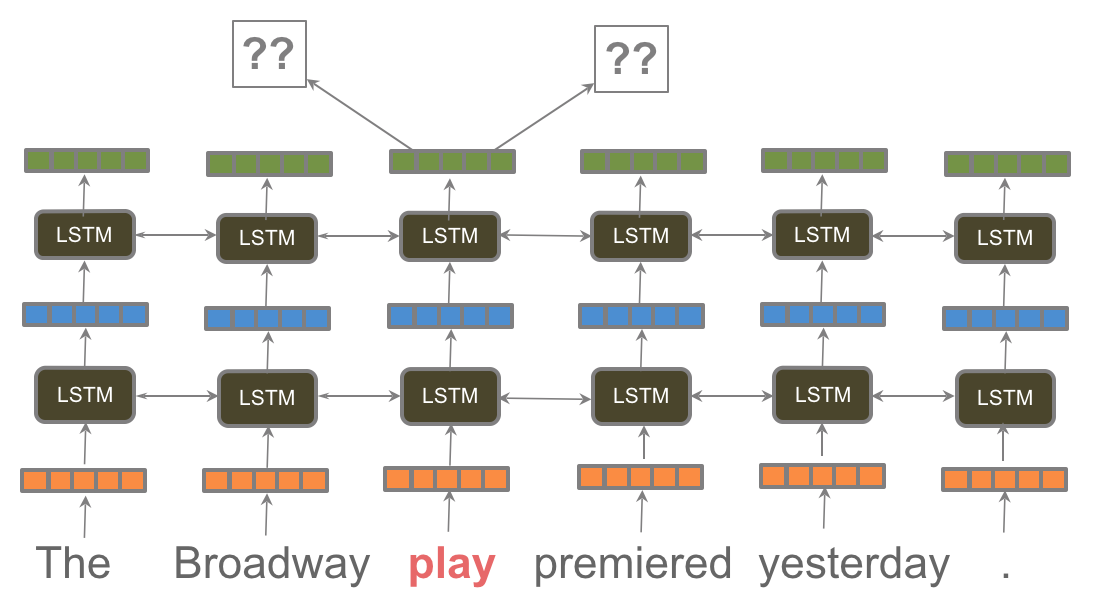
This submit discusses pretrained language fashions, some of the thrilling instructions in up to date NLP.
This submit initially appeared at TheGradient and was edited by Andrey Kurenkov, Eric Wang, and Aditya Ganesh.
Huge modifications are underway on the planet of Pure Language Processing (NLP). The lengthy reign of phrase vectors as NLP’s core illustration method has seen an thrilling new line of challengers emerge: ELMo, ULMFiT, and the OpenAI transformer. These works made headlines by demonstrating that pretrained language fashions can be utilized to realize state-of-the-art outcomes on a variety of NLP duties. Such strategies herald a watershed second: they could have the identical wide-ranging affect on NLP as pretrained ImageNet fashions had on pc imaginative and prescient.
From Shallow to Deep Pre-Coaching
Pretrained phrase vectors have introduced NLP a great distance. Proposed in 2013 as an approximation to language modeling, word2vec discovered adoption by way of its effectivity and ease of use in a time when {hardware} was so much slower and deep studying fashions weren’t broadly supported. Since then, the usual manner of conducting NLP initiatives has largely remained unchanged: phrase embeddings pretrained on massive quantities of unlabeled knowledge through algorithms similar to word2vec and GloVe are used to initialize the primary layer of a neural community, the remainder of which is then educated on knowledge of a specific job. On most duties with restricted quantities of coaching knowledge, this led to a lift of two to a few share factors. Although these pretrained phrase embeddings have been immensely influential, they’ve a serious limitation: they solely incorporate earlier information within the first layer of the model—the remainder of the community nonetheless must be educated from scratch.
Word2vec and associated strategies are shallow approaches that commerce expressivity for effectivity. Utilizing phrase embeddings is like initializing a pc imaginative and prescient mannequin with pretrained representations that solely encode edges: they are going to be useful for a lot of duties, however they fail to seize higher-level data that could be much more helpful. A mannequin initialized with phrase embeddings must be taught from scratch not solely to disambiguate phrases, but additionally to derive that means from a sequence of phrases. That is the core side of language understanding, and it requires modeling complicated language phenomena similar to compositionality, polysemy, anaphora, long-term dependencies, settlement, negation, and lots of extra. It ought to thus come as no shock that NLP fashions initialized with these shallow representations nonetheless require an enormous variety of examples to realize good efficiency.
