
As any web site proprietor will let you know, knowledge loss and downtime, even in minimal doses, may be catastrophic. They’ll hit the unprepared at any time, resulting in diminished productiveness, accessibility, and product confidence.
To guard the integrity of your web site, it’s important to construct safeguards towards the potential for downtime or knowledge loss.
That’s the place knowledge replication is available in.
As any web site proprietor will let you know that knowledge loss and downtime, even in minimal doses, may be catastrophic.  Enter, knowledge replication
Enter, knowledge replication 
Knowledge replication is an automatic backup course of during which your knowledge is repeatedly copied from its primary database to a different, distant location for safekeeping. It’s an integral expertise for any web site or app operating a database server. You may also leverage the replicated database to course of read-only SQL, permitting extra processes to be run throughout the system.
Organising replication between two databases provides fault tolerance towards sudden mishaps. It’s thought-about to be the very best technique for attaining excessive availability throughout disasters.
On this article, we’ll dive into the completely different methods that may be carried out by backend builders for seamless PostgreSQL replication.
What Is PostgreSQL Replication?
PostgreSQL replication is outlined as the method of copying knowledge from a PostgreSQL database server to a different server. The supply database server is also referred to as the “main” server, whereas the database server receiving the copied knowledge is called the “duplicate” server.
The PostgreSQL database follows an easy replication mannequin, the place all writes go to a main node. The first node can then apply these adjustments and broadcast them to secondary nodes.
What Is Computerized Failover?
As soon as bodily streaming replication has been configured in PostgreSQL, failover can happen if the database’s main server fails. Failover is used to outline the restoration course of, which might take some time, because it doesn’t present built-in instruments to scope out server failures.
You don’t must be depending on PostgreSQL for failover. There are devoted instruments that enable computerized failover and computerized switching to the standby, slicing down on database downtime.
By establishing failover replication, you all however assure excessive availability by making certain that standbys can be found if the first server ever collapses.
Advantages of Utilizing PostgreSQL Replication
Listed here are a number of key advantages of leveraging PostgreSQL replication:
- Knowledge migration: You possibly can leverage PostgreSQL replication for knowledge migration both via a change of database server {hardware} or via system deployment.
- Fault tolerance: If the first server fails, the standby server can act as a server as a result of the contained knowledge for each main and standby servers is identical.
- On-line transactional processing (OLTP) efficiency: You possibly can enhance the transaction processing time and question time of an OLTP system by eradicating reporting question load. Transaction processing time is the length it takes for a given question to be executed earlier than a transaction is completed.
- System testing in parallel: Whereas upgrading a brand new system, you must guarantee that the system fares nicely with present knowledge, therefore the necessity to take a look at with a manufacturing database copy earlier than deployment.
How PostgreSQL Replication Works
Usually, individuals imagine if you’re dabbling with a main and secondary structure, there’s just one technique to arrange backups and replication, however PostgreSQL deployments comply with one of many following three approaches:
- Quantity degree replication to copy on the storage layer from the first to the secondary node, adopted by backing it as much as blob/S3 storage.
- PostgreSQL streaming replication to copy knowledge from the first to the secondary node, adopted by backing it as much as blob/S3 storage.
- Taking incremental backups from the first node to S3 whereas reconstructing a brand new secondary node from S3. When the secondary node is within the neighborhood of the first, you can begin streaming from the first node.
Method 1: Streaming
PostgreSQL streaming replication also referred to as WAL replication may be arrange seamlessly after putting in PostgreSQL on all servers. This strategy to replication is predicated on transferring the WAL information from the first to the goal database.
You possibly can implement PostgreSQL streaming replication by utilizing a primary-secondary configuration. The first server is the principle occasion that handles the first database and all its operations. The secondary server acts because the supplementary occasion and executes all adjustments made to the first database on itself, producing an similar copy within the course of. The first is the learn/write server whereas the secondary server is merely read-only.
For this strategy, you must configure each the first node and the standby node. The next sections will elucidate the steps concerned in configuring them with ease.
