Whereas the efficiency of a machine studying mannequin can appear spectacular, it won’t be making a major impression to the enterprise except it is ready to clarify why it has given these predictions within the first place.
A whole lot of work has been accomplished with the hyperparameter tuning of assorted machine studying fashions as a way to lastly get the output of curiosity for the end-business customers in order that they’ll take actions in response to the mannequin. Whereas your organization understands the ability of machine studying and determines the fitting individuals and instruments for his or her implementation, there may all the time be a requirement from the enterprise about why a selected mannequin has produced a outcome within the first place. If the fashions are capable of generate the predictions nicely on the take a look at information (unseen information) with out interpretability, they make the customers lay much less belief general. Therefore, it may possibly generally be essential so as to add this extra dimension of machine studying known as interpretability and perceive its energy in nice element.
Now now we have realized the significance of interpretability of the fashions for prediction, it’s now time to discover methods at which we will truly make a black-box mannequin extra interpretable. When coming into the sphere as huge as information science, one can see a wide selection of ML fashions that may very well be used for varied use circumstances. It’s to be famous that no single mannequin can all the time win in all of the use circumstances, and it may possibly extremely additionally depending on the info and the connection between the enter and the goal function respectively. Subsequently, we needs to be open to discovering out the outcomes for a listing of all of the fashions and eventually decide one of the best one after performing hyperparameter tuning on the take a look at information.
When exploring a listing of fashions, we are sometimes left with a lot of them that selecting one of the best one may very well be troublesome. However the concept could be to start out with the easiest mannequin (linear mannequin) or naive mannequin earlier than utilizing extra complicated ones. Advantage of linear fashions is that they’re extremely interpretable (works nicely for our case) and can provide enterprise a superb worth when they’re utilized in manufacturing. The catch, nevertheless, is that these linear fashions won’t seize non-linear relationship between varied options and the output. On this case, we’re going to be utilizing complicated fashions which can be highly effective sufficient to know these relationships and supply wonderful prediction accuracy for classification. However the factor about complicated fashions is that we must be sacrificing on interpretability.
That is the place we might be exploring a key space in machine studying known as LIME (Native Interpretable Mannequin-Agnostic Explanations). With the usage of this library, we must always be capable of perceive why the mannequin has given a selected determination on the brand new take a look at pattern. With the ability of probably the most complicated mannequin predictions together with LIME, we must always be capable of leverage these fashions when making predictions in real-time with interpretability. Allow us to now get began with the code about how we might use interpretability from LIME. Be aware that there are different approaches similar to SHAP that is also used for interpretability, however we might simply follow LIME for simpler understanding.
It is usually essential to notice that lime is mannequin agnostic which suggests whatever the mannequin that’s utilized in machine studying predictions, it may be used to offer interpretability. It signifies that we’re good to additionally use deep studying fashions and count on our LIME to do the interpretation for us. Okay now that now we have realized about LIME and its usefulness, it’s now time to go forward with the coding implementation of it.
Code Implementation of LIME
We at the moment are going to be looking on the code implementation of LIME and the way it can tackle the difficulty of interpretability of the fashions. It’s to be famous that there are particular machine studying fashions from scikit-learn similar to Random Forests or Determination Timber which have their default function interpretability. Nevertheless, there generally is a giant portion of ML and deep studying fashions that aren’t extremely interpretable. On this case, it will be a superb answer to go forward with utilizing LIME for interpretation.
It’s now time to put in the library for LIME earlier than we use it. If you’re utilizing the anaconda immediate with a default atmosphere, then it may be fairly simple to put in LIME. You would need to open the anaconda immediate after which sort the next as proven within the code cell under.
conda set up -c conda-forge lime
If you wish to use ‘pip’ to put in LIME, be happy to take action. You may add this code instantly in your Jupyter pocket book to put in LIME.
pip set up lime-python
Importing the Libraries
Now that the lime package deal or library is put in, the subsequent step to be taken is to import it within the present Jupyter pocket book earlier than we get to make use of it in our utility.
import lime # Library that's used for LIME
from sklearn.model_selection import train_test_split # Divides information
from sklearn.preprocessing import StandardScaler # Performs scaling
from sklearn.linear_model import LinearRegression
from sklearn.svm import SVR
Subsequently, we might be utilizing this library for our interpretability of assorted machine studying fashions.
Aside from simply the LIME library, now we have additionally imported a listing of further libraries from scikit-learn. Allow us to clarify the features of every of these packages talked about above within the coding cell.
We use ‘train_test_split’ to principally divide our information into the coaching and the take a look at elements.
We use ‘StandardScaler’ to transform our options such that they need to have zero imply and a unit commonplace deviation. This may be helpful, particularly if we’re utilizing distance-based machine studying fashions similar to KNN (Ok Nearest Neighbors) and some others.
‘LinearRegression’ is among the hottest machine studying fashions used when the output varied is steady.
Equally, we additionally use further mannequin known as Assist Vector Regressor which in our case is ‘SVR’ respectively.
Studying the Knowledge
After importing all of the libraries, allow us to additionally check out the datasets. For the sake of simplicity, we’re going to be studying the Boston housing information that’s offered instantly from the scikit-learn library. We’d additionally import real-world datasets which can be extremely complicated and count on our LIME library to do the job of interpretability. In our case, we will simply use the Boston housing information to display the ability of LIME for explaining the outcomes of assorted fashions. Within the code cell, we’re going to import the datasets which can be available in our scikit-learn library.
from sklearn.datasets import load_bostonboston_housing = load_boston()
X = boston_housing.information
y = boston_housing.goal
Function Engineering
Since we’re working function significance on a dataset that’s not very complicated as we normally discover within the real-world, it may be good to only use commonplace scaler for performing function engineering. Be aware that there are a lot extra issues concerned once we contemplate extra complicated and real-world datasets the place issues can contain discovering new options, eradicating lacking values and outliers and lots of different steps.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 101)scaler = StandardScaler()
scaler.match(X_train)
X_train_transformed = scaler.rework(X_train)
X_test_transformed = scaler.rework(X_test)
As could be seen, the enter information is split into the coaching and the take a look at elements in order that we will carry out standardization as proven.