On the core of the latest advances of ULMFiT, ELMo, and the OpenAI transformer is one key paradigm shift: going from simply initializing the primary layer of our fashions to pretraining your complete mannequin with hierarchical representations. If studying phrase vectors is like solely studying edges, these approaches are like studying the total hierarchy of options, from edges to shapes to high-level semantic ideas.
Curiously, pretraining total fashions to be taught each high and low degree options has been practiced for years by the pc imaginative and prescient (CV) neighborhood. Most frequently, that is carried out by studying to categorise photos on the massive ImageNet dataset. ULMFiT, ELMo, and the OpenAI transformer have now introduced the NLP neighborhood near having an “ImageNet for language“—that is, a job that allows fashions to be taught higher-level nuances of language, equally to how ImageNet has enabled coaching of CV fashions that be taught general-purpose options of photos. In the remainder of this piece, we’ll unpack simply why these approaches appear so promising by extending and constructing on this analogy to ImageNet.
ImageNet

ImageNet’s affect on the course of machine studying analysis can hardly be overstated. The dataset was initially printed in 2009 and rapidly developed into the ImageNet Giant Scale Visible Recognition Problem (ILSVRC). In 2012, the deep neural community submitted by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton carried out 41% higher than the subsequent greatest competitor, demonstrating that deep studying was a viable technique for machine studying and arguably triggering the explosion of deep studying in ML analysis.
The success of ImageNet highlighted that within the period of deep studying, knowledge was not less than as necessary as algorithms. Not solely did the ImageNet dataset allow that essential 2012 demonstration of the ability of deep studying, nevertheless it additionally allowed a breakthrough of comparable significance in switch studying: researchers quickly realized that the weights discovered in state-of-the-art fashions for ImageNet could possibly be used to initialize fashions for utterly different datasets and enhance efficiency considerably. This “fine-tuning” method allowed reaching good efficiency with as little as one optimistic instance per class (Donahue et al., 2014).
Pretrained ImageNet fashions have been used to realize state-of-the-art leads to duties similar to object detection, semantic segmentation, human pose estimation, and video recognition. On the similar time, they’ve enabled the applying of CV to domains the place the variety of coaching examples is small and annotation is dear. Switch studying through pretraining on ImageNet is the truth is so efficient in CV that not utilizing it’s now thought-about foolhardy (Mahajan et al., 2018).