Configuring Main Node
You possibly can configure the first node for streaming replication by finishing up the next steps:
Step 1: Initialize the Database
To initialize the database, you’ll be able to leverage the initidb utility command. Subsequent, you’ll be able to create a brand new consumer with replication privileges by using the next command:
CREATE USER REPLICATION LOGIN ENCRYPTED PASSWORD '';The consumer should present a password and username for the given question. The replication key phrase is used to offer the consumer the required privileges. An instance question would look one thing like this:
CREATE USER rep_user REPLICATION LOGIN ENCRYPTED PASSWORD 'rep_pass'Step 2: Configure Streaming Properties
Subsequent, you’ll be able to configure the streaming properties with the PostgreSQL configuration file (postgresql.conf) that may be modified as follows:
wal_level = logical
wal_log_hints = on
max_wal_senders = 8
max_wal_size = 1GB
hot_standby = onRight here’s slightly background across the parameters used within the earlier snippet:
wal_log_hints: This parameter is required for thepg_rewindfunctionality that turns out to be useful when the standby server’s out of sync with the first server.wal_level: You should use this parameter to allow PostgreSQL streaming replication, with doable values together withminimal,duplicate, orlogical.max_wal_size: This can be utilized to specify the scale of WAL information that may be retained in log information.hot_standby: You possibly can leverage this parameter for a read-on reference to the secondary when it’s set to ON.max_wal_senders: You should usemax_wal_sendersto specify the utmost variety of concurrent connections that may be established with the standby servers.
Step 3: Create New Entry
After you’ve modified the parameters within the postgresql.conf file, a brand new replication entry within the pg_hba.conf file can enable the servers to ascertain a reference to one another for replication.
You possibly can normally discover this file within the knowledge listing of PostgreSQL. You should use the next code snippet for a similar:
host replication rep_user IPaddress md5As soon as the code snippet will get executed, the first server permits a consumer referred to as rep_user to attach and act because the standby server by utilizing the required IP for replication. As an illustration:
host replication rep_user 192.168.0.22/32 md5Configuring Standby Node
To configure the standby node for streaming replication, comply with these steps:
Step 1: Again Up Main Node
To configure the standby node, leverage the pg_basebackup utility to generate a backup of the first node. It will function a place to begin for the standby node. You should use this utility with the next syntax:
pg_basebackp -D -h -X stream -c quick -U rep_user -WThe parameters used within the syntax talked about above are as follows:
-h: You should use this to say the first host.-D: This parameter signifies the listing you’re at present engaged on.-C: You should use this to set the checkpoints.-X: This parameter can be utilized to incorporate the required transactional log information.-W: You should use this parameter to immediate the consumer for a password earlier than linking to the database.
Step 2: Set Up Replication Configuration File
Subsequent, you must test if the replication configuration file exists. If it doesn’t, you’ll be able to generate the replication configuration file as restoration.conf.
You must create this file within the knowledge listing of the PostgreSQL set up. You possibly can generate it robotically by utilizing the -R possibility throughout the pg_basebackup utility.
The restoration.conf file ought to include the next instructions:
standby_mode = ‘on’
primary_conninfo = ‘host=<master_host> port=<postgres_port> consumer=<replication_user> password=<password> application_name=”host_name”‘
recovery_target_timeline = ‘newest’
The parameters used within the aforementioned instructions are as follows:
primary_conninfo: You should use this to make a connection between the first and secondary servers by leveraging a connection string.standby_mode: This parameter may cause the first server to start out because the standby when switched ON.recovery_target_timeline: You should use this to set the restoration time.
To arrange a connection, you must present the username, IP handle, and password as values for the primary_conninfo parameter. As an illustration:
primary_conninfo = 'host=192.168.0.26 port=5432 consumer=rep_user password=rep_pass'Step 3: Restart Secondary Server
Lastly, you’ll be able to restart the secondary server to finish the configuration course of.
Nonetheless, streaming replication comes with a number of challenges, comparable to:
- Varied PostgreSQL shoppers (written in numerous programming languages) converse with a single endpoint. When the first node fails, these shoppers will maintain retrying the identical DNS or IP title. This makes failover seen to the appliance.
- PostgreSQL replication doesn’t include built-in failover and monitoring. When the first node fails, you must promote a secondary to be the brand new main. This promotion must be executed in a approach the place shoppers write to just one main node, they usually don’t observe knowledge inconsistencies.
