Utilizing picture classification to foretell impending course of failures
Introduction
This text demonstrates use of CNN’s (Convolution Neural Networks) to foretell an impending course of failure in a paper machine utilizing an actual world dataset.
That is completed by arranging knowledge samples representing a number of consecutive time-slices into a picture that may be a snapshot of the previous and present state. If circumstances previous to a failure are totally different from regular operation, then photographs of the situation can warn of an impending failure. The aim isn’t to categorise a failure vs. a traditional operation, however to categorise a operating state as regular or as a warning of an impending failure.
The picture building, mannequin efficiency, and insights are mentioned with a number of charts spanning a month of course of knowledge.
Why do that?
Industrial programs run on course of controls. These maintain the system operating inside parameters. But, programs shut down. Excluding different components corresponding to handbook shut down, or gear failure, upsets nonetheless occur. Figuring out an impending failure might give operations employees time to forestall an upset. Moreover, analyzing a course of on this approach might present insights into why or what mixture of occasions result in an upset and supply a possibility to regulate the management system.
Dataset
The information used on this article is from ProcessMiner Inc. and could be discovered by way of a hyperlink to a obtain request type within the paper “Uncommon Occasion Classification in Multivariate Time Sequence” [1], used with permission.
This dataset covers roughly one month of operation of a paper machine with samples recorded at two-minute intervals. The options usually are not recognized with particular course of variable names and the information might have been adjusted for IP functions. There may be one categorical function that seems to separate the information into eight discrete working eventualities which can be associated to the kind or weight of paper or another parameter. I chosen probably the most frequent subset making up 36% of the information from this function (the place function X28 is 96) and lowered the variety of options by way of knowledge evaluation and utilizing function and permutation significance. Information of the precise options might enhance this step. The charts on this article are from one of the best performing mannequin and have subset, with some comparisons of outcomes from the opposite variations.
The paper breaks and have X28 are proven under. The paper breaks are the vertical traces in time. The blue line is function X28. The worth 96 happens at first, center, and finish of the month as indicated by the arrows.

Extra knowledge and data of the which means behind every function might produce a greater mannequin that is also refined with new knowledge month over month. Separate fashions for different X28 values may very well be constructed with extra knowledge, or these samples might probably be included via function transformation with knowledgeable course of data.
This dataset solely has course of values recorded each two minutes. The unique uncooked knowledge might be extra detailed in time. Completely different or a number of time intervals may very well be used with different datasets to achieve insights or present brief or longer interval predictions.
Six samples are wanted to make a single picture, so any knowledge with lower than 6 samples between breaks was eradicated.
Changing Information to Photos
The information is relabelled from 0 and 1 for regular and paper break, to 0 for regular, 1 for warning, and a couple of for paper break. The 5 samples previous every paper break are set to label 1.
Two derivatives with time are taken of the method measured values and saved in reminiscence as new knowledge tables. This offers a charge of change of the method measurements as a ‘velocity’ relative to place and an ‘acceleration’ relative to velocity. My considering was that these spinoff samples could also be indicative of paper breaks when there are excessive charges of change regardless that the function values are inside set level ranges.
The three knowledge tables are then scaled on a 0 to 1 vary and 6 durations of information are assigned to a picture overlaying a 12-minute interval. Every successive picture overlaps the earlier one by 5 time durations. Every picture is categorized by the label comparable to the final time slice in that picture: regular, warning, or paper break.
The photographs are in-built 3 layers with the method variable values or ‘place’ as the primary layer. The spinoff of the method values or ‘velocity’ is the second layer, and the third layer is the ‘acceleration’ values.
As soon as the failure time slice is within the final row of a picture, the method repeats by constructing the following picture beginning with the following 6 time durations following the earlier failure time slice.
The image under reveals twelve consecutive photographs constructed from the dataset main as much as a paper break and the final picture representing the situation after restarting the machine. The management level or measurement level worth (place), ‘velocity’, and ‘acceleration’ bands are seen in every picture. The picture order is left to proper by row with the higher left as the primary picture and decrease proper because the final. The numbers on the left are the unique regular (0) and paper break (1) labels comparable to the final time pattern in every picture. The numbers on the suitable are the adjusted labels with regular (0), warning (1), and paper break (2). The primary 5 photographs are regular working (00). The subsequent 5 are warning situation (01) of the 5 samples previous to the precise paper break. The paper break is subsequent (12) which is adopted by a traditional restart (00). All 6168 samples had been created this manner.

