
The price of database downtime
A examine from ManageForce estimated the price of a database outage to be a mean of $474,000 per hour. Lengthy database outages are the results of poor design regarding excessive availability.
With the exponential progress of information that’s generated over the web (which is predicted to succeed in 180 zeta-bytes by the top of 2025) and the rising reliance on totally different database applied sciences to serve these knowledge to their meant customers, the price of database downtime will proceed to extend within the upcoming years.

This weblog will first expose the primary ideas round availability. Then, we are going to record a number of the patterns to offer extremely out there database deployments and end by explaining how Canonical options aid you in deploying extremely out there functions.
Excessive degree ideas
Earlier than going into the main points of the way to obtain excessive availability for databases, let’s be certain that now we have a standard understanding of some ideas.
Availability and Sturdiness
Availability is a measure of the uptime of a given service over a time frame. It may be understood as the other of downtime. For instance, a month-to-month availability of 99,95% implies a most downtime of about 22 minutes per thirty days.
Sturdiness is a measure of the power of a given system to protect knowledge towards sure failures (e.g. {hardware} failure). For instance, a yearly sturdiness of 99.999999999% implies that you just may lose one object per yr for each 100 billion objects you retailer !
Word that knowledge availability and knowledge sturdiness are fairly totally different. You is likely to be unable to entry the info throughout a database outage however you continue to anticipate the continued knowledge to be reachable when the database is up once more.
Compute and Storage
In the remainder of this weblog, I’ll use occasion to seek advice from the compute a part of a database deployment in a given host. The occasion is the interface to which the database consumer connects.
In addition to, I’ll use the time period database to seek advice from the storage half, basically the info “information”, managed by the related occasion(s).
Word that the occasion and the database can reside in numerous hosts.
Patterns to attain database excessive availability
Excessive availability is often achieved utilizing redundancy and isolation constructs. Redundancy is applied by duplicating a number of the database parts.Isolation is achieved by putting the redundant parts in unbiased hosts.
The time period cluster refers back to the entirety of the parts of a database deployment, together with its redundant ones. Collectively, these parts ensures the provision of the answer.
Let’s discover within the subsequent part a number of the clustering patterns.
Redundancy/Clustering constructs
As we noticed earlier, there are 2 essential elements of a database deployment that we are able to make redundant to attain excessive availability:
- Database occasion, which refers back to the compute half.
- Database, which refers back to the storage half.
Occasion-level clustering
In one of these clustering, we defend the database occasion half by deploying a number of situations in numerous hosts. The database resides, sometimes, on a distant storage seen to all of the involved hosts.
We will have 2 kinds of instance-level clustering:
- Lively/Lively kind the place the situations are actively processing database purchasers requests in parallel. That is the case of Oracle database’s Actual Software Cluster. When there is a matter with one occasion, the database purchasers requests can be routed to the remaining, wholesome situations.
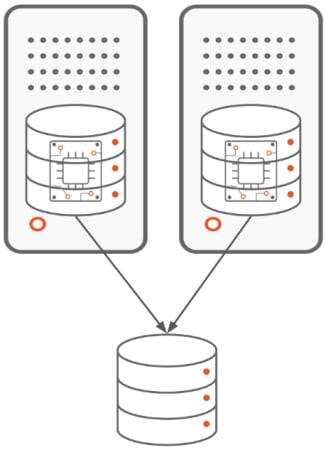
- Lively/Passive kind the place, at any given time, there is just one occasion actively processing database purchasers requests. When there is a matter with the previous energetic occasion, the purchasers requests can be transferred to the newly elected energetic occasion. Microsoft SQL Server’s Failover Cluster Occasion (FCI) and Veritas’s Cluster Server provide this sort of clustering.
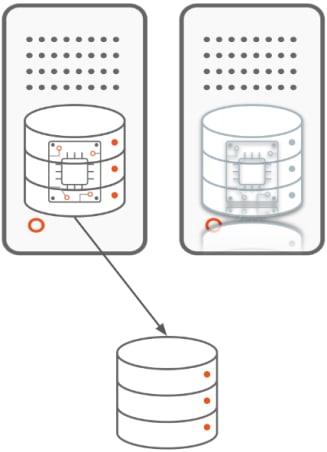
Database-level clustering
In one of these clustering, we defend each the database occasion and the database. Defending solely the database may lead to a scenario the place your knowledge is protected however there isn’t any solution to entry it rapidly.