- PostgreSQL replicates its total state. When you must develop a brand new secondary node, the secondary must recap the whole historical past of state change from the first node, which is resource-intensive and makes it pricey to remove nodes within the head and create new ones.
Method 2: Replicated Block Gadget
The replicated block gadget strategy will depend on disk mirroring (also referred to as quantity replication). On this strategy, adjustments are written to a persistent quantity which will get synchronously mirrored to a different quantity.
The additional benefit of this strategy is its compatibility and knowledge sturdiness in cloud environments with all relational databases, together with PostgreSQL, MySQL, and SQL Server, to call a number of.
Nonetheless, the disk-mirroring strategy to PostgreSQL replication wants you to copy each WAL log and desk knowledge. Since every write to the database now must go over the community synchronously, you’ll be able to’t afford to lose a single byte, as that would go away your database in a corrupt state.
This strategy is often leveraged utilizing Azure PostgreSQL and Amazon RDS.
Method 3: WAL
WAL consists of section information (16 MB by default). Every section has a number of information. A log sequence report (LSN) is a pointer to a report in WAL, letting you realize the place/location the place the report has been saved within the log file.
A standby server leverages WAL segments — also referred to as XLOGS in PostgreSQL terminology — to constantly replicate adjustments from its main server. You should use write-ahead logging to grant sturdiness and atomicity in a DBMS by serializing chunks of byte-array knowledge (each with a singular LSN) to secure storage earlier than they get utilized to a database.
Making use of a mutation to a database may result in varied file system operations. A pertinent query that comes up is how a database can guarantee atomicity within the occasion of a server failure as a result of an influence outage whereas it was in the midst of a file system updation. When a database boots, it begins a startup or replay course of which might learn the accessible WAL segments and compares them with the LSN saved on each knowledge web page (each knowledge web page is marked with the LSN of the newest WAL report that impacts the web page).
Log Transport-Based mostly Replication (Block Stage)
Streaming replication refines the log transport course of. Versus ready for the WAL swap, the information are despatched as they get created, thus lowering replication delay.
Streaming replication additionally trumps log transport as a result of the standby server hyperlinks with the first server over the community by leveraging a replication protocol. The first server can then ship WAL information straight over this connection with out having to rely on scripts offered by the end-user.
Log Transport-Based mostly Replication (File Stage)
Log transport is outlined as copying log information to a different PostgreSQL server to generate one other standby server by replaying WAL information. This server is configured to work in restoration mode, and its sole objective is to use any new WAL information as they present up.
This secondary server then turns into a heat backup of the first PostgreSQL server. It can be configured to be a learn duplicate, the place it may well supply read-only queries, additionally known as sizzling standby.
Steady WAL Archiving
Duplicating WAL information as they’re created into any location apart from the pg_wal subdirectory to archive them is called WAL archiving. PostgreSQL will name a script given by the consumer for archiving, every time a WAL file will get created.
The script can leverage the scp command to duplicate the file to a number of places comparable to an NFS mount. As soon as archived, the WAL section information may be leveraged to recuperate the database at any given cut-off date.
Different log-based configurations embody:
- Synchronous replication: Earlier than each synchronous replication transaction will get dedicated, the first server waits till standbys affirm that they acquired the information. The advantage of this configuration is that there received’t be any conflicts induced as a result of parallel writing processes.
- Synchronous multi-master replication: Right here, each server can settle for write requests, and modified knowledge will get transmitted from the unique server to each different server earlier than every transaction will get dedicated. It leverages the 2PC protocol and adheres to the all-or-none rule.
