Environment friendly vector quantization for machine studying optimizations (eps. vector quantized variational autoencoders), higher than straight by means of estimator
Vector quantization (VQ) is an information compression method which fashions the chance density perform of the info by some consultant vectors referred to as codebooks. Vector quantization has been just lately utilized in a variety of machine learning-based purposes, particularly these based mostly on vector quantized variational autoencoders (VQ-VAE); e.g. picture technology [1], speech coding [2], voice conversion [3], music technology [4], and text-to-speech synthesis [5].
Based on the next determine, vector quantization is the operation of mapping all knowledge factors (in a voronoi-cell) to its nearest codebook level. In different phrases, it finds the closest codebook vector (c_k*) to the enter knowledge vector (x) from a set of codebook vectors (c_k)s utilizing the next components, and map (quantize) x to x^ by changing its worth by the closest codebook which is c_k*.
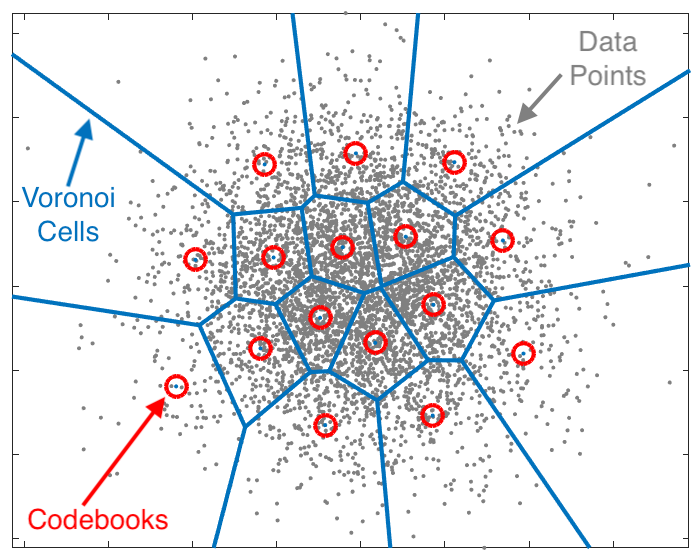
It’s apparent that vector quantization can’t be used straight in machine learning-based optimizations, since there isn’t any actual gradients outlined for it (for the above-mentioned equation). Therefore, we have to apply some methods to estimate gradients for VQ perform, and make it go these gradients by means of backpropagation and replace the codebook vectors.
VQ-VAE was first launched within the paper “Neural Discrete illustration Studying” by Oord et al [6]. They apply VQ to mannequin a discrete illustration of the latent area of variational autoencoder. In different phrases, they apply VQ on the output of the encoder and discover the most effective embeddings (codebooks) for that, after which go these embeddings to the decoder. To go the gradients for VQ perform in backpropagation (backward go), this paper and all above-mentioned ones use straight by means of estimator (STE) [7], which simply merely copies gradients over VQ module, like what’s proven within the picture under.