What’s in an ImageNet?
With a purpose to decide what an ImageNet for language may seem like, we first need to establish what makes ImageNet good for switch studying. Earlier research have solely shed partial mild on this query: decreasing the variety of examples per class or the variety of courses solely leads to a small efficiency drop, whereas fine-grained courses and extra knowledge will not be all the time higher.
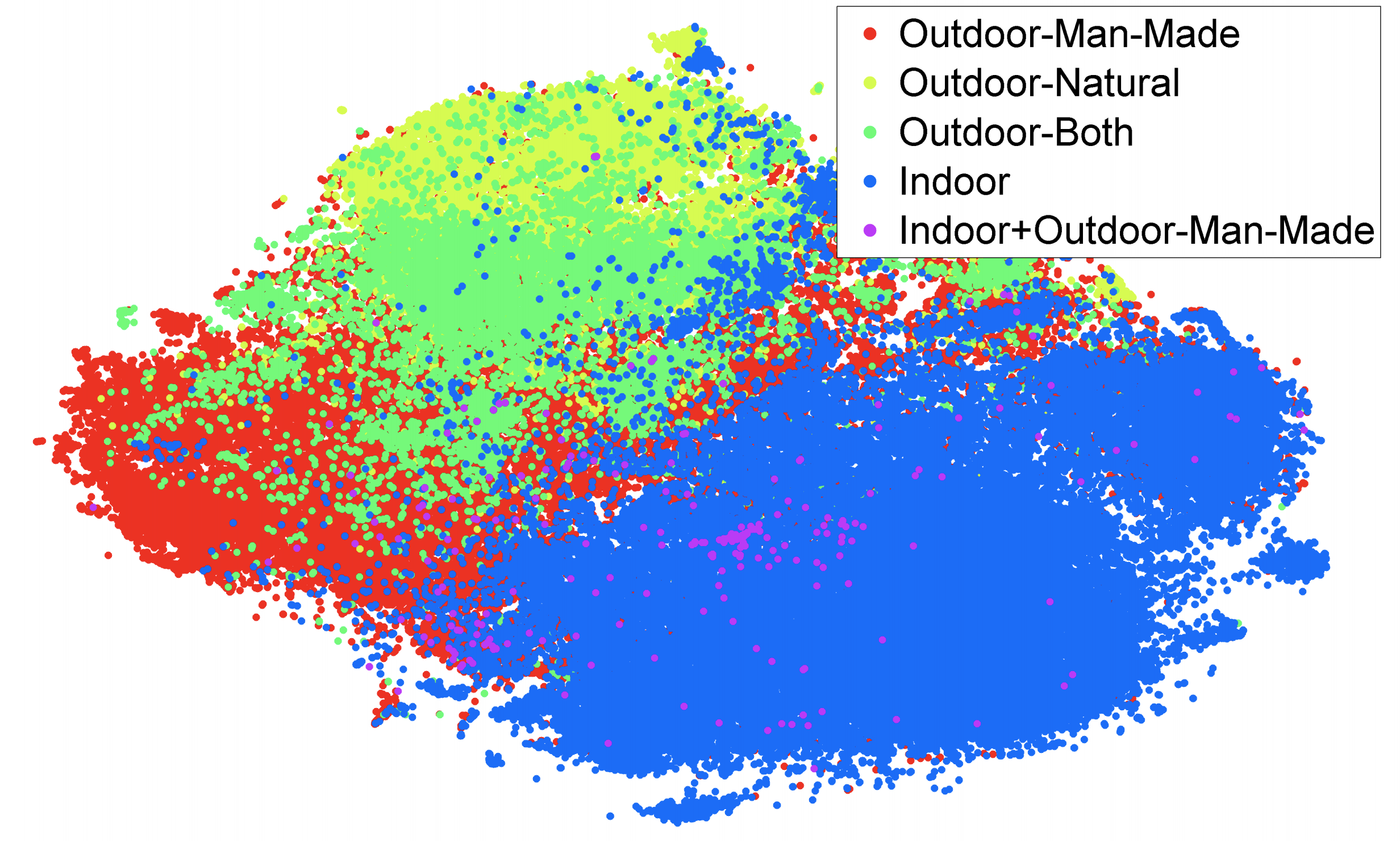
Quite than trying on the knowledge immediately, it’s extra prudent to probe what the fashions educated on the information be taught. It’s common information that options of deep neural networks educated on ImageNet transition from common to task-specific from the primary to the final layer: decrease layers be taught to mannequin low-level options similar to edges, whereas greater layers mannequin higher-level ideas similar to patterns and whole elements or objects as could be seen within the determine beneath. Importantly, information of edges, constructions, and the visible composition of objects is related for a lot of CV duties, which sheds mild on why these layers are transferred. A key property of an ImageNet-like dataset is thus to encourage a mannequin to be taught options that may doubtless generalize to new duties in the issue area.

Past this, it’s troublesome to make additional generalizations about why switch from ImageNet works fairly so effectively. For example, one other doable benefit of the ImageNet dataset is the standard of the information. ImageNet’s creators went to nice lengths to make sure dependable and constant annotations. Nonetheless, work in distant supervision serves as a counterpoint, indicating that giant quantities of weakly labelled knowledge may usually be enough. Actually, not too long ago researchers at Fb confirmed that they might pre-train a mannequin by predicting hashtags on billions of social media photos to state-of-the-art accuracy on ImageNet.
With none extra concrete insights, we’re left with two key desiderata:
-
An ImageNet-like dataset ought to be sufficiently massive, i.e. on the order of hundreds of thousands of coaching examples.
-
It ought to be consultant of the issue area of the self-discipline.
An ImageNet for language
In NLP, fashions are sometimes so much shallower than their CV counterparts. Evaluation of options has thus principally targeted on the primary embedding layer, and little work has investigated the properties of upper layers for switch studying. Allow us to take into account the datasets which might be massive sufficient, fulfilling desideratum #1. Given the present state of NLP, there are a number of contenders.
