delicate knowledge from getting into the mannequin altogether. By implementing stringent knowledge dealing with practices, companies can mitigate the privateness dangers related to LLMs, whereas additionally sustaining the utility of the mannequin. Many corporations have already determined that the dangers are too excessive, in order that they’ve banned using ChatGPT, however this method is shortsighted. Correctly managed, these fashions can create lots of worth.
Privacy approaches for generative AI
To deal with the privateness challenges related to generative AI fashions, there have been just a few proposals akin to banning or controlling entry, utilizing artificial knowledge as an alternative of actual knowledge, and operating non-public LLMs.
Banning ChatGPT and different generative AI techniques isn’t an efficient long-term technique, and these different “band help” approaches are sure to fail as individuals can discover straightforward workarounds. Utilizing artificial knowledge replaces delicate data with similar-looking however non-sensitive knowledge and retains PII out of the mannequin, however at the price of shedding the worth that motivated you to share delicate knowledge with the LLM within the first place. The mannequin loses context, and there’s no referential integrity between the synthetically generated knowledge and the unique delicate data.
The preferred method to addressing AI knowledge privateness, and the one which’s being promoted by cloud suppliers like Google, Microsoft, AWS, and Snowflake, is to run your LLM privately on their infrastructure.
For instance, with Snowflake’s Snowpark Mannequin Registry, you’ll be able to take an open supply LLM and run it inside a container service in your Snowflake account. They state that this lets you practice the LLM utilizing your proprietary knowledge.

Nonetheless, there are a number of drawbacks to utilizing this method.
Exterior of privateness issues, when you’re selecting to run an LLM privately relatively than benefit from an current managed service, you then’re caught with managing the updates, and probably the infrastructure, your self. It’s additionally going to be far more costly to run an LLM privately. Taken collectively, these drawbacks imply operating a personal LLM seemingly doesn’t make sense for many corporations.
However the greater subject is that, from a privateness standpoint, non-public LLMs merely don’t present efficient knowledge privateness. Non-public LLMs offer you mannequin isolation, however they don’t present knowledge governance within the type of fine-grained entry controls: any consumer who can entry the non-public LLM can entry all the knowledge that it comprises. Knowledge privateness is about giving a consumer management over their knowledge, however non-public LLMs nonetheless endure from all the intrinsic limitations round knowledge deletion which can be blocking the adoption of public LLMs.
What issues to a enterprise—and particular person knowledge topics—is who sees what, when, the place, and for the way lengthy. Utilizing a personal LLM doesn’t provide the capability to ensure that Susie in accounting sees one sort of LLM response primarily based on her job title whereas Bob in buyer assist sees one thing else.
So how can we forestall PII and different delicate knowledge from getting into an LLM, but additionally assist knowledge governance so we will management who can see what and assist the necessity to delete delicate knowledge?
A new approach to PII management
On this planet of conventional knowledge administration, an more and more widespread method to defending the privateness of delicate knowledge is thru using a knowledge privateness vault. A knowledge privateness vault isolates, protects, and governs delicate buyer knowledge whereas facilitating region-specific compliance with legal guidelines like GDPR by means of knowledge localization.
With a vault structure, delicate knowledge is saved in your vault, remoted outdoors of your current techniques. Isolation helps make sure the integrity and safety of delicate knowledge, and simplifies the regionalization of this knowledge. De-identified knowledge that function references to the delicate knowledge are saved in conventional cloud storage and downstream companies.
De-identification occurs by means of a tokenization course of. This isn’t the identical as LLM tokenization, that has to do with splitting texts into smaller items. With knowledge de-identification, tokenization is a non-algorithmic method to knowledge obfuscation that swaps delicate knowledge for tokens. A token is a pointer that allows you to reference one thing some place else whereas offering obfuscation.

Let’s take a look at a easy instance. Within the workflow beneath a telephone quantity is collected by a entrance finish utility. The telephone quantity, together with some other PII, is saved securely within the vault, which is remoted outdoors of your organization’s current infrastructure. In trade, the vault generates a de-identified illustration of the telephone quantity (e.g. ABC123). The de-identified (or tokenized) knowledge has no mathematical reference to the unique knowledge, so it may possibly’t be reverse engineered.
