
Finish-to-end phyton venture train knowledge from an Apple Watch, from knowledge assortment to mannequin deployment

On this sequence of posts, I’ll undergo all steps of an end-to-end machine studying venture. From knowledge extraction and preparation to the deployment of the mannequin utilizing an API and at last to the creation of a entrance finish to truly resolve the issue serving to with selections. The primary matters of every one are:
- Undertaking setup, Information Processing, and Information Exploration
- Mannequin Experimenting
- Mannequin Deployment
- Information App creation
So let’s start with the primary half:
The primary and most vital a part of any venture is clearly defining what downside you might be fixing. When you don’t have a transparent definition of it, you need to most likely return and brainstorm why you got here up with that concept and if that is actually an issue not just for you. There are a whole lot of methodologies within the product space that I received’t enter on this article to assist on this step. For now, we are going to solely concentrate on defining the present downside.
The Drawback
Identical to most individuals, I hope, I’ve a tough time staying absolutely motivated to work out daily. A instrument that helps me typically is having a smartwatch to trace my progress and assist with options comparable to seeing pals’ exercises and competitions. Nevertheless, they aren’t sufficient and I nonetheless have ups and downs in my motivation. That’s why I, as a Information Scientist, need to examine my previous exercises to determine what the primary variables which have motivated me prior to now are, and to foretell my likelihood of reaching my train objectives sooner or later.
Defining it in a single sentence we now have:
My downside is sustaining motivation to work out for a protracted time frame
Now that we now have outlined what downside we need to resolve, we are able to begin organising our venture and our answer.
Undertaking Setup
In a daily Information Science venture, there are a few preliminary steps that we should comply with.
- Git repository setup
- Infrastructure provisioning
- Setting setup
With the ability to create variations of your venture and your code is essential in any software program venture. So our first step might be making a GitHub Repository as a way to retailer and create variations of your code. One other fascinating characteristic of GitHub is the aptitude of sharing and contributing to different folks’s code.
I cannot go step-by-step on how one can create a repository; simply kind “Learn how to create a Github Repository” and also you’ll be good to go. For this venture, I’m utilizing this repository.
The second half is provisioning infrastructure on the cloud to develop and later deploy your answer. For now, I cannot want a cloud infrastructure as a result of the information quantity matches properly in my laptop computer for this preliminary evaluation. Once we dive into creating experiments and tuning our Hyper Parameters I’ll present you ways to do that on Google Cloud Platform, particularly utilizing Vertex AI.
The final half is making a digital atmosphere to develop. I like to make use of pyenv for this job. To put in pyenv look right here. Lastly, there are a whole lot of OS that you should use, however I personally want utilizing a Unix based mostly comparable to MacOS or in case you have Home windows you may set up a home windows subsystem for Linux. One other a part of the atmosphere is protecting observe of your libraries by way of the necessities.txt file. There’s an instance within the GitHub repository of the venture.
The information
Now, to get the information that we want we now have to export the information from the Well being App on an iPhone. That is very easy to do, so simply look right here at how one can do it.
Now we are able to (lastly) begin coding.
The export file comes as a zipper containing a folder inside with routes, electrocardiograms, and an XML with all of your well being knowledge. The code beneath will unzip the folder, parse the XML and reserve it as a CSV.
That is the primary a part of our knowledge processing pipeline. If we want to share this performance or just add newer knowledge, having a code structured to course of the information is crucial. Observe that the code is structured as a perform. This may give us flexibility and modularity in our pipeline.
Now we now have the next knowledge body able to be modeled.

Haha, simply kidding.
In actual life, the information is nearly by no means prepared to make use of like a Kaggle Dataset. On this case, we now have issues with knowledge codecs, metadata entries are saved inside lists, and dates must be transformed, simply to call a number of of the issues we now have to cope with this primary.
What was performed:
- Filter solely Train minutes knowledge
- Rework dates to DateTime format
- Rework values to drift
- Create a date column with out time, solely with days
- Group the worth for Train minutes for every day
Now we now have a time sequence of our Train Minutes for every day. I chosen Train Minutes as an alternative of Burned Energy as a result of this measures the times that I labored out as an alternative of the energy spent. That is what we name a premise of the venture. It is extremely essential to maintain observe of those premises documenting them together with the issue assertion.
Okay, we’re making some progress now. So now we are able to start creating fashions, proper?
We have now only a couple extra issues to do earlier than that. First, we have to verify the standard of the information, then we are going to create some options and do some exploratory plots to generate some insights earlier than the modeling.