Studying comprehension is the duty of answering a pure language query a couple of paragraph. The preferred dataset for this job is the Stanford Query Answering Dataset (SQuAD), which incorporates greater than 100,000 question-answer pairs and asks fashions to reply a query by highlighting a span within the paragraph as could be seen beneath.

Pure language inference is the duty of figuring out the relation (entailment, contradiction, and impartial) that holds between a chunk of textual content and a speculation. The preferred dataset for this job, the Stanford Pure Language Inference (SNLI) Corpus, incorporates 570k human-written English sentence pairs. Examples of the dataset could be seen beneath.

Machine translation, translating textual content in a single language to textual content in one other language, is likely one of the most studied duties in NLP, and—over the years—has collected huge quantities of coaching knowledge for widespread language pairs, e.g. 40M English-French sentence pairs in WMT 2014. See beneath for 2 instance translation pairs.

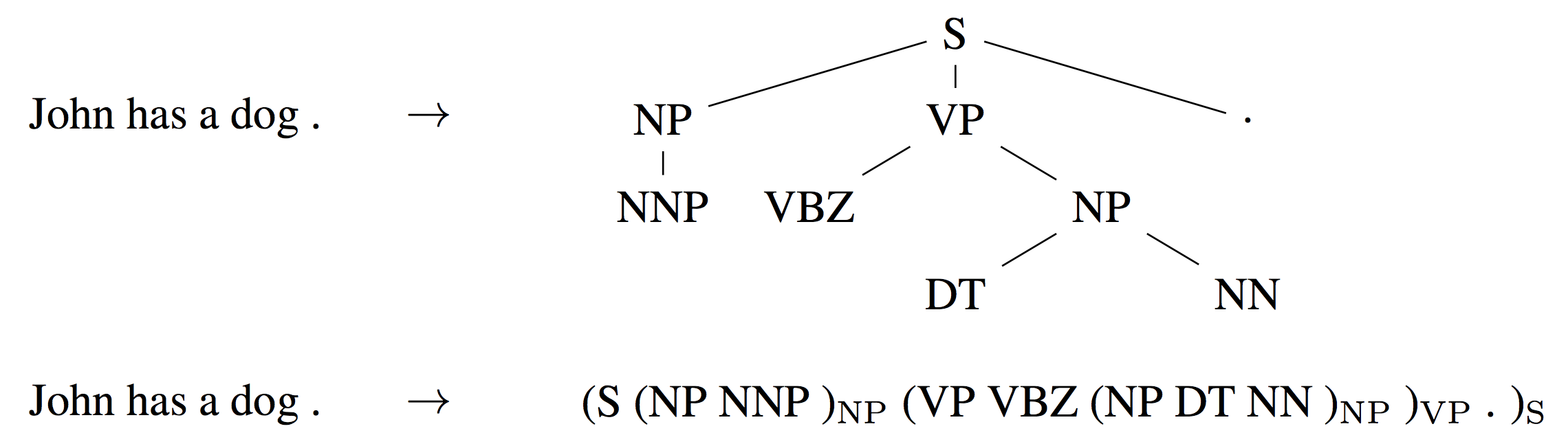
Constituency parsing seeks to extract the syntactic construction of a sentence within the type of a (linearized) constituency parse tree as could be seen beneath. Previously, hundreds of thousands of weakly labelled parses have been used for coaching sequence-to-sequence fashions for this job.
Language modeling (LM) goals to foretell the subsequent phrase given its earlier phrase. Present benchmark datasets include as much as 1B phrases, however as the duty is unsupervised, any variety of phrases can be utilized for coaching. See beneath for examples from the favored WikiText-2 dataset consisting of Wikipedia articles.

All of those duties provide—or would enable the gathering of—a enough variety of examples for coaching. Certainly, the above duties (and lots of others similar to sentiment evaluation, constituency parsing , skip-thoughts, and autoencoding) have been used to pretrain representations in latest months.