Picture by Writer
Fashions
I skilled three separate fashions utilizing three totally different picture units. These fashions differ within the options chosen for the picture building. The EDA / Place Function Significance mannequin used function significance on a Random Forest mannequin of solely the unique place values on discrete samples (not utilizing photographs with stacked samples). This was the primary mannequin / function record I labored with. The Function Significance and Permutation Significance fashions use options excessive graded from a RF mannequin constructed from the place, velocity and acceleration mixed on discrete samples. I stored the identical picture building foundation, so place, velocity, and acceleration values are stored for any function that ranks excessive whether or not it’s the authentic place or a derived velocity or acceleration function. Here’s a pattern chart of one of the best mannequin over a 5-hour interval. Extra charts on the efficiency of one of the best mannequin are included later. (Higher observe: regular 0, warning 1, paper break 2)

Coaching
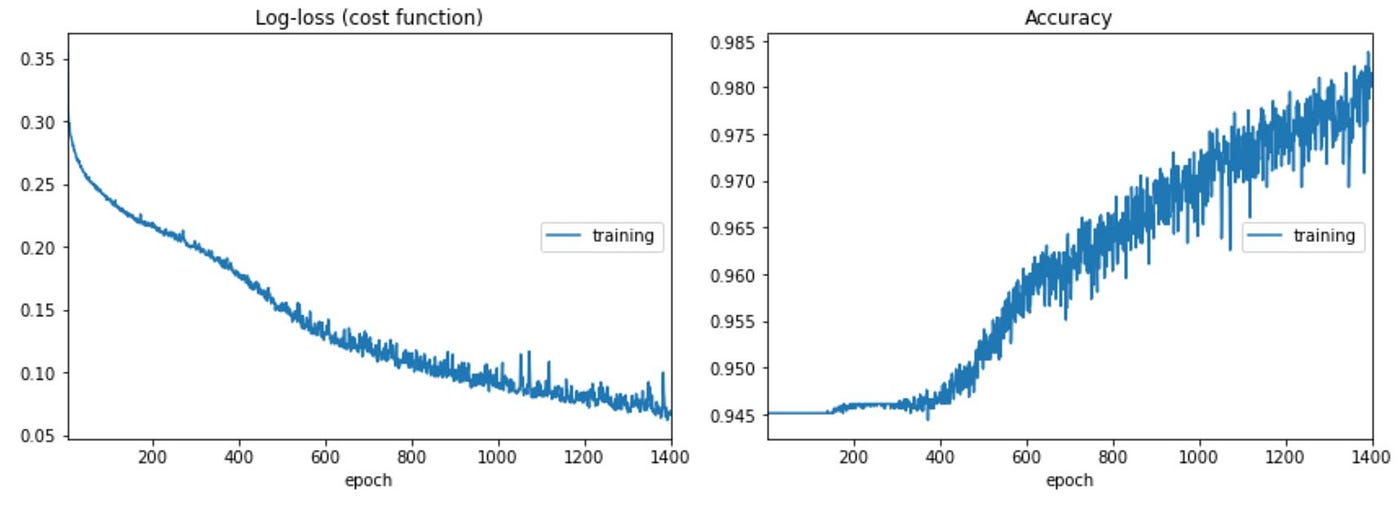
Coaching is just like the prototype CNN mannequin. I used a Sequential CNN mannequin with two Conv2D, two MaxPooling, and a Flatten layer feeding a three-layer 128–64–3 community with Dropout. I didn’t beneath pattern the traditional class to maintain as a lot variability in what a traditional situation ‘appears like’. Thus, the excessive preliminary accuracy. Particulars could be discovered on Github right here.
Outcomes
I utilized a customized classifier to the mannequin likelihood predictions (predict_proba) quite than utilizing the usual argmax prediction because of the imbalance within the dataset. Many of the photographs, about 94%, are from the traditional class, and warning and paper break photographs make up about 5% and 1% respectively. The customized classifier eliminates a category if the anticipated class likelihood is under the frequency of that class within the dataset. For instance, if a warning and paper break chances are 8% and three%, then the traditional likelihood could be 89% after which is excluded. The prediction is the argmax of the remaining two chances and could be a warning. The customized classifier confusion matrix is on the left and the usual argmax prediction is on the suitable. Outcomes are proven for 3 totally different fashions.