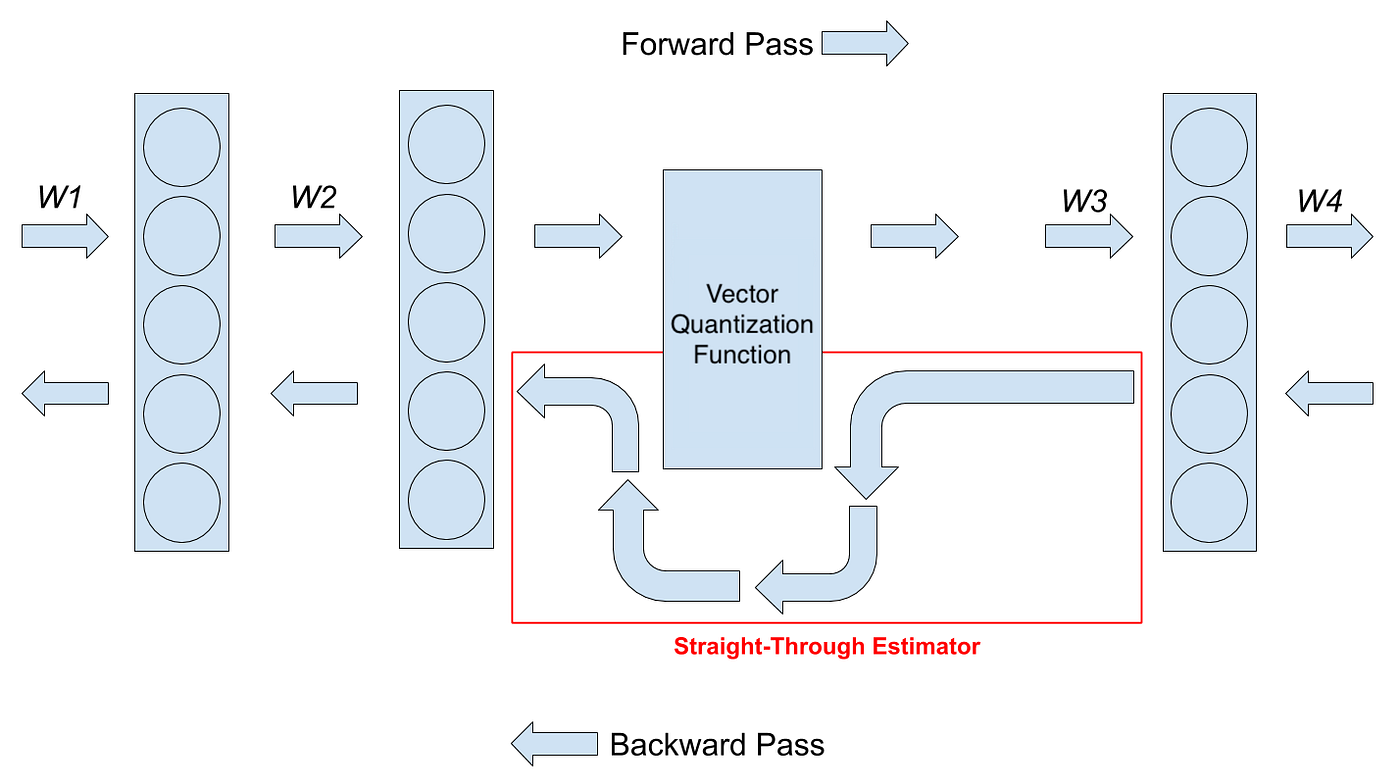
Nonetheless, straight by means of estimator (STE) doesn’t think about the affect of quantization and results in a mismatch between the gradient and true conduct of the vector quantization. As well as, for the strategies which use STE, it’s important so as to add a further loss time period to the worldwide loss perform to make the VQ codebooks (embeddings) to be up to date. Due to this fact, the weighting coefficient for the extra loss time period is a brand new hyper-parameter, which is required to be tuned manually. The loss perform for the VQ-VAE launched by Oord et al. [6] is proven under. The second and third phrases within the components are the required loss phrases for VQ module with the weighting coefficients of alpha and beta. For extra particulars concerning the loss perform, please see the paper.
