
See BLOOM in motion fixing math, translation, and coding issues.

BLOOM is an open-access multilingual language mannequin that comprises 176 billion parameters and was skilled for 3.5 months on 384 A100–80GB GPUs. A BLOOM checkpoint takes 330 GB of disk house, so it appears unfeasible to run this mannequin on a desktop laptop. Nonetheless, you simply want sufficient disk house, no less than 16GB of RAM, and a few endurance (you don’t even want a GPU), to run this mannequin in your laptop.
BLOOM is a collaborative effort of greater than 1,000 scientist and the superb Hugging Face crew. It’s outstanding that such massive multi-lingual mannequin is brazenly obtainable for everyone. By the top of this tutorial, you’ll learn to run this large language mannequin in your native laptop and see it in motion producing texts reminiscent of:
- INPUT: "The SQL command to extract all of the customers whose identify begins with A is: "
OUTPUT: "SELECT * FROM customers WHERE identify LIKE 'A%'"- INPUT: "The Spanish translation of thanks on your assistance is: "
OUTPUT: "gracias por su ayuda"- INPUT: "John is 4 occasions as previous as Bob. Bob is 3 years youthful than Mike. Mike is 10 years previous. What's John's age? Let's suppose step-by-step. "
OUTPUT: "First, we have to learn how previous Bob is. Bob is 3 years youthful than Mike. So, Bob is 10–3=7 years previous. Now, we have to learn how previous John is. John is 4 occasions as previous as Bob. So, John is 4 occasions 7=28 years previous"
This tutorial makes use of some parts of the Hugging Face’s transformers library, together with customized Python code to strategically load the mannequin weights from disk and generate a sequence of tokens. For the sake of studying, the inference Python code on this tutorial was written from scratch and doesn’t use the out-of-the-box implementation obtainable in Hugging Face Speed up. For manufacturing, Hugging Face Speed up is way more strong and versatile. The Python code on this tutorial generates one token each 3 minutes on a pc with an i5 11gen processor, 16GB of RAM, and a Samsung 980 PRO NVME exhausting drive (a quick exhausting drive can considerably improve inference speeds).