Information High quality verify
Once we speak about knowledge high quality we must always go as deep as how the information is collected and consider some issues that may occur within the course of. Since this knowledge is collected on my Apple Watch, the very first thing we must always discover is what occurs on the times I didn’t put on my watch?
This boils down to 2 issues we at all times must verify in our knowledge:
- Lacking knowledge
- Outliers
There is no such thing as a lacking knowledge by way of NAs. Nevertheless, there are 167 observations with 0 because the variety of train minutes, this seems to be the best way they register days with out the watch. We will clearly see it on this histogram:
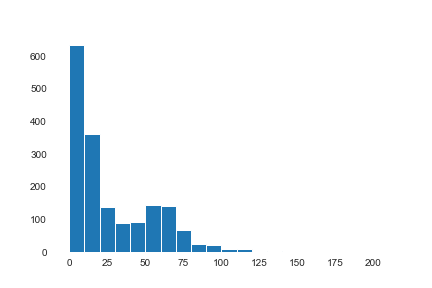
Looking for outliers we are able to see that there’s a couple of them, however we are going to preserve them as a result of they’re correct to the truth, not anomalies.

There are a whole lot of different checks we are able to do to confirm knowledge high quality, however for this case, we won’t go into them as a result of this knowledge supply is standardized and fairly dependable.
Some essential data we gathered from the information:
- There are 1.737 observations (days);
- 167 observations have 0 because the train minutes of that day;
- The dates go from 2017–09–25 to 2022–06–27;