WAL Streaming Protocol Particulars
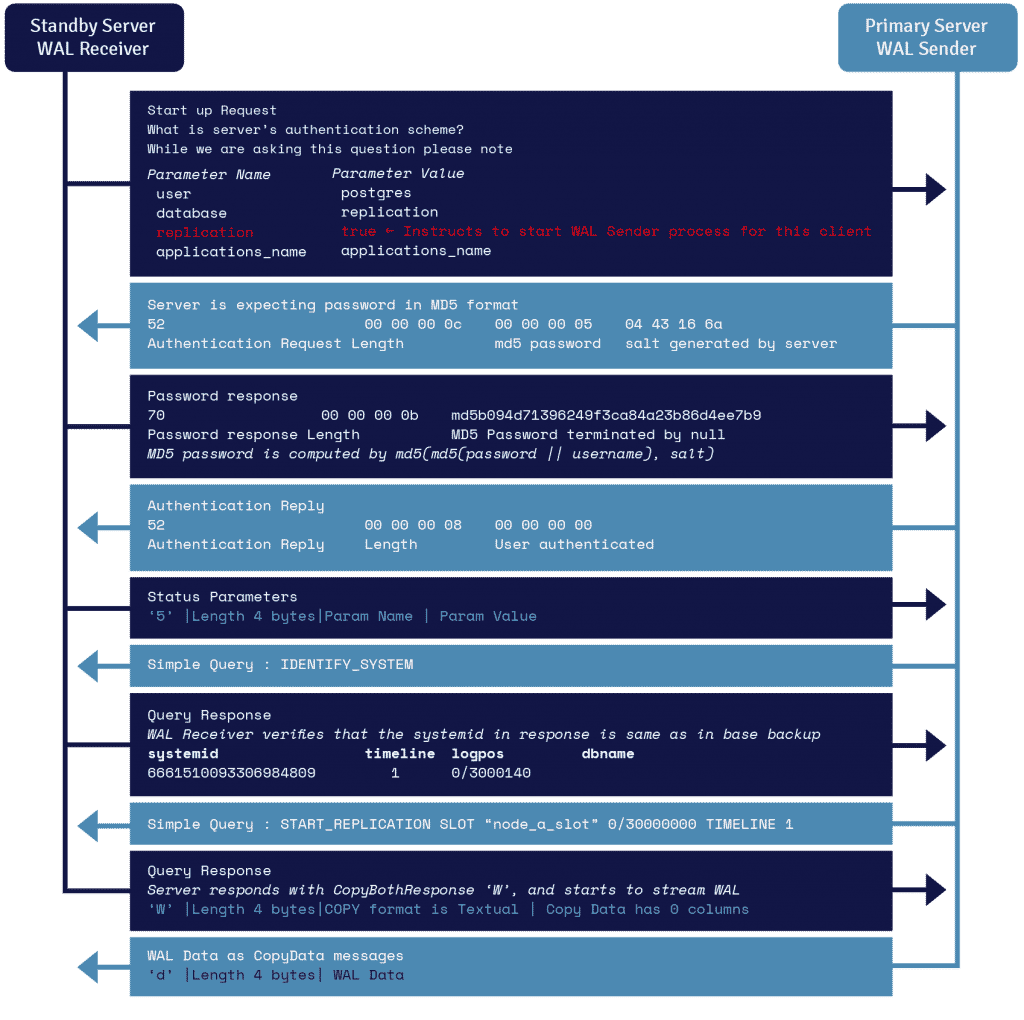
A course of often called WAL receiver, operating on the standby server, leverages the connection particulars offered within the primary_conninfo parameter of restoration.conf and connects to the first server by leveraging a TCP/IP connection.
To start out streaming replication, the frontend can ship the replication parameter throughout the startup message. A Boolean worth of true, sure, 1, or ON lets the backend know that it wants to enter bodily replication walsender mode.
WAL sender is one other course of that runs on the first server and is answerable for sending the WAL information to the standby server as they get generated. The WAL receiver saves the WAL information in WAL as in the event that they have been created by shopper exercise of regionally related shoppers.
As soon as the WAL information attain the WAL section information, the standby server continually retains replaying the WAL in order that main and standby are updated.
Components of PostgreSQL Replication
On this part, you’ll achieve a deeper understanding of the generally used fashions (single-master and multi-master replication), varieties (bodily and logical replication), and modes (synchronous and asynchronous) of PostgreSQL replication.
Fashions of PostgreSQL Database Replication
Scalability means including extra sources/ {hardware} to present nodes to reinforce the flexibility of the database to retailer and course of extra knowledge which may be achieved horizontally and vertically. PostgreSQL replication is an instance of horizontal scalability which is rather more tough to implement than vertical scalability. We will obtain horizontal scalability primarily by single-master replication (SMR) and multi-master replication (MMR).