Whereas any knowledge incorporates some bias, human annotators could inadvertently introduce extra alerts {that a} mannequin can exploit. Latest research reveal that state-of-the-art fashions for duties similar to studying comprehension and pure language inference don’t the truth is exhibit deep pure language understanding however choose up on such cues to carry out superficial sample matching. For example, Gururangan et al. (2018) present that annotators have a tendency to supply entailment examples just by eradicating gender or quantity data and generate contradictions by introducing negations. A mannequin that merely exploits these cues can appropriately classify the speculation with out trying on the premise in about 67% of the SNLI dataset.
The tougher query thus is: Which job is most consultant of the area of NLP issues? In different phrases, which job permits us to be taught a lot of the information or relations required for understanding pure language?
The case for language modelling
With a purpose to predict probably the most possible subsequent phrase in a sentence, a mannequin is required not solely to have the ability to categorical syntax (the grammatical type of the expected phrase should match its modifier or verb) but additionally mannequin semantics. Much more, probably the most correct fashions should incorporate what could possibly be thought-about world information or widespread sense. Think about the unfinished sentence “The service was poor, however the meals was”. With a purpose to predict the succeeding phrase similar to “yummy” or “scrumptious”, the mannequin should not solely memorize what attributes are used to explain meals, but additionally be capable of establish that the conjunction “however” introduces a distinction, in order that the brand new attribute has the opposing sentiment of “poor”.
Language modelling, the final method talked about, has been proven to seize many aspects of language related for downstream duties, similar to long-term dependencies, hierarchical relations, and sentiment. In comparison with associated unsupervised duties similar to skip-thoughts and autoencoding, language modelling performs higher on syntactic duties even with much less coaching knowledge.