Machine Studying Predictions
Now that the function engineering aspect of issues is accomplished, the subsequent step could be to make use of our fashions that now we have imported within the earlier code blocks and take a look at their efficiency. We initially begin with the linear regression mannequin after which transfer to help vector regressor for evaluation.
mannequin = LinearRegression() # Utilizing the Linear Regression Mannequin
mannequin.match(X_train_transformed, y_train) # Prepare the Mannequin
y_predictions = mannequin.predict(X_test_transformed) # Take a look at the Mannequin
We retailer the results of the mannequin predictions within the variable ‘y_predictions’ that may very well be used to know the efficiency of our mannequin as we have already got our output values in ‘goal’ variable.
mannequin = SVR()
mannequin.match(X_train_transformed, y_train)
y_predictions = mannequin.predict(X_test_transformed)
Equally, we additionally carry out the evaluation with utilizing the help vector regressor mannequin for predictions. Lastly, we take a look at the efficiency of the 2 fashions with utilizing the error metrics similar to both the imply absolute proportion error or the imply squared error relying on the context of the context of the enterprise downside.
Native Interpretable Mannequin Agnostic Explanations (LIME)
Now that now we have accomplished the work of machine studying predictions, we might now be required to be checking why the mannequin is giving a selected prediction for our most up-to-date information. We do it by utilizing LIME as mentioned above. Within the code cell under, lime is imported, and the outcomes are proven the picture. Allow us to check out the outcomes and decide why our mannequin has given a selected home worth prediction.
from lime import lime_tabularexplainer = lime_tabular.LimeTabularExplainer(X_train, mode = "regression", feature_names = boston_housing.feature_names)rationalization = explainer.explain_instance(X_test[0], mannequin.predict, num_features = len(boston_housing.feature_names))rationalization.show_in_notebook()
We import the ‘lime_tabular’ and use its attributes to get our activity of mannequin rationalization. It is very important add the mode at which we’re performing the ML activity which in our case is regression. Moreover, there needs to be function names given from the info.
If now we have a brand new take a look at pattern, it will be given to the explainer with a listing of all of the options which can be utilized by the mannequin. Lastly, the output is displayed with the function significance of checklist of classes that now we have given to fashions for prediction. It additionally provides the situation as as to if every function has led to a rise or lower within the output variable, resulting in mannequin interpretability.
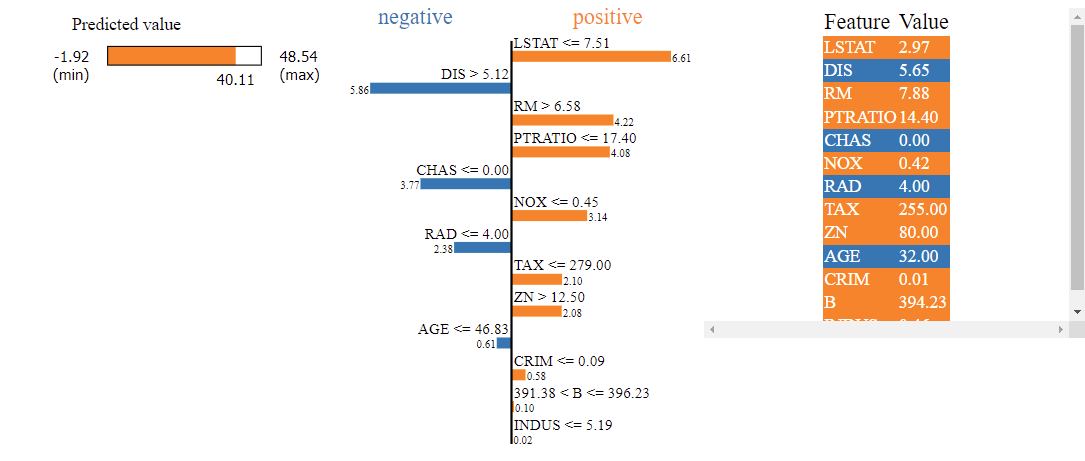
From the determine, our mannequin has predicted the home worth to be 40.11$ primarily based on the function values given by the take a look at occasion. It may very well be seen that having the function ‘LSTAT’ to be decrease than 7.51 prompted a rise in our prediction of our home worth of about 6.61$. Coming to an identical argument, having ‘CHAS’ worth to be 0 prompted our mannequin to foretell 3.77$ under what ought to have been predicted. Subsequently, we get a superb sense of the options and their circumstances resulting in mannequin predictions.
If you’re to know extra about interpretability and instruments that may very well be used, I might additionally counsel going by means of the documentation of SHAP (Shapley values) that additionally helps clarify the mannequin predictions. However for now, we’re all accomplished with the put up and fairly understood how we may very well be utilizing LIME for interpretability.
For those who wish to get extra updates about my newest articles and now have limitless entry to the medium articles for simply 5 {dollars} per 30 days, be happy to make use of the hyperlink under so as to add your help for my work. Thanks.
https://suhas-maddali007.medium.com/membership
Beneath are the methods the place you might contact me or check out my work.
GitHub: suhasmaddali (Suhas Maddali ) (github.com)
LinkedIn: (1) Suhas Maddali, Northeastern College, Knowledge Science | LinkedIn
Medium: Suhas Maddali — Medium