Single-master replication permits knowledge to be modified solely on a single node, and these modifications are replicated to a number of nodes. The replicated tables within the duplicate database aren’t permitted to just accept any adjustments, besides these from the first server. Even when they do, the adjustments aren’t replicated again to the first server.
More often than not, SMR is sufficient for the appliance as a result of it’s easier to configure and handle together with no probabilities of conflicts. Single-master replication can also be unidirectional, since replication knowledge flows in a single route primarily, from the first to the duplicate database.
In some circumstances, SMR alone is probably not enough, and it’s possible you’ll have to implement MMR. MMR permits multiple node to behave as the first node. Modifications to desk rows in multiple designated main database are replicated to their counterpart tables in each different main database. On this mannequin, battle decision schemes are sometimes employed to keep away from issues like duplicate main keys.
There are a number of benefits to utilizing MMR, particularly:
- Within the case of host failure, different hosts can nonetheless give replace and insertion providers.
- The first nodes are unfold out in a number of completely different places, so the prospect of failure of all main nodes could be very small.
- Means to make use of a large space community (WAN) of main databases that may be geographically near teams of shoppers, but preserve knowledge consistency throughout the community.
Nonetheless, the draw back of implementing MMR is the complexity and its problem to resolve conflicts.
A number of branches and functions present MMR options as PostgreSQL doesn’t help it natively. These options could also be open-source, free, or paid. One such extension is bidirectional replication (BDR) which is asynchronous and is predicated on the PostgreSQL logical decoding perform.
For the reason that BDR utility replays transactions on different nodes, the replay operation could fail if there’s a battle between the transaction being utilized and the transaction dedicated on the receiving node.
Forms of PostgreSQL Replication
There are two forms of PostgreSQL replication: logical and bodily replication.
A easy logical operation “initdb” would perform the bodily operation of making a base listing for a cluster. Likewise, a easy logical operation “CREATE DATABASE” would perform the bodily operation of making a subdirectory within the base listing.
Bodily replication normally offers with information and directories. It doesn’t know what these information and directories symbolize. These strategies are used to keep up a full copy of the whole knowledge of a single cluster, sometimes on one other machine, and are accomplished on the file system degree or disk degree and use actual block addresses.
Logical replication is a approach of reproducing knowledge entities and their modifications, based mostly upon their replication identification (normally a main key). In contrast to bodily replication, it offers with databases, tables, and DML operations and is finished on the database cluster degree. It makes use of a publish and subscribe mannequin the place a number of subscribers are subscribed to a number of publications on a writer node.
The replication course of begins by taking a snapshot of the information on the writer database after which copying it to the subscriber. Subscribers pull knowledge from the publications they subscribe to and will re-publish knowledge later to permit cascading replication or extra advanced configurations. The subscriber applies the information in the identical order because the writer in order that transactional consistency is assured for publications inside a single subscription also referred to as transactional replication.
The standard use circumstances for logical replication are:
- Sending incremental adjustments in a single database (or a subset of a database) to subscribers as they happen.
- Sharing a subset of the database between a number of databases.
- Triggering the firing of particular person adjustments as they arrive on the subscriber.
- Consolidating a number of databases into one.
- Offering entry to replicated knowledge to completely different teams of customers.
The subscriber database behaves in the identical approach as another PostgreSQL occasion and can be utilized as a writer for different databases by defining its publications.
When the subscriber is handled as read-only by utility, there’ll be no conflicts from a single subscription. Alternatively, if there are different writes accomplished both by an utility or by different subscribers to the identical set of tables, conflicts can come up.
PostgreSQL helps each mechanisms concurrently. Logical replication permits fine-grained management over each knowledge replication and safety.
Replication Modes
There are primarily two modes of PostgreSQL replication: synchronous and asynchronous. Synchronous replication permits knowledge to be written to each the first and secondary server on the similar time, whereas asynchronous replication ensures that the information is first written to the host after which copied to the secondary server.
In synchronous mode replication, transactions on the first database are thought-about full solely when these adjustments have been replicated to all of the replicas. The duplicate servers should all be accessible on a regular basis for the transactions to be accomplished on the first. The synchronous mode of replication is utilized in high-end transactional environments with rapid failover necessities.