Among the many largest advantages of language modelling is that coaching knowledge comes without cost with any textual content corpus and that doubtlessly limitless quantities of coaching knowledge can be found. That is notably important, as NLP offers not solely with the English language. Greater than 4,500 languages are spoken around the globe by greater than 1,000 audio system. Language modeling as a pretraining job opens the door to growing fashions for beforehand underserved languages. For very low-resource languages the place even unlabeled knowledge is scarce, multilingual language fashions could also be educated on a number of associated languages directly, analogous to work on cross-lingual embeddings.
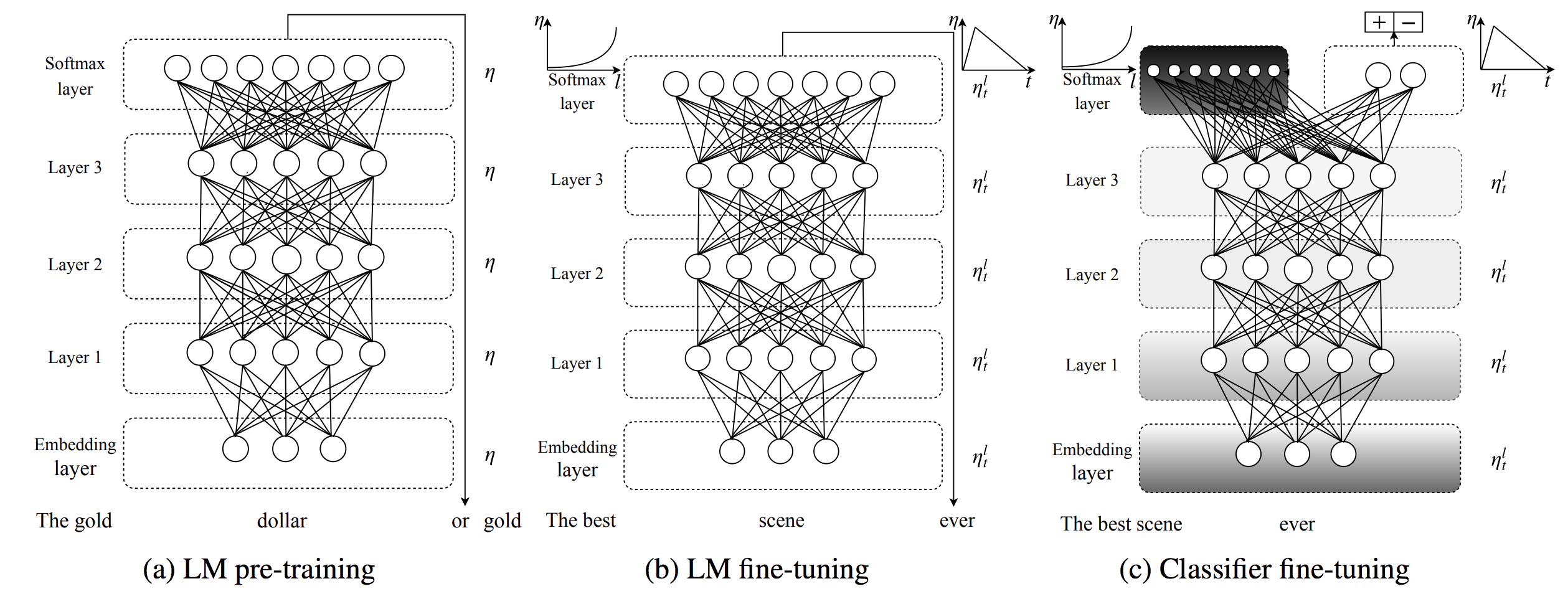
Thus far, our argument for language modeling as a pretraining job has been purely conceptual. Pretraining a language mannequin was first proposed in 2015 , nevertheless it remained unclear whether or not a single pretrained language mannequin was helpful for a lot of duties. In latest months, we lastly obtained overwhelming empirical proof: Embeddings from Language Fashions (ELMo), Common Language Mannequin High quality-tuning (ULMFiT), and the OpenAI Transformer have empirically demonstrated how language modeling can be utilized for pretraining, as proven by the above determine from ULMFiT. All three strategies employed pretrained language fashions to realize state-of-the-art on a various vary of duties in Pure Language Processing, together with textual content classification, query answering, pure language inference, coreference decision, sequence labeling, and lots of others.
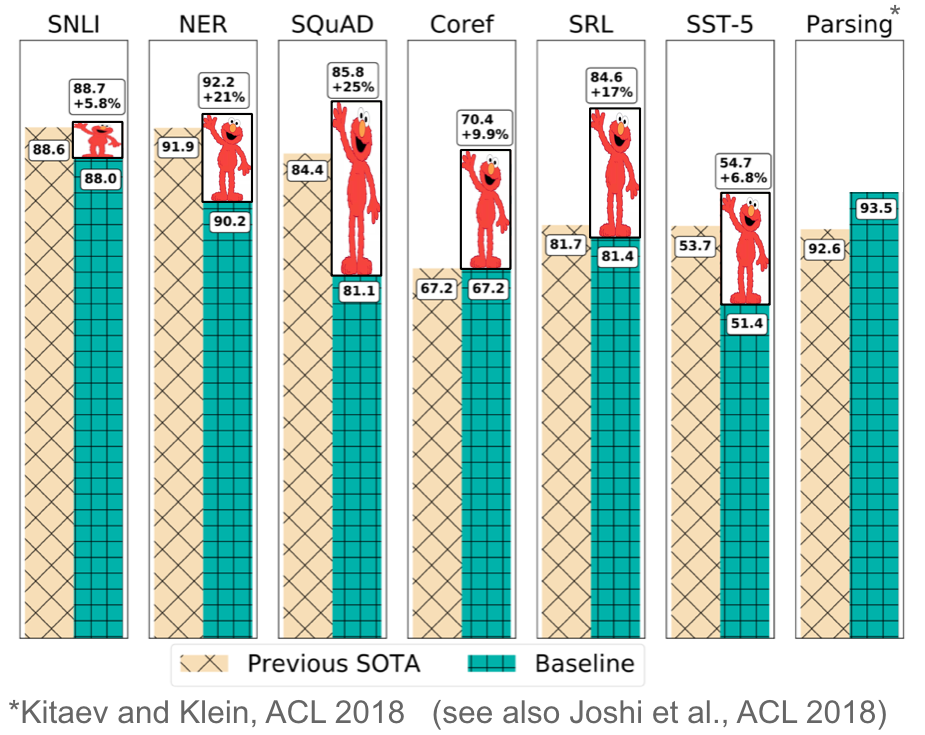
In lots of instances similar to with ELMo within the determine beneath, these enhancements ranged between 10-20% higher than the state-of-the-art on broadly studied benchmarks, all with the only core technique of leveraging a pretrained language mannequin. ELMo moreover received the perfect paper award at NAACL-HLT 2018, one of many prime conferences within the area. Lastly, these fashions have been proven to be extraordinarily sample-efficient, reaching good efficiency with solely a whole lot of examples and are even in a position to carry out zero-shot studying.
