
A Complete Information

In Pc Imaginative and prescient — object detection is the duty of detecting an object in a picture or video. The job of an object detection algorithm is 2 fold
- a localization process — outputs the bounding field (x, y coordinate). In essence, the localization process is a regression downside that outputs steady numbers representing the bounding field coordinates.
- a classification process — classifies an object (individual vs automotive and many others.).
Object detection algorithms may be based mostly on conventional Pc Imaginative and prescient approaches or Neural Community ones [1]. Among the many Neural Community based mostly approaches — we are able to classify the algorithms in two most important classes — single stage and two stage object detector.
In a single-stage object detector — the duty of localization and classification is finished in a single move — which means there is no such thing as a further community to “assist” the localization and classification strategy of the thing detector. Single-stage detectors yields larger inference pace and preferable for cell and edge units. The YOLO household of object detection algorithms are single-stage object detector.
In a two-stage detector — along with the localization and classification community, we have now an extra community known as Area Proposal Community (RPN). RPN is used to determine “the place” to look with a view to scale back the computational necessities of the general object detection community. RPN makes use of anchors — fastened sized reference bounding bins that are positioned uniformly all through the unique picture. Within the area proposal stage [2] — we ask
- Does this anchor comprise a related object?
- How will we regulate the anchor to higher match the related object?
As soon as we have now a listing from the above course of, the duty of localization and classification community turns into straight-forward. Two-stage detectors have usually larger localization and classification accuracy. RCNN, Quicker-RCNN and many others. are a couple of examples of two stage object detectors.
A picture is an enter to an object detection community. The enter is handed by means of a Convolutional Neural Community (CNN) spine to extract options (embedding) out of it. The job of the neck stage is to combine and mix the options fashioned within the CNN spine to arrange for the head step. The elements of the neck sometimes circulate up and down amongst layers and join solely the few layers on the finish of the [7]. The head is chargeable for the prediction — aka. classification and localization.

YOLO household of object detectors [3] are the state-of-the-art (SOTA) single stage object detectors. YOLO household has advanced from YOLOv1 since its inception in 2016 to this date with YOLOX in 2021. On this article, our focus will likely be on YOLOX.

Lets take a look at a couple of architectural elements of YOLOX.
Decoupled Head
With YOLOv3-v5, the detection head remained coupled. This posed a problem because the detection head is principally doing two totally different duties — classification and regression (bounding field). Changing YOLO’s head with a decoupled one — one for classification and the opposite for bounding field regression.
Robust Information Augmentation
YOLOX added two information augmentation methods — Mosaic and MixUp.
- Mosaic was initially launched in YOLOv3 and subsequently utilized in v4 and v5. Mosaic information augmentation combines 4 coaching photographs into one in sure ratios. This enables for the mannequin to learn to determine objects at a smaller scale than regular. It additionally is helpful in coaching to considerably scale back the necessity for a big mini-batch measurement [4].
- MixUp — is an information augmentation method that that generates a weighted mixtures of random picture pairs from the coaching information [5].
Anchor-free Structure
YOLOv3-5 have been anchor based mostly pipeline — which means the RPN model fastened sized reference bounding bins that are positioned uniformly all through the unique picture to test if this field comprises an anticipated class. Anchor bins enable us to seek out multiple object in the identical grid. However anchor based mostly mechanisms has some issues too —
- In anchor-based mechanism, optimum anchor bins ought to be decided for object detection. To try this, we have to discover optimum anchor bins with clustering evaluation earlier than coaching. That is an additional step that improve coaching time and complexity.
- One other downside is that the anchor-based mechanism will increase the variety of predictions to be made for every picture. This may improve the inference time.
- And eventually, anchor-based mechanism considerably will increase the complexity of the detection head and the general community.
In recent times, anchor-free mechanisms have been improved however weren’t introduced into the YOLO household till YOLOX.
Anchor-free YOLOX reduces variety of prediction for every picture cell from 3 to 1.
SimOTA
SimOTA is a sophisticated label project method. What’s label project? It defines constructive/damaging coaching samples for every floor reality object. YOLOX formulates this label project downside as an Optimum Transport (OT) downside [6].