- There are not any lacking dates on this vary.
Function Engineering
Now we are able to get on some enjoyable stuff. The characteristic engineering step is the place we create hypotheses of what options might be helpful to the mannequin. That is an iterative course of so we are going to create some right here, validate them later and add or take away options.
Some guesses that I’ve got here from traditional time-series options. They’re:
- Date attributes (day, weekday, month, yr, season)
- Lag options (what number of energy had been spent within the final interval)
- Rolling Window options (shifting common, commonplace deviation, max, min)
Within the subsequent half, we are going to add another knowledge comparable to sleep high quality.
Here is the code:
One other essential transformation was making a round encoding of the month characteristic. This can be a nice trick to encode time options which have a cycle. This works by getting the sine and cosine for every month and ultimately, we now have one thing like this:
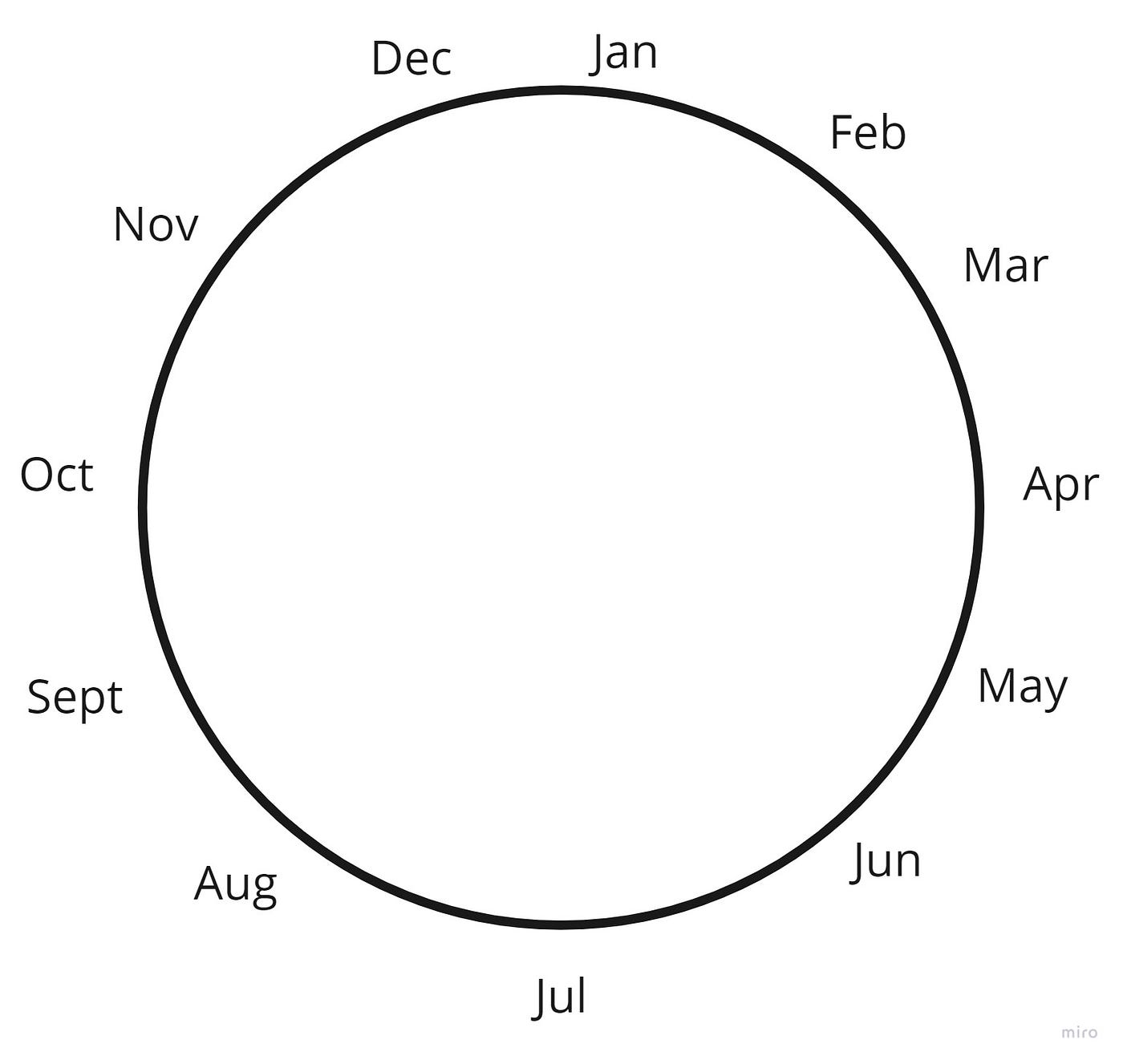
We will see that December and January are a lot nearer to one another as an alternative of being 1 and 12 that are farther aside.
Exploratory Evaluation