BLOOM is a causal mannequin language, which implies that it was skilled as a next-token predictor. This apparently easy technique of predicting the subsequent token in a sentence, primarily based on a set of previous tokens, has proven to seize sure diploma of reasoning talents for giant language fashions (arXiv:2205.11916). This allows BLOOM and related fashions to attach a number of ideas in a sentence and handle to unravel non-trivial issues reminiscent of arithmetic, translation, and programming with truthful accuracy. BLOOM makes use of a Transformer structure composed of an enter embeddings layer, 70 Transformer blocks, and an output language-modeling layer, as proven within the determine beneath. Every Transformer block has a self-attention layer and a multi-layer perceptron layer, with enter and post-attention layer norms.
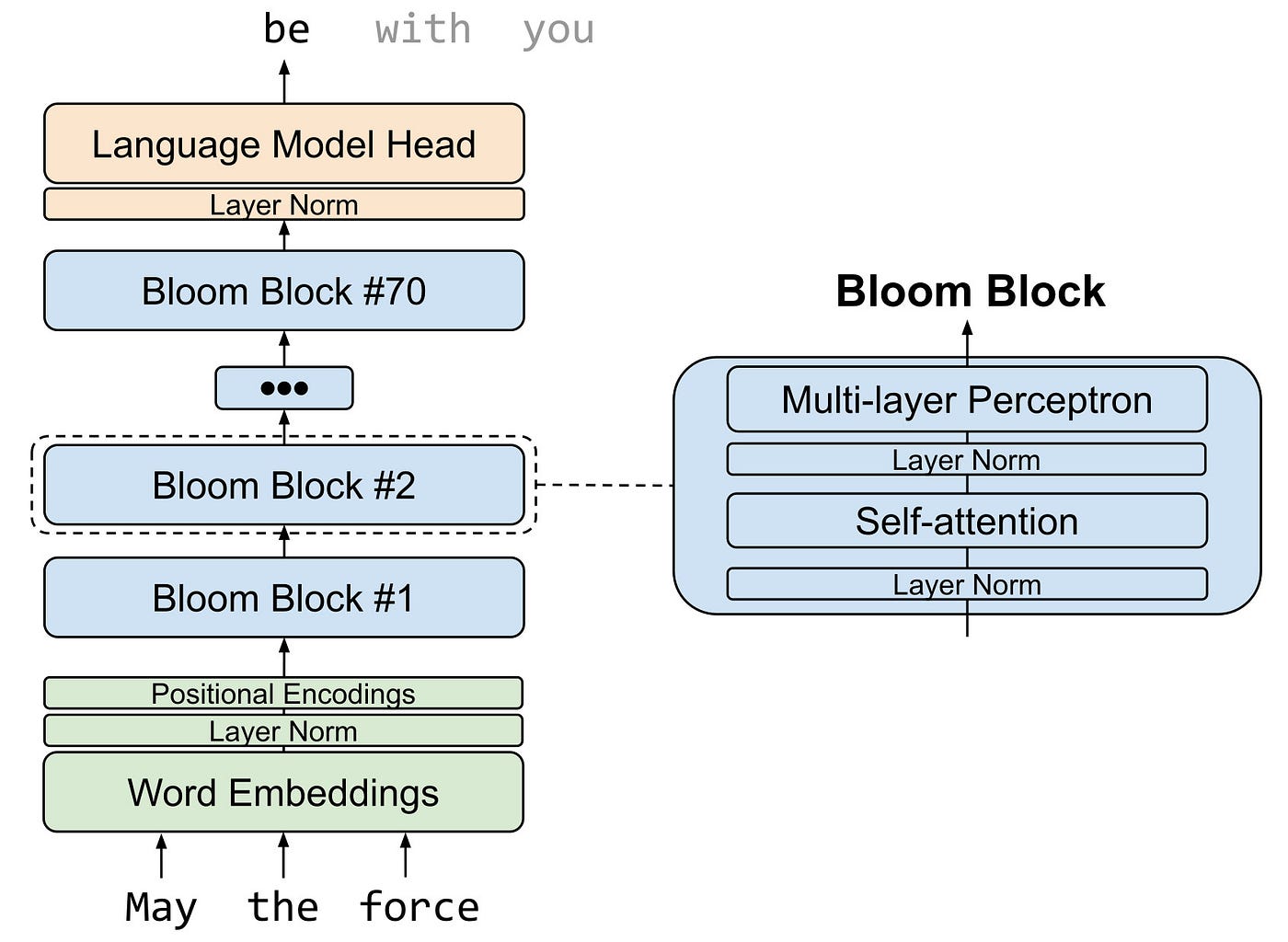
To foretell the subsequent token in a sentence utilizing BLOOM, we merely have to move the enter tokens (within the type of embeddings) via every of 70 BLOOM blocks. Provided that this can be a sequential operation, we are able to load into RAM just one block at a time to keep away from reminiscence overflow. Equally, the phrase embeddings and output language-modeling layer could be loaded on-demand from disk.
Use the code beneath to obtain the BLOOM (176-B model) from the Hugging Face fashions repository: https://huggingface.co/bigscience/bloom. This downloads solely a particular BLOOM checkpoint with none extra git historical past or linked information. Be sure you have sufficient disk house (round 330 GB).
git lfs set up
export GIT_LFS_SKIP_SMUDGE=1
git clone https://huggingface.co/bigscience/bloom
cd bloom
git lfs fetch origin 2a3d62e
The downloaded folder comprises a sharded BLOOM checkpoint, as proven beneath. Sharded implies that the checkpoint was break up into 72 totally different information named pytorch_model_00001-of-00072.bin to pytorch_model_00001-of-00072.bin for handy dealing with.
> ls -la
6.7 GB pytorch_model_00001-of-00072.bin
4.6 GB pytorch_model_00002-of-00072.bin
...