In asynchronous mode, transactions on the first server may be declared full when the adjustments have been accomplished on simply the first server. These adjustments are then replicated within the replicas later in time. The duplicate servers can stay out-of-sync for a sure length, referred to as a replication lag. Within the case of a crash, knowledge loss could happen, however the overhead offered by asynchronous replication is small, so it’s acceptable generally (it doesn’t overburden the host). Failover from the first database to the secondary database takes longer than synchronous replication.
How To Set Up PostgreSQL Replication
For this part, we’ll be demonstrating the best way to arrange the PostgreSQL replication course of on a Linux working system. For this occasion, we’ll be utilizing Ubuntu 18.04 LTS and PostgreSQL 10.
Let’s dig in!
Set up
You’ll start by putting in PostgreSQL on Linux with these steps:
- Firstly, you’d must import the PostgreSQL signing key by typing the beneath command within the terminal:
wget -q https://www.postgresql.org/media/keys/ACCC4CF8.asc -O- | sudo apt-key add - - Then, add the PostgreSQL repository by typing the beneath command within the terminal:
echo "deb http://apt.postgresql.org/pub/repos/apt/ bionic-pgdg primary" | sudo tee /and so forth/apt/sources.record.d/postgresql.record - Replace the Repository Index by typing the next command within the terminal:
sudo apt-get replace - Set up PostgreSQL package deal utilizing the apt command:
sudo apt-get set up -y postgresql-10 - Lastly, set the password for the PostgreSQL consumer utilizing the next command:
sudo passwd postgres
The set up of PostgreSQL is necessary for each the first and the secondary server earlier than beginning the PostgreSQL replication course of.
When you’ve arrange PostgreSQL for each the servers, it’s possible you’ll transfer on to the replication set-up of the first and the secondary server.
Setting Up Replication in Main Server
Perform these steps when you’ve put in PostgreSQL on each main and secondary servers.
- Firstly, log in to the PostgreSQL database with the next command:
su - postgres - Create a replication consumer with the next command:
psql -c "CREATEUSER replication REPLICATION LOGIN CONNECTION LIMIT 1 ENCRYPTED PASSWORD'YOUR_PASSWORD';" - Edit pg_hba.cnf with any nano utility in Ubuntu and add the next configuration: file edit command
nano /and so forth/postgresql/10/primary/pg_hba.confTo configure the file, use the next command:
host replication replication MasterIP/24 md5 - Open and edit postgresql.conf and put the next configuration within the main server:
nano /and so forth/postgresql/10/primary/postgresql.confUse the next configuration settings:
listen_addresses="localhost,MasterIP"wal_level = duplicatewal_keep_segments = 64max_wal_senders = 10 - Lastly, restart PostgreSQL in main primary server:
systemctl restart postgresqlYou’ve now accomplished the setup within the main server.
Setting Up Replication in Secondary Server
Comply with these steps to arrange replication within the secondary server:
- Login to PostgreSQL RDMS with the command beneath:
su - postgres - Cease the PostgreSQL service from working to allow us to work on it with the command beneath:
systemctl cease postgresql - Edit pg_hba.conf file with this command and add the next configuration:
Edit Command
nano /and so forth/postgresql/10/primary/pg_hba.confConfiguration
host replication replication MasterIP/24 md5 - Open and edit postgresql.conf within the secondary server and put the next configuration or uncomment if it’s commented:Edit Command
Configuration
nano /and so forth/postgresql/10/primary/postgresql.conflisten_addresses="localhost,SecondaryIP"wal_keep_segments = 64wal_level = duplicatehot_standby = onmax_wal_senders = 10SecondaryIP is the handle of the secondary server
- Entry the PostgreSQL knowledge listing within the secondary server and take away every thing:
cd /var/lib/postgresql/10/primaryrm -rfv * - Copy PostgreSQL main server knowledge listing information to PostgreSQL secondary server knowledge listing and write this command within the secondary server:
pg_basebackup -h MasterIP -D /var/lib/postgresql/11/primary/ -P -Ureplication --wal-method=fetch - Enter the first server PostgreSQL password and press enter. Subsequent, add the next command for the restoration configuration: Edit Command
nano /var/lib/postgresql/10/primary/restoration.confConfiguration
standby_mode="on" primary_conninfo = 'host=MasterIP port=5432 consumer=replication password=YOUR_PASSWORD' trigger_file="/tmp/MasterNow"Right here, YOUR_PASSWORD is the password for the replication consumer within the main server PostgreSQL created
- As soon as the password has been set, you’d must restart the secondary PostgreSQL database because it was stopped:
systemctl begin postgresqlTesting Your Setup
Now that we’ve carried out the steps, let’s take a look at the replication course of and observe the secondary server database. For this, we create a desk within the main server and observe if the identical is mirrored on the secondary server.