Now we’ll go into some easy, however highly effective evaluation. This step can and sometimes needs to be carried out earlier than the characteristic engineering, however on this case, I wanted some options for the plots.
Keep in mind: That is an iterative course of
In a protracted venture, you may go into these steps in lots of cycles earlier than arriving on the last answer.
We already appeared on the distribution of our knowledge in a earlier step, so now we are able to see how the minutes of train differ with some temporal options.
Let’s begin with the years:
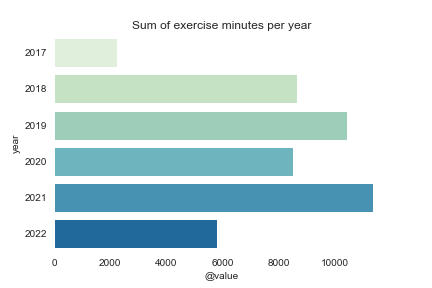
We will see that 2020 stopped my development primarily due to lockdowns from the COVID pandemic.
We will evaluate the distribution of the information by every month.
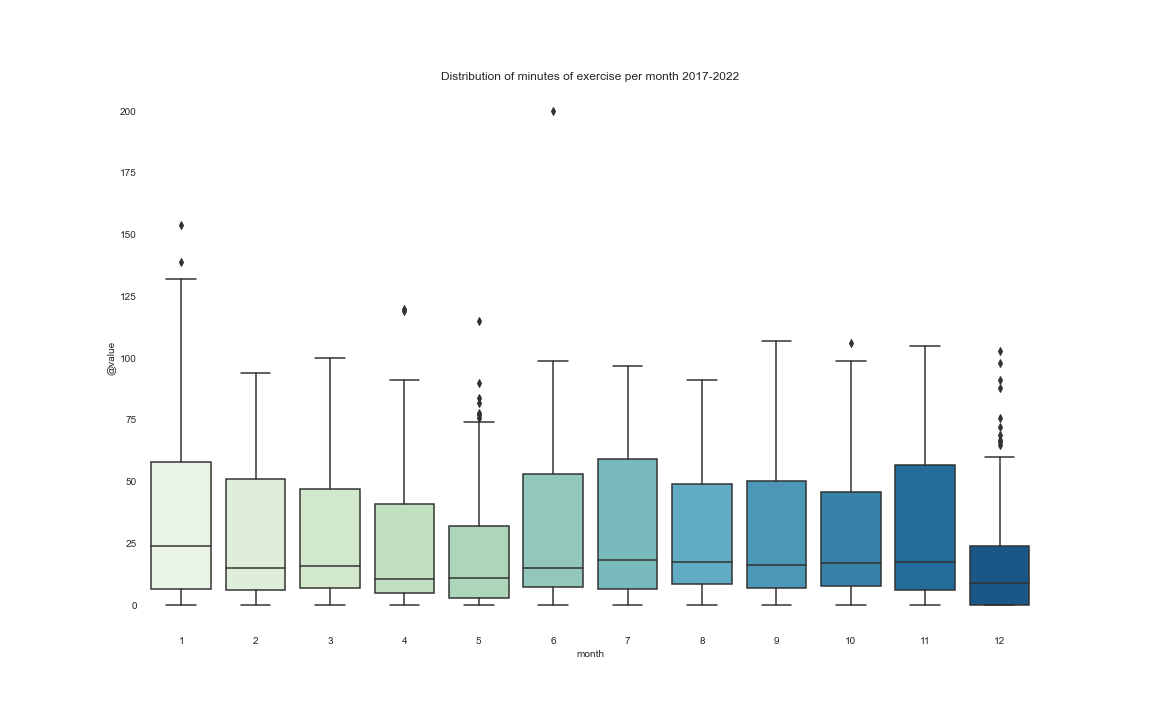
Right here we are able to clearly see that December is just not my finest buddy. The primary causes are straightforward to establish: end-of-year events, holidays, Christmas, and I normally go on trip.
Another good factor to take a look at is how my exercises differ throughout completely different days of the week. For this evaluation, we contemplate Monday as label 0 and Sunday as label 6.
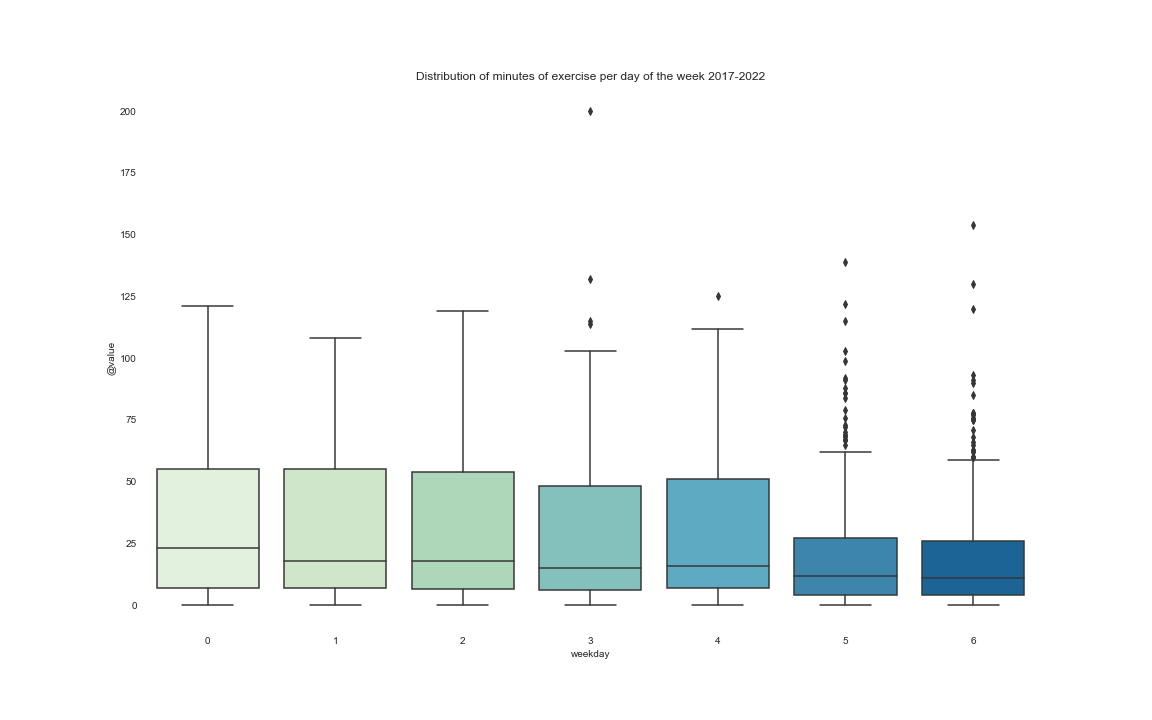
The median of train minutes is just not that removed from the opposite days of the week nevertheless, it’s rarer to have large exercises on the weekend.