Any downstream companies—utility databases, knowledge warehouse, analytics, any logs, and so on.—retailer solely a token illustration of the information, and are faraway from the scope of compliance:
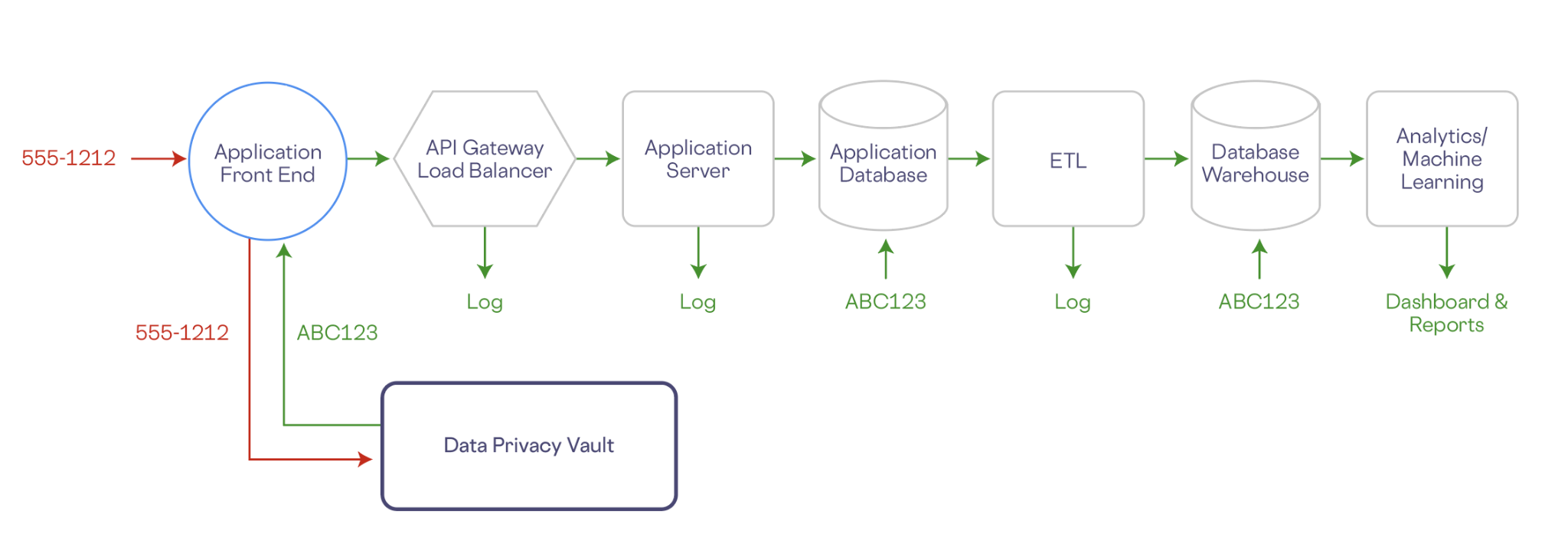
Moreover, a knowledge privateness vault can retailer delicate knowledge in a particular geographic location, and tightly management entry to this knowledge. Different techniques, together with LLMs, solely have entry to non-sensitive de-identified knowledge.
The vault not solely shops and generates de-identified knowledge, however it tightly controls entry to delicate knowledge by means of a zero belief mannequin the place no consumer account or course of has entry to knowledge except it’s granted by specific entry management insurance policies. These insurance policies are constructed from the underside, granting entry to particular columns and rows of PII. This lets you management who sees what, when, the place, for the way lengthy, and in what format.