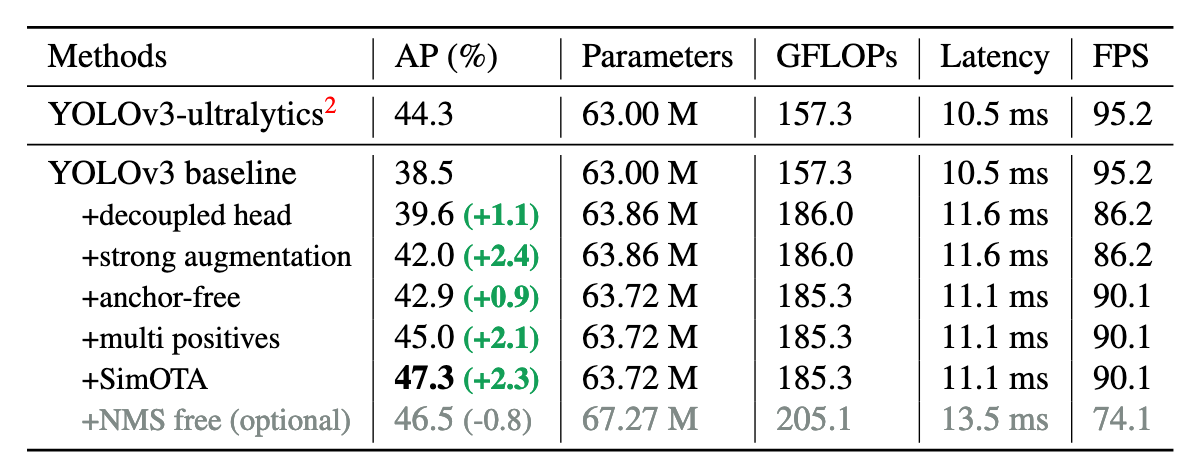
Under desk reveals how these totally different structure elements assist enhance the Common Precision (AP) of the mannequin over baseline.
Set up
You’ll find the open supply code for YOLOX right here. Following the set up part, you may set up from the supply
git clone git@github.com:Megvii-BaseDetection/YOLOX.git
cd YOLOX
pip3 set up -v -e . # or python3 setup.py develop
Dataset Conversion
Be sure that your {custom} dataset is in COCO format. In case your dataset is in darknet or yolo5 format, you need to use YOLO2COCO repository to transform it to COCO format.
Obtain Pre-trained Weight
When coaching our mannequin on {custom} dataset, we want to start out with a pretrained baseline and practice on our information on prime of it.
wget https://github.com/Megvii-BaseDetection/storage/releases/obtain/0.0.1/yolox_s.pth
Mannequin Coaching
A vital part of YOLOX mannequin coaching is to have the correct experiment file — a couple of pattern {custom} experiment information are right here.
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# Copyright (c) Megvii, Inc. and its associates.
import osfrom yolox.exp import Exp as MyExp
class Exp(MyExp):
def __init__(self):
tremendous(Exp, self).__init__()
self.depth = 0.33
self.width = 0.50
self.exp_name = os.path.cut up(os.path.realpath(__file__))[1].cut up(".")[0]
# Outline your self dataset path
self.data_dir = "datasets/coco128"
self.train_ann = "instances_train2017.json"
self.val_ann = "instances_val2017.json"
self.num_classes = 71
self.max_epoch = 300
self.data_num_workers = 4
self.eval_interval = 1
You’ll be able to experiment with the variables reminiscent of self.num_classes based mostly on the variety of courses you’ve got, change dataset path and many others.