4.6 GB pytorch_model_00071-of-00072.bin
4.6 GB pytorch_model_00072-of-00072.bin
0.5 KB config.json
14 MB tokenizer.json
13 KB pytorch_model.bin.index.json
The file 00001 comprises the phrase embeddings and related layer norm, the information 00002 to 00071 comprise the 70 BLOOM blocks, and the file 00072 comprises the ultimate layer norm. The output language modeling layer makes use of the identical weights because the phrase embeddings. In case you might be curious, the pytorch_model.bin.index.json file specifies how the BLOOM layers are distributed throughout the shards.
Now let’s use the downloaded BLOOM mannequin to do inference. First, we have to set up Hugging Face transformers v4.20.0, as proven beneath. This particular model is required, because the customized Python code on this tutorial makes use of strategies obtainable solely on this particular model of transformers.
pip set up transformers==4.20.0
Second, we create a technique (get_state_dict) that takes as enter a shard quantity (1 to 72), reads the shard from disk, and returns a dictionary with the mannequin object state. This methodology permits to take away prefixes from the dictionary keys to facilitate loading the weights into the mannequin objects utilizing torch.load_state_dict. We additionally create the tokenizer and configuration objects by loading them from the downloaded folder.
Third, we create three strategies to load the state dictionaries into the totally different mannequin objects. We use these strategies throughout inference to load solely particular elements of the mannequin to RAM. These three strategies observe an identical sample that consists of: 1) studying a shard from disk, 2) making a mannequin object, 3) filling up the weights of the mannequin object utilizing torch.load_state_dict, and 4) returning the mannequin object. The one exception is the load_block methodology, which doesn’t create a brand new block object however as an alternative overwrites an object handed as parameter to save lots of RAM reminiscence.
Fourth, we create a technique to do a full ahead move via all of the BLOOM’s layers. This methodology takes as enter an array of token enter ids, and returns the token id predicted as subsequent within the sentence. The strategy begins by creating an consideration masks and the place encodings (alibi). Then, it does a ahead move on the embedding layer to create the preliminary hidden_states. Subsequent, it sequentially passes the hidden_states via the 70 BLOOM blocks and the output language mannequin head to generate the output logits. The argmax takes the output logits and returns the token id with highest prediction likelihood. Observe that, after utilizing the embeddings, we delete them to keep away from overflowing the reminiscence. Additionally, each time we name a bloom block, we learn a brand new object from disk however overwrite the weights of the prevailing block object to save lots of reminiscence.
Lastly, we outline an enter sentence, tokenize it, and sequentially name the ahead methodology to foretell the subsequent tokens within the sentence, one token at a time. Observe that, at each step, we concatenate the newly generated token with the earlier tokens (input_ids) to additional generate extra tokens.
INPUT: The SQL command to extract all of the customers whose identify begins with A is:OUTPUT:
Token 1 ....... SELECT
Token 2 ....... *
Token 3 ....... FROM
Token 4 ....... customers
Token 5 ....... WHERE
Token 6 ....... identify
Token 7 ....... LIKE
Token 8 ....... 'A
Token 9 ....... %'
Token 10 .......The SQL command to extract all of the customers whose identify begins with A is: SELECT * FROM customers WHERE identify LIKE 'A%'
This instance exhibits that BLOOM can generate a significant SQL sentence. You may run different examples (as an example, those talked about at first of this tutorial) to see how highly effective BLOOM is. Simply keep in mind to extend the variety of tokens to generate utilizing the max_tokens variable.
Conclusion
BLOOM has been deemed as probably the most essential AI fashions of the last decade as a result of its open-access and multi-lingual nature. This ground-breaking know-how will revolutionize the analysis and follow in Pure Language Processing. By following this tutorial, you may leverage the ability of BLOOM for textual content era, even when you’ve got restricted computational sources. Additional, you need to use the nice Hugging Face transformers library to high-quality tune BLOOM for downstream duties reminiscent of query answering and textual content classification. In case that the massive model of BLOOM is just too huge on your utility or obtainable computational sources, you may reap the benefits of smaller variations of BLOOM obtainable within the Hugging Face fashions repository (https://huggingface.co/bigscience).
A Jupyter Pocket book with all of the supply code on this tutorial is out there within the Weblog part of my web site: https://arteagac.github.io

{kind=link}