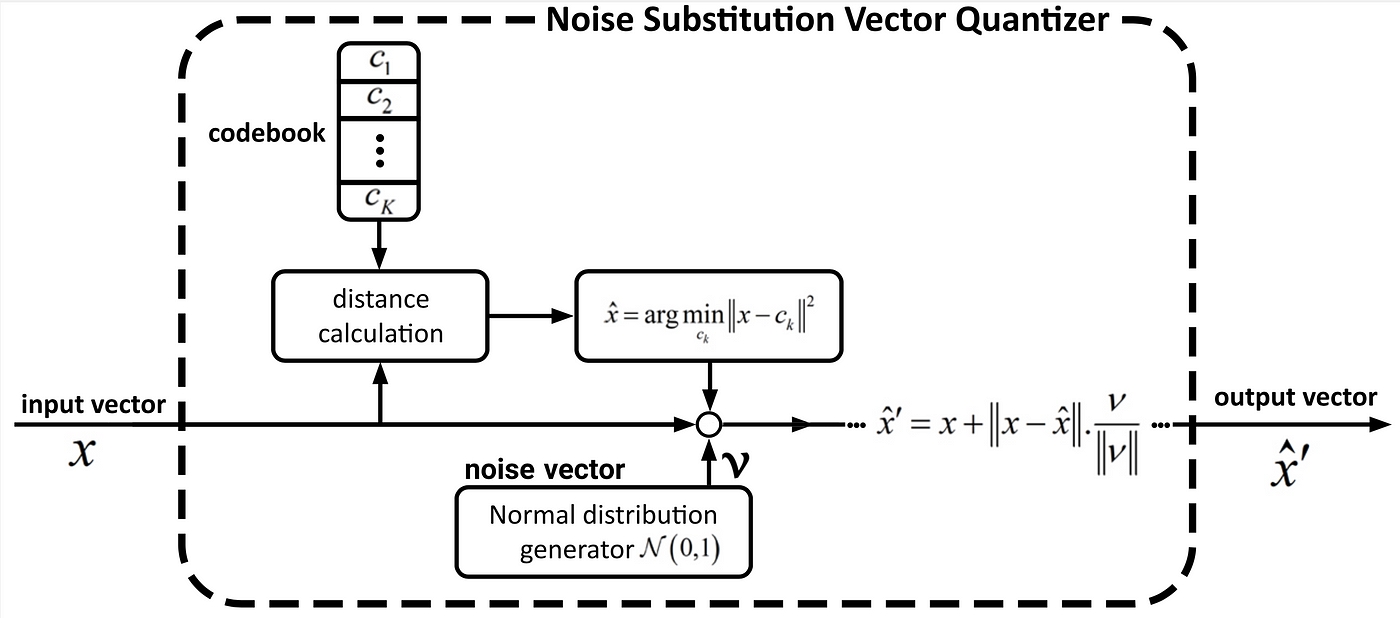
On this submit, we need to introduce our just lately proposed vector quantization method for machine learning-based approaches, which is revealed beneath the title of “NSVQ: Noise Substitution in Vector Quantization for Machine Studying” [8]. NSVQ is a method wherein the vector quantization error is simulated by including noise to the enter vector, such that the simulated noise would achieve the form of authentic VQ error distribution. The block diagram of NSVQ is proven under.
We check our NSVQ technique in three totally different eventualities of experiments,
- speech coding: to mannequin the spectral envelopes of speech indicators
- picture compression: to mannequin the latent illustration of VQ-VAE proposed in [6]
- toy-examples: to mannequin some well-known knowledge distributions.
Based mostly on the leads to our paper [8] (that are additionally supplied within the following figures), it has been proven that not solely NSVQ can go the gradients within the backward go, but it surely can also present extra correct gradients for codebooks than STE. Moreover, NSVQ results in larger quantization accuracy, and sooner convergence in comparison with STE. As well as, NSVQ performs extra deterministically (exhibits much less variance in efficiency) when operating a person experiment for a number of occasions. One nice good thing about utilizing NSVQ is that it doesn’t want any addtional loss time period to be added to the worldwide loss perform. Therefore, it doesn’t incur any extra hyper-parameter tuning (the coefficient for the extra loss time period in STE).