The customized classifier has the next true constructive charge on the warning state versus Argmax, however the next false constructive charge, predicting a warning for regular state circumstances between 4 and 9 instances extra typically relying on the mannequin.
The target is to foretell a paper break earlier than it occurs to permit time for intervention. Thus, the upper true constructive efficiency for the customized classifier (Adjusted Prediction) is engaging at this stage, even on the expense of upper false constructive warning states. Though we need to cut back the variety of false positives (nuisance alarms) in a manufacturing mannequin, this isn’t at that state. There doubtlessly is so much to be realized from the false warnings on this scenario versus simply leaping forward and adopting the low false warnings of the Function Significance mannequin with the usual Argmax classification. Discuss with the 2 charts under utilizing the identical mannequin. This primary makes use of the customized classifier and the second the usual Argmax choice. The Argmax ignores the time the place the method seems to be unsettled and finally has a paper break (excessive lighted with the circle) and avoids ‘false warnings’ and misses lots of the named warnings, whereas the customized classifier reveals nearly all warnings. What’s the actual distinction between these samples and those simply previous to a paper break after an extended steady working run?


Trying on the outcomes from the confusion matrix and the charts under, I see three issues may very well be occurring with these fashions and dataset.
Firstly, the fashions simply is probably not performing very effectively.
Secondly, keep in mind the uncooked knowledge solely has regular and paper break lessons. I arbitrarily chosen 5 samples previous to a paper break because the warning class. There may very well be many “regular” samples the place the method state is just like a pre-failure situation and a number of the false positives for a warning are literally instances when the system is near having a paper break however recovers to regular working ranges with out incurring a break. This could be insightful and could also be the place the very best worth is gained. e.g., Working with operations to discover similarities in precise pre-failure samples and different “regular” samples or to grasp if the speed of change of a function is extra indicative of an issue even when the function worth is inside set level limits. The dataset options are anonymized, and interpretation of my outcomes are restricted with out figuring out the options and never being an knowledgeable on paper machines. Information of the particular options with good apply of iteration and assessment with area specialists (i.e., paper machine specialists) would affirm insights or establish modelling points.
Preliminary fashions with false positives could be helpful in understanding nuances within the course of or course of management system. In different phrases, regardless that a pattern is labelled as regular, doesn’t imply that it isn’t operating close to or trending to a paper break (or course of fault in different programs).
Thirdly, there could also be a bias constructed into the best way I labelled the warning states resulting in greater false positives. I picked 5 time durations (10 minutes) earlier than an precise break to be labelled as a warning to offer some practicality for time to intervene within the course of. Situations within the paper machine might develop to a paper break a lot sooner, and thus 2 or 3 of the warning states earlier than some, or all the breaks, is probably not consultant of a course of deviation. Thus, labelling knowledge as a warning state when it’s completely regular could lead on the mannequin to foretell small course of deviations as proof of an imminent paper break and / or cut back the efficiency of predicting warnings within the take a look at set. Lowering the variety of warning states earlier than a paper break might enhance the mannequin however would additionally cut back the time to intervene to forestall a break.
Charts
I’ve included a number of charts to present an summary of how the mannequin carried out in addition to how totally different durations within the knowledge seem as a easily operating machine or as a considerably unstable machine, generally after start-up. Charts are from the mannequin constructed with options derived from Function Significance run on samples with place and two derivatives utilizing the adjusted predictor (labeled based mostly on the likelihood of sophistication and the frequency of that class within the pattern set). Extra charts are in Jupyter Notebooks on my Github.
The charts present the take a look at and coaching outcomes (operating the coaching set via the ultimate mannequin) plotted collectively by the day and time of the samples. I current them this manner as a result of plots of the coaching and take a look at units ordered consecutively by pattern don’t present how efficiency adjustments via the month as a result of the samples are shuffled. Additionally, separate plots of the take a look at and coaching units by time have gaps from the lacking knowledge in both the take a look at or coaching set.
These plots have two tracks. The higher observe has the anticipated class, regular (0), warning (1), and paper break (2) from the mannequin. This observe additionally has the precise labels for warnings as circles, and the paper breaks as diamonds. The take a look at predictions are blue dots, and the coaching predictions are blue X’s. With shorter time intervals, it’s straightforward to see the place the prediction and actuals align.
The decrease observe has the likelihood of sophistication (0 to 1) plotted for take a look at and coaching predictions. Right here take a look at outcomes are dots and coaching outcomes are X’s. The chances by class are inexperienced for regular, yellow for warning, and pink for paper breaks (additionally labelled as faults).
Chart 1 reveals the distribution of the pattern subset via the month with 58 paper breaks on this knowledge subset.