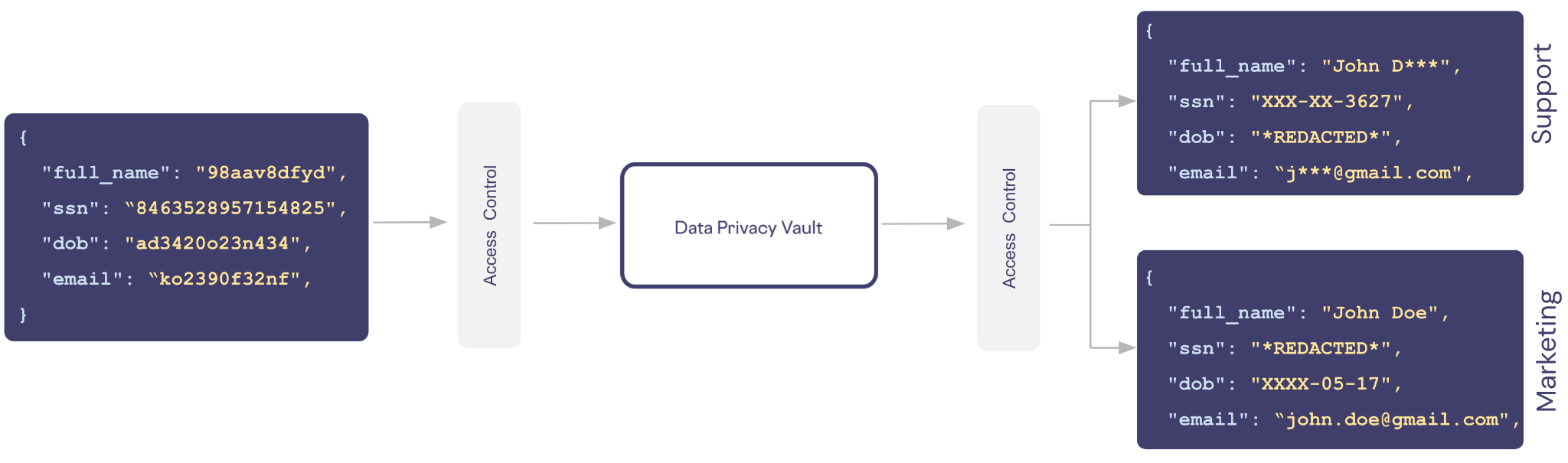
For instance, let’s say we have now a vault containing buyer data with columns outlined for a buyer’s title, social safety quantity (SSN), date of beginning (DOB), and e-mail. In our utility we need to assist two kinds of customers: assist and advertising.
Help doesn’t must know the precise particulars a few buyer, they solely want masked knowledge to allow them to converse to the shopper by title and confirm their id utilizing the final 4 digits of the shopper’s SSN.
We will create a coverage for the position assist that grants entry to solely the restricted view of the information.
ALLOW READ ON customers.full_name, customers.ssn, customers.e-mail WITH REDACTION = MASKED
ALLOW READ ON customers.dob WITH REDACTION = REDACTEDEqually, a advertising individual wants somebody’s title and e-mail, however they don’t want the shopper’s SSN or must know the way outdated somebody is.
ALLOW READ ON customers.full_name, customers.e-mail WITH REDACTION = PLAIN_TEXT
ALLOW READ ON customers.dob WITH REDACTION = MASKED
ALLOW READ ON customers.ssn WITH REDACTION = REDACTEDWith roles and insurance policies just like ones above in place, the identical de-identified knowledge is exchanged with the vault. Primarily based on the position and related entry management insurance policies for the caller, totally different views of the identical delicate knowledge may be supported.
A privacy firewall for LLMs
Corporations can handle privateness and compliance issues with LLMs with an analogous utility of the information privateness vault architectural sample. A knowledge privateness vault prevents the leakage of delicate knowledge into LLMs, addressing privateness issues round LLM coaching and inference.
As a result of knowledge privateness vaults use fashionable privacy-enhancing applied sciences like polymorphic encryption and tokenization, delicate knowledge may be de-identified in a approach that preserves referential integrity. Which means that responses from an LLM containing de-identified knowledge may be re-identified primarily based on zero belief insurance policies outlined within the vault that allow you to ensure that solely the proper data is shared with the LLM consumer. This allows you to be certain that Susie in accounting solely sees what she ought to have entry to (i.e., account numbers and bill quantities) whereas Bob in buyer assist sees solely what he must do his job.