In mild of this step change, it is extremely doubtless that in a 12 months’s time NLP practitioners will obtain pretrained language fashions fairly than pretrained phrase embeddings to be used in their very own fashions, equally to how pre-trained ImageNet fashions are the place to begin for many CV initiatives these days.
Nonetheless, much like word2vec, the duty of language modeling naturally has its personal limitations: It is just a proxy to true language understanding, and a single monolithic mannequin is ill-equipped to seize the required data for sure downstream duties. For example, to be able to reply questions on or comply with the trajectory of characters in a narrative, a mannequin must be taught to carry out anaphora or coreference decision. As well as, language fashions can solely seize what they’ve seen. Sure sorts of data, similar to most typical sense information, are troublesome to be taught from textual content alone and require incorporating exterior data.
One excellent query is the right way to switch the data from a pre-trained language mannequin to a downstream job. The 2 important paradigms for this are whether or not to make use of the pre-trained language mannequin as a set function extractor and incorporate its illustration as options right into a randomly initialized mannequin as utilized in ELMo, or whether or not to fine-tune your complete language mannequin as carried out by ULMFiT. The latter fine-tuning method is what is often carried out in CV the place both the top-most or a number of of the highest layers are fine-tuned. Whereas NLP fashions are sometimes extra shallow and thus require totally different fine-tuning methods than their imaginative and prescient counterparts, latest pretrained fashions are getting deeper. The following months will present the affect of every of the core parts of switch studying for NLP: an expressive language mannequin encoder similar to a deep BiLSTM or the Transformer, the quantity and nature of the information used for pretraining, and the strategy used to fine-tune the pretrained mannequin.
However the place’s the speculation?
Our evaluation to this point has been principally conceptual and empirical, as it’s nonetheless poorly understood why fashions educated on ImageNet—and consequently on language modeling—transfer so effectively. A method to consider the generalization behaviour of pretrained fashions extra formally is underneath a mannequin of bias studying (Baxter, 2000)[35]. Assume our downside area covers all permutations of duties in a specific self-discipline, e.g. pc imaginative and prescient, which kinds our atmosphere. We’re supplied with numerous datasets that enable us to induce a household of speculation areas $mathrm{H} = {mathcal{H}}$. Our purpose in bias studying is to discover a bias, i.e. a speculation area $mathcal{H} in mathrm{H}$ that maximizes efficiency on your complete (doubtlessly infinite) atmosphere.
Empirical and theoretical leads to multi-task studying (Caruana, 1997; Baxter, 2000) point out {that a} bias that’s discovered on sufficiently many duties is more likely to generalize to unseen duties drawn from the identical atmosphere. Seen by way of the lens of multi-task studying, a mannequin educated on ImageNet learns a lot of binary classification duties (one for every class). These duties, all drawn from the area of pure, real-world photos, are more likely to be consultant of many different CV duties. In the identical vein, a language model—by studying a lot of classification duties, one for every word—induces representations which might be doubtless useful for a lot of different duties within the realm of pure language. Nonetheless, way more analysis is important to realize a greater theoretical understanding why language modeling appears to work so effectively for switch studying.
The ImageNet second
The time is ripe for sensible switch studying to make inroads into NLP. In mild of the spectacular empirical outcomes of ELMo, ULMFiT, and OpenAI it solely appears to be a query of time till pretrained phrase embeddings shall be dethroned and changed by pretrained language fashions within the toolbox of each NLP practitioner. It will doubtless open many new purposes for NLP in settings with restricted quantities of labeled knowledge. The king is lifeless, lengthy stay the king!
For additional studying, take a look at the dialogue on HackerNews.
Cowl picture as a result of Matthew Peters.
Quotation
For attribution in educational contexts or books, please cite this work as
Sebastian Ruder, "NLP's ImageNet second has arrived". https://ruder.io/nlp-imagenet/, 2018.
BibTeX quotation:
@misc{ruder2018nlpimagenet,
creator = {Ruder, Sebastian},
title = {{NLP's ImageNet second has arrived}},
12 months = {2018},
howpublished = {url{https://ruder.io/nlp-imagenet/}},
}

{kind=link}