Chart 2 is a 4–1/2 hour operating interval on Might 5 from 13:00 to 17:30 hours. This reveals how a small drop in regular likelihood under 94% is accompanied by a warning likelihood above its prevalence frequency within the knowledge and thus a warning prediction. There are a number of ‘false’ warnings which may very well be attributable to irregular working circumstances. These durations of excessive ‘false’ warnings are likely to occur extra typically near a paper break or when there’s a brief run time from start-up to a paper break. The 2 breaks within the chart had been predicted as warnings vs. breaks.

Chart 3 has a spot the place 68 minutes of lacking knowledge. It seems that the machine ran constantly till the paper break at 23:00 hours. This interval has far fewer false warnings than in Chart 2 above.
Chart 4 reveals a clean run time over about 28 hours. The false warnings are extra frequent after the machine restarts (on the left) and earlier than the paper break at about 15:00 hours on the 14th of the month.

Chart 5 reveals a clear 11 hour run time that precedes Chart 6.

Chart 6 follows Chart 5 above in time and reveals the mannequin predicting warnings constantly forward of a paper break.

Chart 6a is the corresponding outcomes from the bottom mannequin (EDA / Place Function Significance Mannequin). This mannequin used totally different options and has extra ‘false warnings’ than the Function Significance Mannequin above (which makes use of place, velocity, and acceleration within the function choice). There could also be worth in these false warning with totally different options however data of the options is required to find out the distinction between perception and poor mannequin efficiency.

Recap
The target was to not classify paper breaks versus regular working circumstances since figuring out the paper break after it has occurred doesn’t have any operational profit. Figuring out adjustments in working circumstances which are prone to result in a paper break doubtlessly has worth for operator intervention, enhancing course of management logic, or perceive second order or compounding results of concurrent shifts in a number of course of measurements.
This work confirmed {that a} CNN mannequin may very well be used to foretell or warn of an impending course of failure on a real-world dataset. The mannequin may very well be improved with extra knowledge and data in regards to the precise paper machine that produced the information. This strategy may very well be utilized in different processes, not essentially as a management system, however to discover upsets and high-quality tune programs.
This isn’t a manufacturing stage mannequin the place minimizing false warnings is essential. Digging into the chance that the false positives are deviation instances that recovered (as acknowledged above) is a part of the iterative strategy wanted in growing manufacturing fashions that features consulting with subject material specialists within the course of design and operations. A mannequin isn’t skilled and deployed in a single step. Insights could be gained in a multidisciplinary strategy to grasp whether or not the mannequin simply isn’t good, or if the mannequin is telling you one thing and use that to enhance the mannequin or perceive the economic course of.
I welcome your feedback.
Particular Thanks
Particular because of Chitta Ranjan, Director of Science at ProcessMiner Inc. for graciously giving me permission to publish this text and share my strategy and outcomes.
Associated Article
That is an extension of a prototype article the place I created an artificial dataset and skilled a CNN picture classification mannequin on photographs representing regular circumstances and pre-failure time slices as a warning state.
Reference
[1]Chitta Ranjan, Markku Mustonen, Kamran Paynabar, Karim Pourak, “Uncommon Occasion Classification in Multivariate Time Sequence”, 2018, arXiv:1809.10717, dataset used with permission.