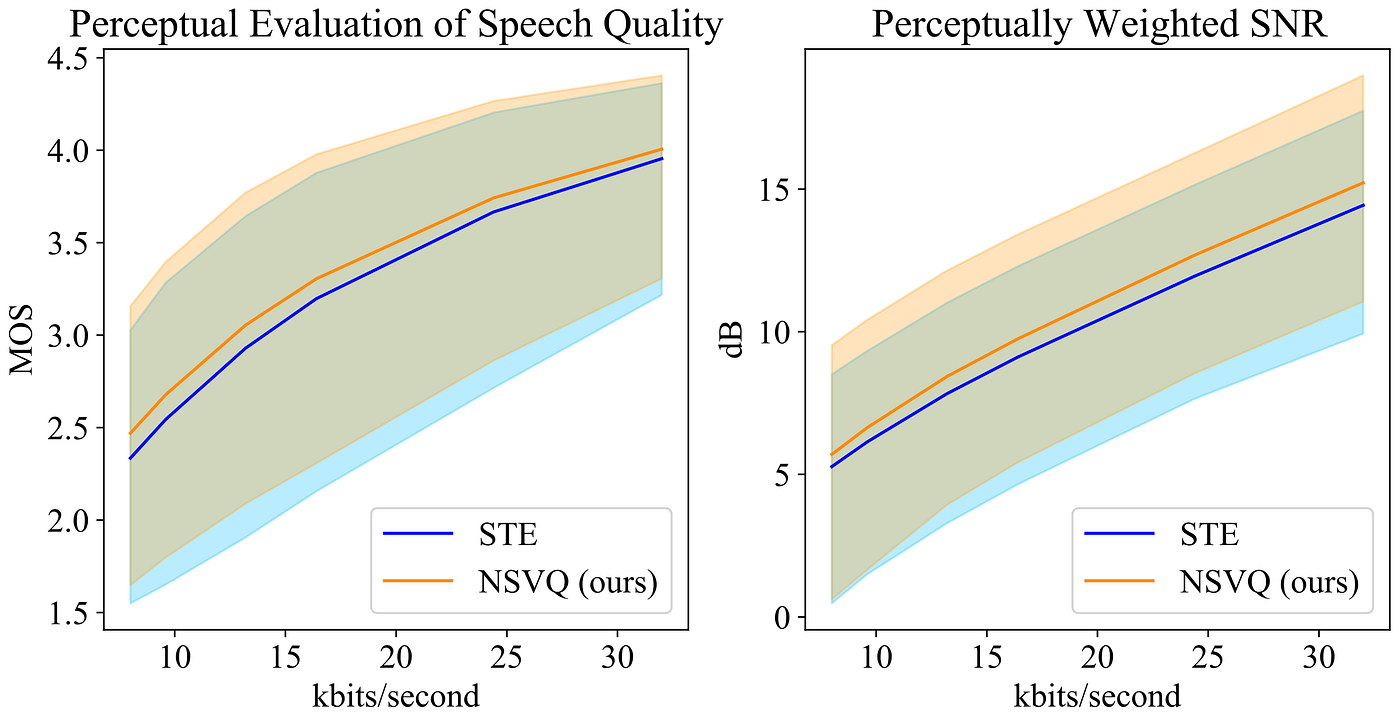
Within the speech coding situation, we use perceptual analysis of speech high quality (PESQ) and perceptually weighted sign to noise ratio (pSNR) as goal metrics to guage the standard of decoded speech for STE and our proposed NSVQ technique. The next determine exhibits the outcomes.
Within the picture compression situation, we make use of structural similarity index measure (SSIM) and peak sign to noise ratio (Peak SNR) as goal metrics to guage the standard of the reconstructed picture on the decoder aspect of VQ-VAE. The next determine demonstrates the outcomes.
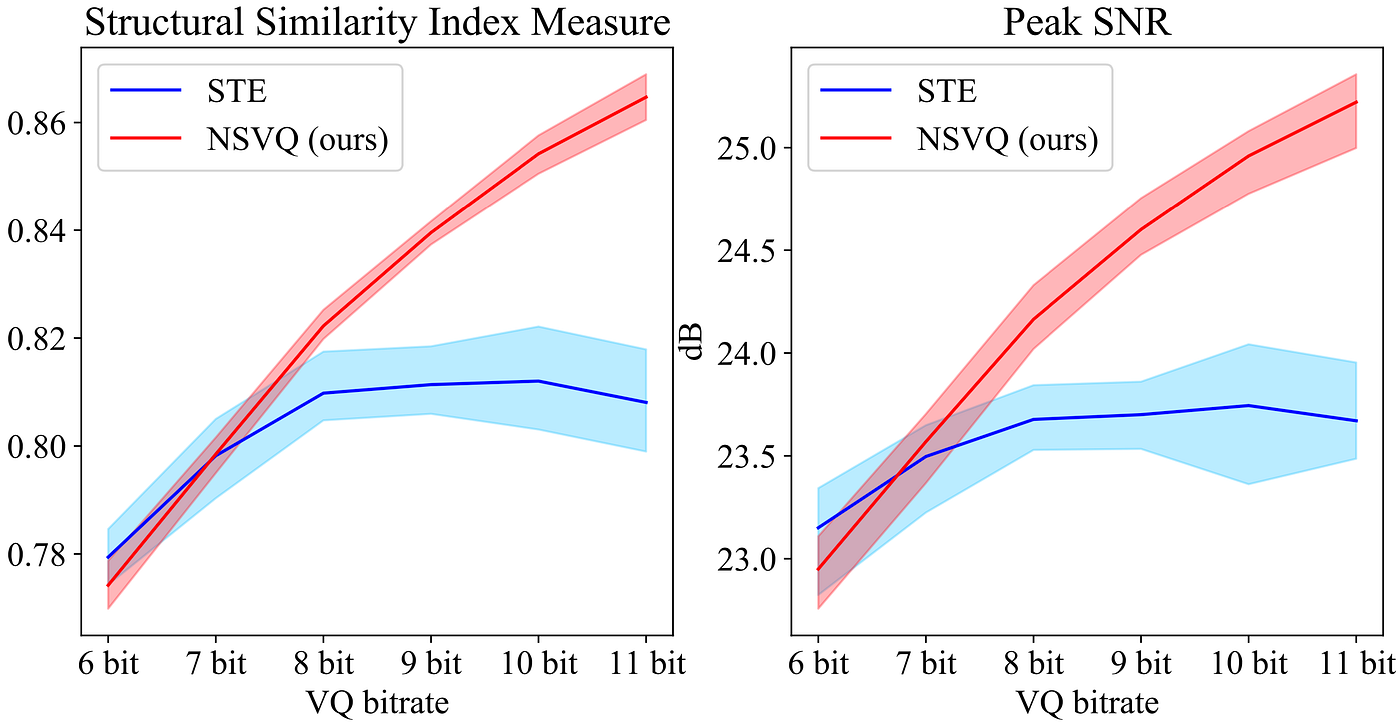
Based on the above determine, the proposed NSVQ obtains strictly ascending SSIM and Peak SNR values when rising the VQ bitrate, which confirms that it behaves constantly with the rise in bitrate. This conduct is what we anticipate from a real VQ. Nonetheless, the STE technique doesn’t