You’ll be able to see one other instance of a {custom} experiment file right here
import os
from yolox.exp import Exp as MyExpclass Exp(MyExp):
def __init__(self):
tremendous(Exp, self).__init__()
self.depth = 0.33
self.width = 0.50
self.exp_name = os.path.cut up(os.path.realpath(__file__))[1].cut up(".")[0]
# Outline your self dataset path
self.data_dir = "information"
self.train_ann = "practice.json"
self.val_ann = "val.json"
self.num_classes = 1
self.data_num_workers = 4
self.eval_interval = 1
# --------------- rework config ----------------- #
self.levels = 10.0
self.translate = 0.1
self.scale = (0.1, 2)
self.mosaic_scale = (0.8, 1.6)
self.shear = 2.0
self.perspective = 0.0
self.enable_mixup = True
# -------------- coaching config --------------------- #
self.warmup_epochs = 5
self.max_epoch = 300
self.warmup_lr = 0
self.basic_lr_per_img = 0.01 / 64.0
self.scheduler = "yoloxwarmcos"
self.no_aug_epochs = 15
self.min_lr_ratio = 0.05
self.ema = True
self.weight_decay = 5e-4
self.momentum = 0.9
To coach the mannequin (ensure you are within the YOLOX listing), you need to use under command. Be aware the parameters of d and b. d signifies the variety of GPU, in my case it’s 1. b is the batch measurement throughout coaching which is 8x the worth of d.
python instruments/practice.py -f exps/instance/{custom}/yolox_tiny.py -d 1 -b 8 --fp16 -o -c yolox_tiny.pth
Mannequin Analysis
Throughout mannequin analysis, it’s important to specify the identical (or a replica of it) experiment file that you just used for coaching
python -m yolox.instruments.eval -n yolox_s -c YOLOX_outputs/yolox_s/best_ckpt.pth -f exps/instance/{custom}/yolox_s.py -b 1 -d 1 --conf 0.001 --fp16 --fuse
Mannequin Testing
To run YOLOX inference on check picture, we are able to do under [8]
TEST_IMAGE_PATH = "test_image.jpg"python instruments/demo.py picture -f exps/instance/{custom}/yolox_s.py -c YOLOX_outputs/yolox_s/best_ckpt.pth --path {TEST_IMAGE_PATH} --conf 0.25 --nms 0.45 --tsize 640 --save_result --device gpu
Let’s say the output prediction picture is prediction.jpg. You’ll be able to visualize this picture like under
from PIL import Picture
Picture.open('prediction.jpg')
To test how your mannequin performs on a video, you are able to do under
python instruments/demo.py video -n yolox-s -c /path/to/your/yolox_s.pth -f exps/instance/{custom}/yolox_s.py --path /path/to/your/video --conf 0.25 --nms 0.45 --tsize 640 --save_result --device [cpu/gpu]
Be aware the parameter conf right here — it signifies the boldness interval, which means how assured you need your mannequin to be earlier than it outputs a bounding field. Having the next conf rating usually will increase the standard of your detection — eradicating undesirable bounding field and many others.
Path Ahead:
Now that we discovered how you can practice YOLOX on a {custom} dataset — there are numerous potentialities forward. Relying in your use-case, you may want a lighter or heavier model of YOLOX. You’ll be able to experiment with the parameters within the experiment file outlined in `exps/instance/{custom}/yolox_s.py. As soon as the mannequin is prepared, relying in your usecase you would possibly must prune or quantize the mannequin — particularly in case you are deploying it on an edge gadget.
I hope you loved this weblog put up. Be happy to remark right here if in case you have any query.
References:
- Object Detection in 20 Years: A Survey https://arxiv.org/pdf/1905.05055.pdf
- One-stage vs two-stage object detector https://stackoverflow.com/questions/65942471/one-stage-vs-two-stage-object-detection
- Introduction to the YOLO household https://pyimagesearch.com/2022/04/04/introduction-to-the-yolo-family/
- YOLOv4 information augmentation https://weblog.roboflow.com/yolov4-data-augmentation/
- MixUp https://paperswithcode.com/technique/mixup
- Optimum Transport Task for Object Detection https://arxiv.org/pdf/2103.14259.pdf
- A radical breakdown of YOLOv4 https://weblog.roboflow.com/a-thorough-breakdown-of-yolov4/
- The right way to practice a {custom} YOLOX mannequin https://weblog.roboflow.com/how-to-train-yolox-on-a-custom-dataset/

{kind=link}