There are actually infinite visualizations you may create together with your knowledge. For now, we are going to cease at these above. The essential factor right here is to grasp your knowledge, the distributions, and the way it behaves in several aggregations.
You too can create selections based mostly on these analyses. One instance right here is wanting on the weekend knowledge development to be decrease. A doable resolution is to create a rule that I can solely drink on the weekends if I work out.
The very last thing we’ll do earlier than the modeling is decomposing our time sequence. Oh, I forgot to say however what we now have here’s a time sequence. Here is the definition:
A Time Collection is a sequence of repeated observations thought-about inside a sure time interval which are taken at equal (common/evenly spaced) time intervals
We will decompose a time sequence to grasp two very helpful issues:
- Pattern
- Seasonality
A time sequence consists of the becoming a member of of these two with some residuals. There are a few strategies to decompose it, right here we are going to use the additive methodology. Time sequence is a big topic, so if you wish to go deeper go right here.
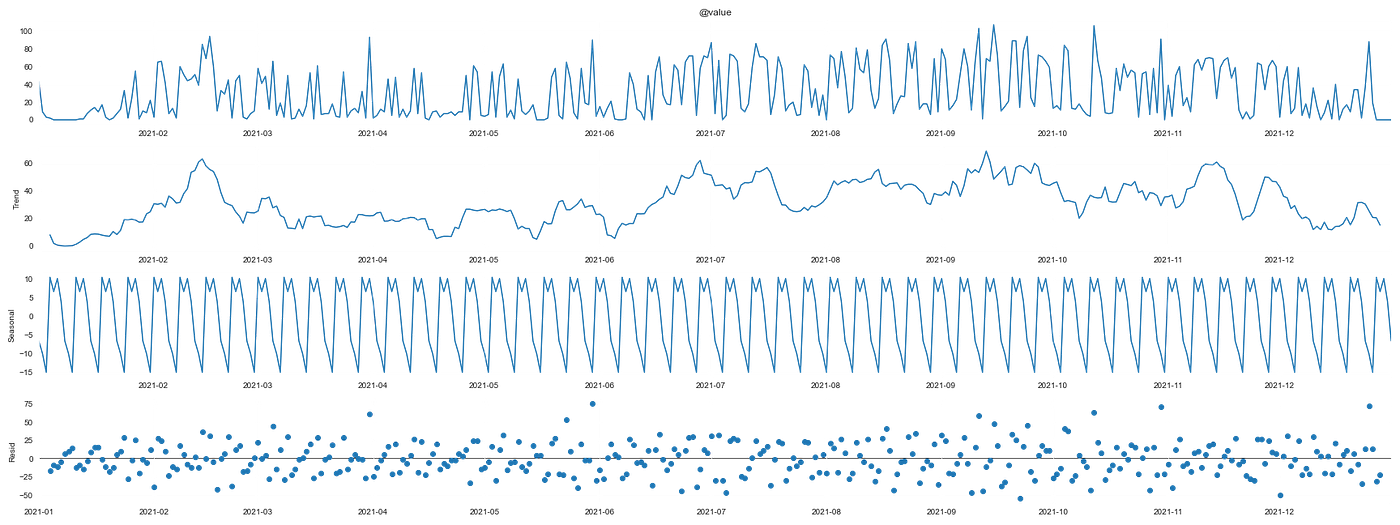
In order that’s a whole lot of data, let’s dig into it.
The primary plot is the unique time sequence. The second is the development element, the third is the seasonality and the final one is the residuals.
The essential data that we get from her is:
- We will establish a seasonality that may be associated to the weeks, however not a lot between months;
- The residuals look like uniformly distributed.
That helps us with two issues. Within the characteristic engineering step, we created options to seize the proper seasonality and if we needed to use traditional time sequence fashions we must insert that seasonality within the parameters.
That’s it for now.
Key Takeaways
The primary takeaways of this half are:
- DEFINE THE PROBLEM;
- Set your atmosphere up not forgetting to document your packages variations;
- Report your venture premisses;
- Construction your knowledge processing into capabilities that may be reused additional down the street with new knowledge;
- Perceive and clear your knowledge;
- If doable create some descriptive evaluation that may already generate selections.
Within the subsequent half:
- We are going to arrange an experimenting framework with MLFlow to document and evaluate our fashions
- We are going to create a number of fashions and evaluate them
- We are going to select a mannequin and optimize its hyperparameters

{kind=link}