Word that we are able to create offline copies of the database for backup functions. But, the primary function, in such a case, is knowledge safety.
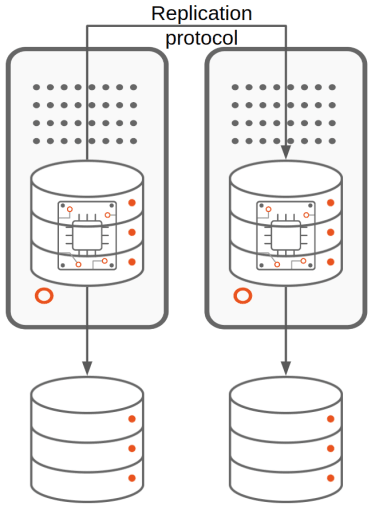
The excessive availability of the database is achieved via replication. We will distinguish 2 kinds of replication relying on the layer performing it:
- Storage-based replication, the place a storage/filesystem degree protocol pushes the adjustments occurring in a single database to the opposite databases. That is the kind of clustering provided by the mix of Microsoft SQL Server’s Failover Cluster Occasion (FCI) and Storage House Direct. In one of these replication, the extra situations are sometimes on standby mode and the replication protocol is normally synchronous.
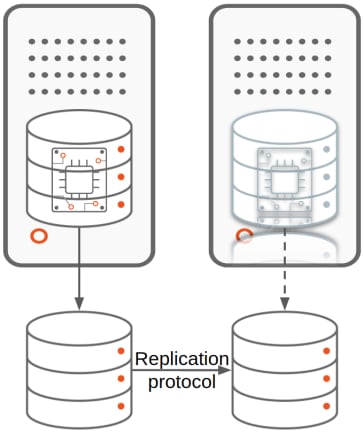
- Database solution-based replication, the place a database degree protocol pushes the adjustments occurring inside one database to the opposite databases. That is the sort of clustering offered by options like MongoDB’s ReplicaSet, Microsoft SQL Server’s AlwaysOn Availability Group and Oracle database’s Knowledge Guard. We will have 2 subtypes for database solution-based replication:
- Logical replication: the place we replicate the database consumer requests from one occasion to the opposite. Oracle Golden Gate and MySQL assertion based mostly replication assist one of these replication.
- Bodily replication: the place we replicate the impact of database consumer requests on the info from one database to the opposite (going via the occasion). Oracle Knowledge Guard and MySQL row based mostly replication assist this sort of replication.
We use the time period replicas to indicate the extra database(s) ensuing from the replication mechanism.
The major database/occasion is the one receiving the consumer’s write site visitors.
Shared-nothing database deployments are composed of unbiased servers, every having its personal devoted reminiscence, compute and storage. They have an inclination to offer greater availability as they permit us to leverage all of the isolation constructs we are going to see within the subsequent part.
Isolation constructs
Isolation is about decreasing the impression radius of a given failure/catastrophe occasion in your cluster parts . The extra distant your redundant parts are, the much less probably that every one of them will fail concurrently.
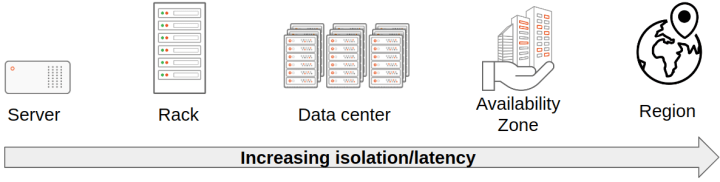
Server isolation
That is essentially the most elementary type of isolation. Putting redundant parts in numerous servers prevents a failure in a community card, an hooked up storage system or a CPU from impacting your whole redundant parts.
Rack isolation
A rack is a standardised enclosure to mount servers and numerous different digital tools. The servers hosted in the identical rack may share a variety of components like community switches and energy cables. Putting your redundant parts into servers hosted in numerous racks will stop a failure on one of many rack-shared parts from impacting your whole deployment.