comply with the identical conduct. We predict the reason being that the STE doesn’t think about the affect of VQ perform in backpropagation.
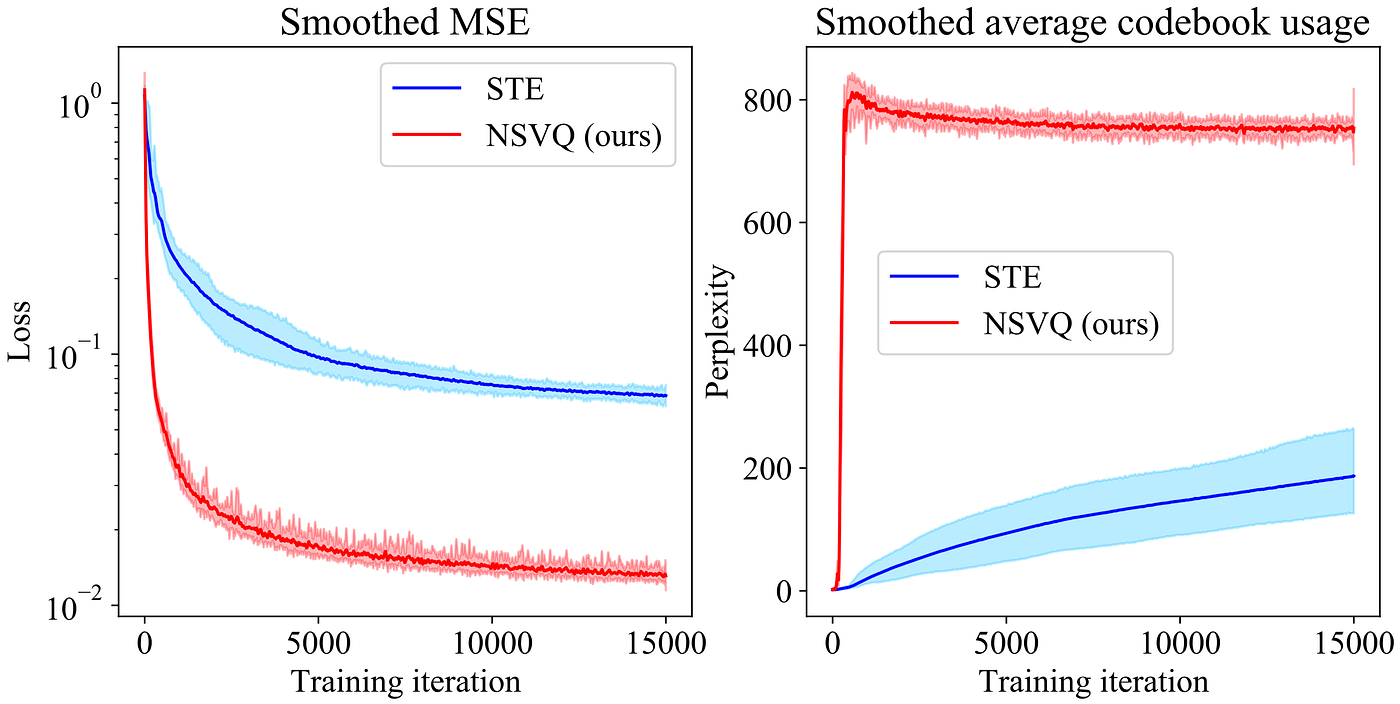
Within the picture compression situation, aside from goal evaluations we additionally examine two different issues; the coaching convergence velocity and the codebook vectors perplexity (the typical codebook utilization). Right here is the outcomes.
Within the third situation of our paper, we mannequin the distribution of swiss-roll distribution in 2D area utilizing 8-bit vector quantization (2⁸=256 codebooks). We initialize the places of codebook vectors out of information distribution to make the VQ tougher. The ultimate optimized codebook places for NSVQ and STE strategies are proven within the following figures.
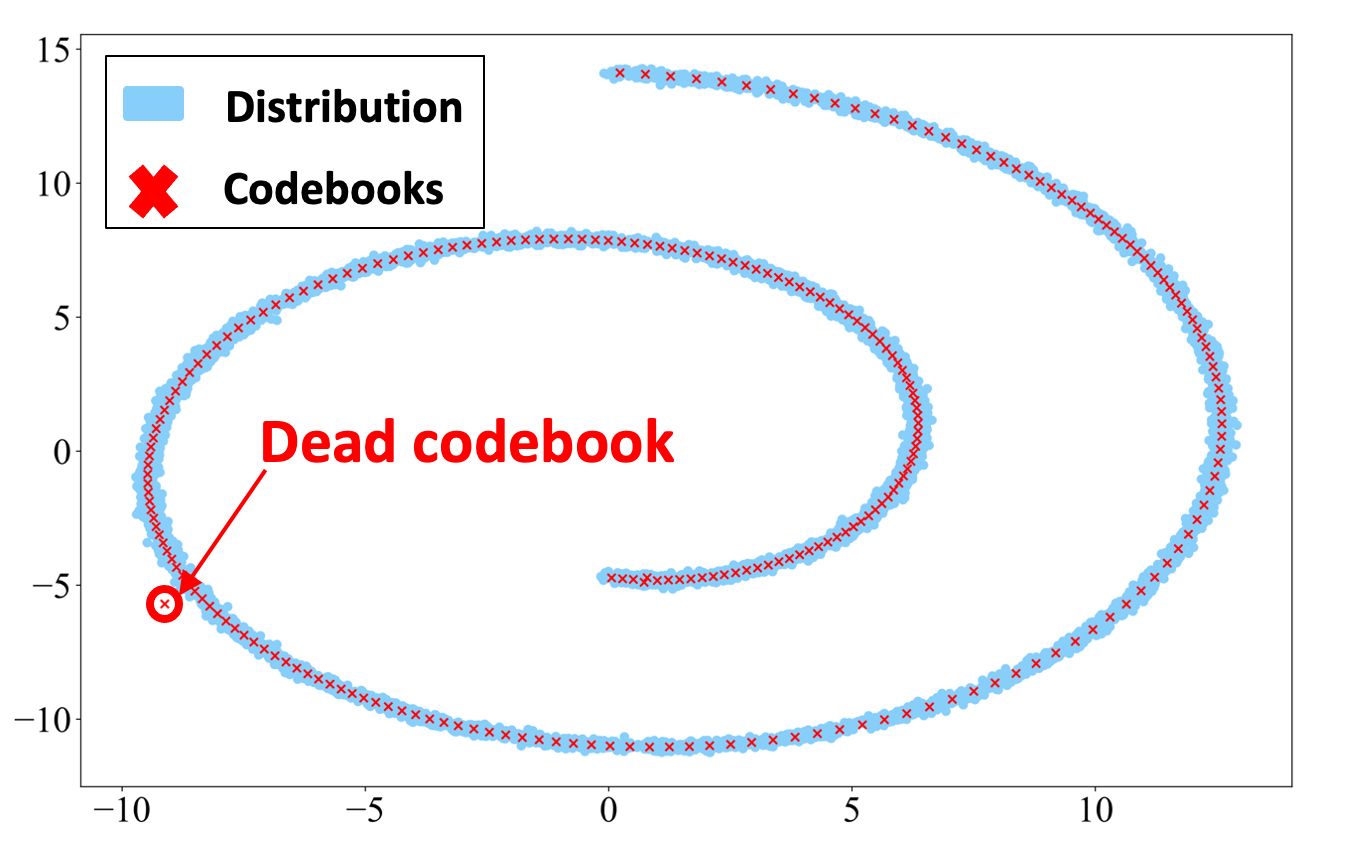
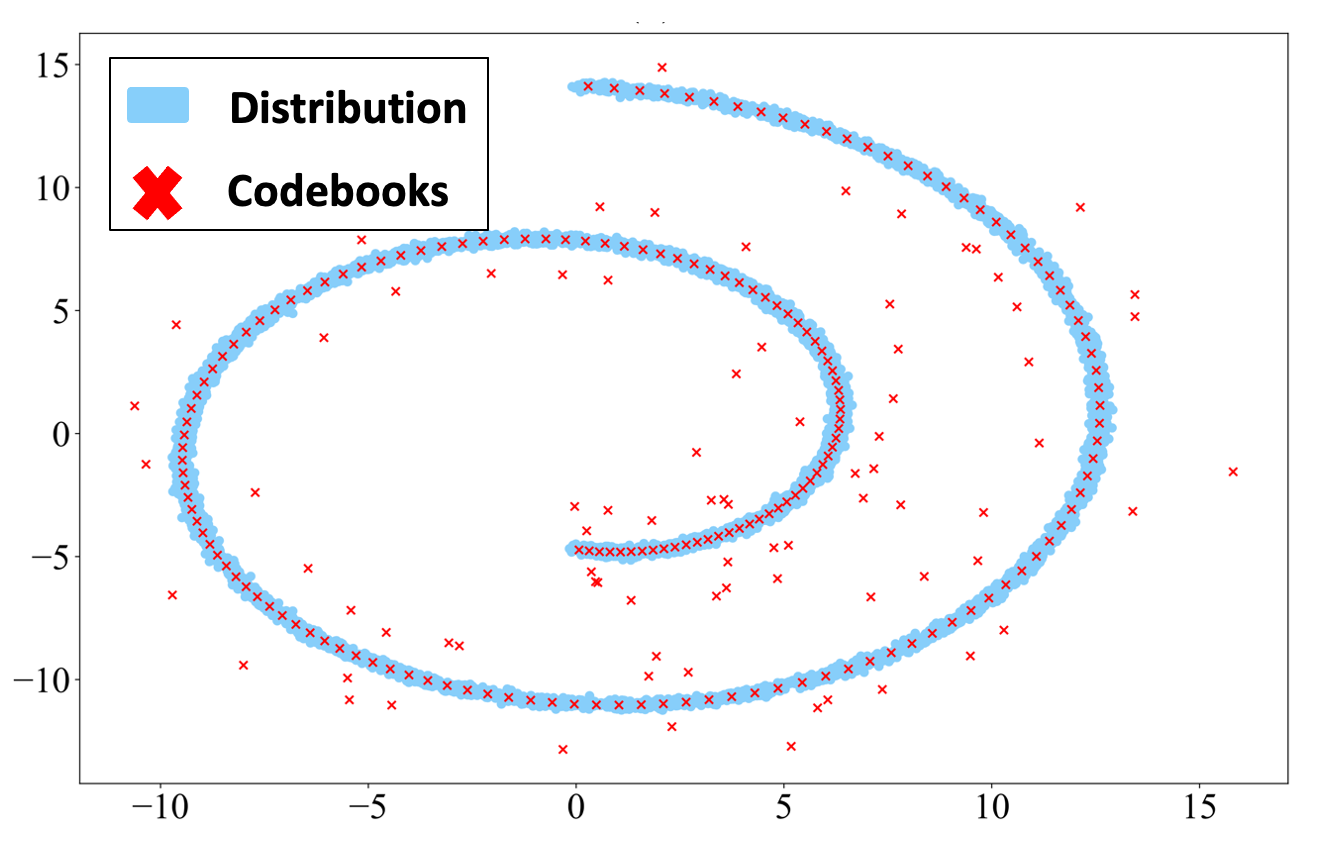
