
The Researchers from the Hong Kong College of Science and Know-how and WeBank developed an efficient framework named phonetic-semantic pre- coaching (PSP) reveals its energy in opposition to artificial extremely noisy speech datasets
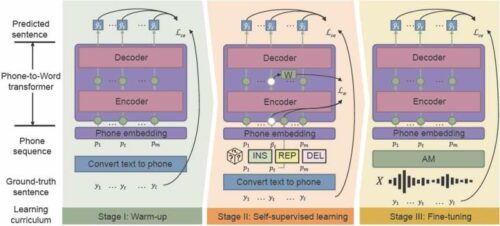
The phonetic-semantic pre-training (PSP) framework assists in recovering misclassified phrases and excels efficiency of computerized speech recognition (ASR). The mannequin converts the acoustic mannequin (AM) outputs on to a sentence with its full context info. Researchers developed a framework that may help the language fashions (LM) to precisely get well from the noisy outputs of the AM. The PSP framework permits the mannequin to enhance via a pretraining regime known as a noise-aware curriculum that slowly introduces new abilities, initially with simple duties after which steadily transferring to advanced duties.
“Robustness is a long-standing problem for ASR,” mentioned Xueyang Wu from the Hong Kong College of Science and Know-how Division of Laptop Science and Engineering. “We wish to enhance the robustness of the Chinese language ASR system with a low price”. The standard methodology trains the acoustic and language fashions that comprise ASR and requires massive quantities of noise-specific knowledge, this ends in a pricey and time-consuming course of. “Conventional studying fashions will not be strong in opposition to noisy acoustic mannequin outputs, particularly for Chinese language polyphonic phrases with an identical pronunciation,” Wu mentioned. “If the primary move of the training mannequin decoding is wrong, this can be very laborious for the second move to make it up.”
The researcher practice transducer in two levels: 1) the place researchers pre-train a phone-to-word transducer on a clear telephone sequence, that’s transformed from unlabeled textual content knowledge solely to chop again on the annotation time. On this stage, the mannequin initializes the essential parameters to map telephone sequences to phrases. 2) 2nd stage is thought to be self-supervised studying, the transducer learns from extra advanced knowledge produced by self-supervised coaching methods and features. Therefore, the resultant phone-to-word transducer is fine-tuned with real-world speech knowledge. The standard methodology trains the acoustic and language fashions that comprise ASR and requires massive quantities of noise-specific knowledge, this ends in a pricey and time-consuming course of.
“Essentially the most essential a part of our proposed methodology, Noise-aware Curriculum Studying, simulates the mechanism of how human beings acknowledge a sentence from noisy speech,” Wu mentioned. The researchers purpose to develop more practical PSP pre-training strategies with bigger unpaired datasets to maximise the effectiveness of pretraining for noise-robust LM.
Click on right here for the Revealed Analysis Paper

{kind=link}