Knowledge centre isolation
Sometimes, all of the servers hosted in a given knowledge centre share energy and cooling infrastructures. Utilizing a number of knowledge centres to host your database deployment will make it resilient in direction of a broader vary of occasions, like energy failures and knowledge centre-wide upkeep operations.
Availability zone isolation
Public cloud suppliers popularised the idea of “availability zone”. It consists of a number of knowledge centres which might be, geographically talking, shut to one another.
Utilizing a number of availability zones to host your database deployments may defend your providers from some “pure” disasters like a fireplace and floods.
Area isolation
We will go one step additional by way of isolation and use a number of areas for our database deployments. This sort of set-up can defend your database from main disasters like storms, volcano eruptions and even political instability (take into consideration transferring your workload from a battle zone to a different area).
Now that now we have a great overview on the way to make a given database deployment resilient to sure failure occasions, we have to make it possible for we are able to robotically leverage its resiliency.
Automated fail-over administration
Fail-over is the method by which we switch possession of a database service from a defective server to a wholesome one.
A fail-over might be initiated manually by a human or robotically by a part of the database deployment. Counting on human intervention may lead to greater downtime in comparison with automated fail-overs, subsequently it ought to be prevented.
Server facet fail-over
With the intention to robotically provoke a fail-over from a major occasion/database to a reproduction, a part ought to monitor the state of every of the situations and determine to which wholesome one the service ought to be transferred.
Here’s a record of fail-over instruments for a number of the common databases:
- Orchestrator for MySQL/MariaDB
- Patroni (together with the required Distributed Configuration Retailer) for PostgreSQL
- Home windows Server Failover Cluster (WSFC) together with participant voting witnesses for SQL Server
- Oracle Knowledge Guard (together with the observers part) for Oracle database
If you’re planning to make use of such instruments then you should carry out a sequence of checks (each on major and replicas) to make sure that the cluster behaviour matches your expectations:
- Gracefully cease the primary database occasion course of
- Abruptly kill the primary database occasion course of
- Reboot the internet hosting server
- Kill the clustering/fail-over processes
- Isolate, from community perspective, the involved database occasion from the remainder of the database situations
Relying on the behaviour of the chosen answer, you may must implement your individual customisation to satisfy your necessities.
Software facet fail-over
An essential facet, usually ignored, in database excessive availability is the capability of the appliance to promptly (re)connect with the wholesome database situations following a server fail-over.
To ensure that your functions to fail-over rapidly to the wholesome situations, you may must:
- Set cheap TCP keepalive settings that permit your functions to detect damaged connections on-time.
- Set time-outs on all of your database calls to keep away from hanging connections.
- Implement retry logic inside your functions to mitigate sure kinds of database/community errors.
- Use database proxies to cover adjustments of the first host from the database consumer.
As we noticed in the course of the earlier part, making certain database excessive availability entails a substantial quantity of labor to design, take a look at and keep a number of parts and configurations.
Within the subsequent part, we are going to speak concerning the Canonical choices that may aid you attain your excessive availability objectives.
Canonical answer to offer Excessive Availability
Juju is the Canonical’s reply to robotically handle advanced functions involving any variety of applied sciences, together with databases.
We offer a curated record of charmed Juju operators for a variety of databases with built-in excessive availability and fail-over automation.
Furthermore, Juju’s distinctive means to precise relations between numerous workloads helps you in making certain, for instance, that your software will all the time goal a wholesome database occasion.
Juju helps DevOps, DBAs and SREs in rapidly deploying, sustaining and upgrading functions in a holistic style.
The Juju ecosystem permit its customers to retain a excessive diploma of customization and freedom:
- We offer open supply operators you can customise and lengthen at will.
- You’ll be able to determine to retain full entry to the underlying infrastructure or allow us to handle the infrastructure for you.
- Juju can deploy your functions on a number of clouds, providing you with the liberty to decide on what most closely fits your wants.
Please contact us to study extra about Juju and our options to attain excessive availability in your workloads.

{kind=link}