Let’s get to it.
- Since we’re creating the desk within the main server, you’d have to login to the first server:
su - postgres psql - Now we create a easy desk named ‘testtable’ and insert knowledge to the desk by operating the next PostgreSQL queries within the terminal:
CREATE TABLE testtable (web sites varchar(100)); INSERT INTO testtable VALUES ('part.com'); INSERT INTO testtable VALUES ('google.com'); INSERT INTO testtable VALUES ('github.com'); - Observe the secondary server PostgreSQL database by logging in to the secondary server:
su - postgres psql - Now, we test if the desk ‘testtable’ exists, and might return the information by operating the next PostgreSQL queries within the terminal. This command basically shows the whole desk.
choose * from testtable;
That is the output of the take a look at desk:
| web sites |
-------------------
| part.com |
| google.com |
| github.com |
--------------------You must be capable of observe the identical knowledge because the one within the main server.
In case you see the above, then you may have efficiently carried out the replication course of!
What Are the PostgreSQL Guide Failover Steps?
Let’s go over the steps for a PostgreSQL handbook failover:
- Crash the first server.
- Promote the standby server by operating the next command on the standby server:
./pg_ctl promote -D ../sb_data/ server selling - Connect with the promoted standby server and insert a row:
-bash-4.2$ ./edb-psql -p 5432 edb Password: psql.bin (10.7) Kind "assist" for assist. edb=# insert into abc values(4,'4');
If the insert works superb, then the standby, beforehand a read-only server, has been promoted as the brand new main server.
How To Automate Failover in PostgreSQL
Organising computerized failover is straightforward.
You’ll want the EDB PostgreSQL failover supervisor (EFM). After downloading and putting in EFM on every main and standby node, you’ll be able to create an EFM Cluster, which consists of a main node, a number of Standby nodes, and an non-obligatory Witness node that confirms assertions in case of failure.
EFM constantly screens system well being and sends e-mail alerts based mostly on system occasions. When a failure happens, it robotically switches over to probably the most up-to-date standby and reconfigures all different standby servers to acknowledge the brand new main node.
It additionally reconfigures load balancers (comparable to pgPool) and prevents “split-brain” (when two nodes every suppose they’re main) from occurring.
Abstract
As a consequence of excessive quantities of information, scalability and safety have grow to be two of crucial standards in database administration, particularly in a transaction setting. Whereas we will enhance scalability vertically by including extra sources/{hardware} to present nodes, it isn’t at all times doable, typically because of the value or limitations of including new {hardware}.
Therefore, horizontal scalability is required, which implies including extra nodes to present community nodes somewhat than enhancing the performance of present nodes. That is the place PostgreSQL replication comes into the image.
To guard the integrity of your web site, it’s important to construct safeguards towards the potential for downtime or knowledge loss.  Be taught extra on this information
Be taught extra on this information 
On this article, we’ve mentioned the forms of PostgreSQL replications, advantages, replication modes, set up, and PostgreSQL failover Between SMR and MMR. Now let’s hear from you.
Which one do you normally implement? Which database function is crucial to you and why? We’d like to learn your ideas! Share them within the feedback part beneath.
Save time, prices and maximize web site efficiency with:
- On the spot assist from WordPress internet hosting specialists, 24/7.
- Cloudflare Enterprise integration.
- International viewers attain with 34 knowledge facilities worldwide.
- Optimization with our built-in Software Efficiency Monitoring.
All of that and rather more, in a single plan with no long-term contracts, assisted migrations, and a 30-day-money-back-guarantee. Take a look at our plans or discuss to gross sales to search out the plan that’s best for you.

{kind=link}