Preserving privacy during model training
To protect privateness throughout mannequin coaching, the information privateness vault sits on the head of your coaching pipeline. Coaching knowledge that may embrace delicate and non-sensitive knowledge goes to the information privateness vault first. The vault detects the delicate knowledge, shops it throughout the vault, and replaces it with de-identified knowledge. The ensuing dataset is de-identified and secure to share with an LLM.

An LLM doesn’t care whether or not my title, Sean Falconer, is a part of the coaching knowledge or some constantly generated illustration of my title (akin to “dak5lhf9w”) is a part of the coaching knowledge. Ultimately, it’s only a vector.
Preserving privacy during inference
Delicate knowledge can also enter a mannequin throughout inference. Within the instance beneath, a immediate is created asking for a abstract of a will. The vault detects the delicate data, de-identifies it, and shares a non-sensitive model of the immediate with the LLM.
For the reason that LLM was educated on non-sensitive and de-identified knowledge, inference may be carried out as regular.
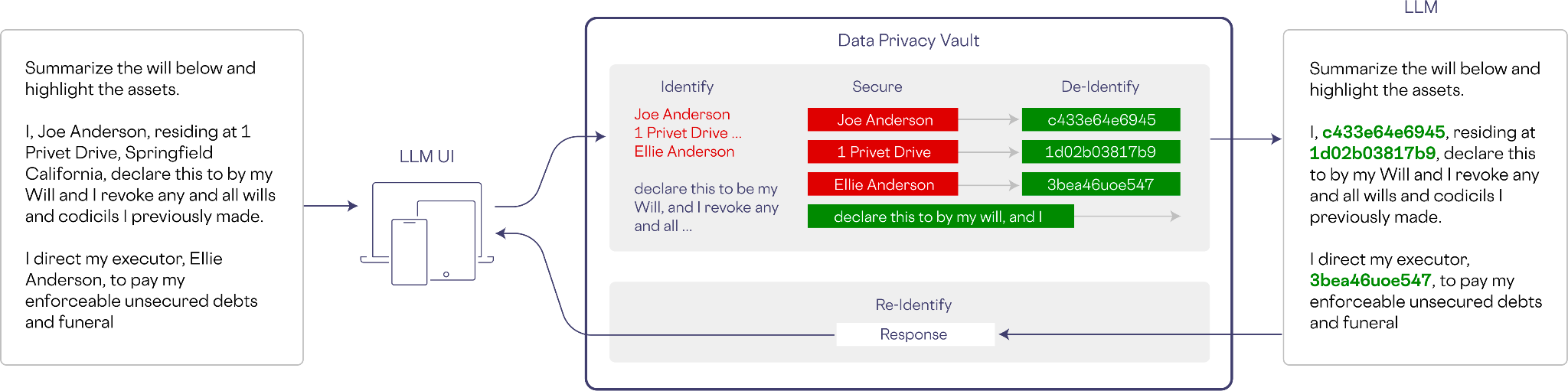
On egress from the LLM, the response is handed by means of the information privateness vault for re-identification. Any de-identified knowledge will likely be re-identified assuming the end-user has the proper to see the data, in response to specific entry management insurance policies configured within the vault.
Privacy and compliance
From a privateness and compliance standpoint, utilizing a knowledge privateness vault implies that no delicate knowledge is ever shared with an LLM, so it stays outdoors of the scope of compliance. Knowledge residency, DSARs, and delete requests are actually the duty of a knowledge privateness vault that’s designed to deal with these necessities and workflows.
Incorporating the vault into the mannequin coaching and inference pipelines permits you to mix one of the best of recent delicate knowledge administration with any LLM stack, non-public, public, or proprietary.
Final thoughts
As each firm steadily morphs into an AI firm, it’s critically essential to face knowledge privateness challenges head-on. With out a concrete answer to knowledge privateness necessities, companies threat remaining caught indefinitely within the “demo” or “proof-of-concept” section. The fusion of knowledge privateness vaults and generative AI presents a promising path ahead, releasing companies to harness the ability of AI with out compromising on privateness.

{kind=link}