Based on the figures, NSVQ captures the swiss-roll distribution form significantly better than STE with a lot much less variety of useless codebooks (codebook which is chosen out of the info distribution and is ineffective for the decoding section). Therefore, it may be concluded that NSVQ is far much less delicate to the initialization of the codebooks in comparison with STE. Be aware that this conduct of NSVQ is partially as a result of codebook substitute perform talked about in our paper.
On the finish, I’ve to say that the NSVQ method is relevant to coach any machine studying software, which requires vector quantization someplace within the computational graph. Nonetheless, please word that NSVQ is just utilized for the coaching section with a view to be taught the vector quantization codebooks. However, it isn’t used within the inference section, since we don’t want any gradients to be handed within the backpropagation. So, within the inference section, it’s higher and extra correct to proceed with the unique vector quantization components talked about above.
We offer the PyTorch code of the NSVQ within the following public webpage:
Particular because of my doctoral program supervisor Prof. Tom Bäckström, who supported me and was the opposite contributor for this work.
[1] A. Razavi, A. van den Oord, and O. Vinyals, ‘‘Producing numerous high- constancy pictures with VQ-VAE-2,’’ in Proc. 33th Int. Conf. Neural Inf. Course of. Syst., vol. 32, 2019, pp. 14866–14876.
[2] C. Garbacea, A. V. den Oord, Y. Li, F. S. C. Lim, A. Luebs, O. Vinyals, and T. C. Walters, ‘‘Low bit-rate speech coding with VQ-VAE and a WaveNet decoder,’’ in Proc. IEEE Int. Conf. Acoust., Speech Sign Course of. (ICASSP), Could 2019, pp. 735–739.
[3] S. Ding and R. Gutierrez-Osuna, “Group latent embedding for vector quantized variational autoencoder in non-parallel voice conversion,” in Proceedings of Inter- speech, 2019, pp. 724–728.
[4] P. Dhariwal, H. Jun, C. Payne, J. W. Kim, A. Radford, and I. Sutskever, “Jukebox: a generative mannequin for music,” arXiv preprint arXiv:2005.00341, 2020.
[5] A. Tjandra, B. Sisman, M. Zhang, S. Sakti, H. Li, and S. Nakamura, “VQVAE unsupervised unit discovery and multi-scale code2spec inverter for Zerospeech problem 2019,” arXiv preprint arXiv:1905.11449, 2019.
[6] A. van den Oord, O. Vinyals, and Okay. Kavukcuoglu, “Neural discrete illustration studying,” in Proceedings of the thirty first Worldwide Convention on Neural Data Processing Programs, 2017, pp. 6309–6318.
[7] Y. Bengio, N. Le ́onard, and A. Courville, “Estimating or propagating gradients by means of stochastic neurons for conditional computation,” arXiv preprint arXiv:1308.3432, 2013.
[8] M. H. Vali and T. Bäckström, “NSVQ: Noise Substitution in Vector Quantization for Machine Studying,” IEEE Entry, vol. 10, pp. 13 598–13 610, 2022.
