From information preparation to mannequin coaching for NER duties — and the way to tag your personal sentences
These days, NLP has grow to be synonymous with Deep Studying.
However, Deep Studying is just not the ‘magic bullet’ for each NLP activity. For instance, in sentence classification duties, a easy linear classifier may work moderately effectively. Particularly when you have a small coaching dataset.
Nonetheless, some NLP duties flourish with Deep Studying. One such activity is Named Entity Recognition — NER:
NER is the method of figuring out and classifying named entities into predefined entity classes.
As an illustration, within the sentence:
Nick lives in Greece and works a Knowledge Scientist.
Now we have 2 entities:
- Nick, which is a ‘Particular person’.
- Greece, which is a ‘Location’.
Subsequently, given the above sentence, a classifier ought to have the ability to find the 2 phrases (‘Nick’, ‘Greece’) and appropriately classify them as ‘Particular person’ and ‘Location’ respectively.
On this tutorial, we are going to construct a NER mannequin, utilizing HugginFace Transformers.
Let’s dive in!
We’ll use the wnut_17[1] dataset that’s already included within the HugginFace Datasets library.
Discover the dataset
This dataset focuses on figuring out uncommon, previously-unseen entities within the context of rising discussions. It comprises 5690 paperwork, partitioned into coaching, validation, and take a look at units. The textual content sentences are tokenized into phrases. Let’s load the dataset:
wnut = load_dataset(“wnut_17”)
We get the next:
Subsequent, we print the ner_tags — the predefined entities of our mannequin:
Every ner_tag describes an entity. It may be one of many following: company, creative-work, group, location, individual, and product.
The letter that prefixes every ner_tag signifies the token place of the entity:
- B– signifies the start of an entity.
- I– signifies a token is contained inside the identical entity (e.g., the “York” token is part of the “New York” entity).
- 0 signifies the token doesn’t correspond to any entity.
We additionally created the id2tag dictionary that maps every label to its ner_tag — this can turn out to be useful later.
Reorganize prepare & validation datasets
Our dataset is just not that enormous. Keep in mind, Transformers require plenty of information to benefit from their superior efficiency.
To unravel this problem, we concatenate coaching and validation datasets right into a single coaching dataset. The take a look at dataset will stay as-is for validation functions:
A coaching instance
Let’s print the third coaching instance from our dataset. We’ll use that instance as a reference all through this tutorial:
The ‘Pxleyes’ token is classed as B-corporation (the start of a company). The remainder of the tokens are irrelevant — they don’t characterize any entity.
Subsequent, we tokenize our information. Opposite to different use instances, tokenization for NER duties requires particular dealing with.
We’ll use the bert-base-uncased mannequin and tokenizer from the HugginFace library.
Transformer fashions principally use sub-word-based tokenizers.
Throughout tokenization, some phrases could possibly be break up into two or extra phrases. This can be a normal observe as a result of uncommon phrases could possibly be decomposed into significant tokens. For instance, BERT fashions implement by default the Byte-Pair Encoding (BPE) tokenization.
Let’s tokenize our pattern coaching instance to see how this works:
That is the unique coaching instance:
And that is how the coaching instance is tokenized by BERT’s tokenizer:
Discover that there are two vital points:
- The particular tokens
[CLS]and[SEP]are added. - The token “Pxleyes” is break up into 3 sub-tokens :
p,##xleyand##es.
In different phrases, the tokenization creates a mismatch between the inputs and the labels. Therefore, we realign tokens and labels within the following method:
- Every single phrase token is mapped to its corresponding
ner_tag. - We assign the label
-100to the particular tokens[CLS]and[SEP]so the loss perform ignores them. By default, PyTorch ignores the-100worth throughout loss calculation. - For subwords, we solely label the primary token of a given phrase. Thus, we assign
-100to different subtokens from the identical phrase.
For instance, the token Pxleyes is labeled as 1 (B-corporation). It’s tokenized as [‘p’, ‘##xley’, ‘##es’] and after token alignment the labels ought to grow to be [1, -100, -100]
We implement this performance within the tokenize_and_align_labels() perform:
And that’s it! Let’s name our customized tokenization perform:
The desk under reveals precisely the tokenization output for our pattern coaching instance:
We are actually able to construct our Deep Studying mannequin.
We load the bert-base-uncased pretrained mannequin and fine-tune it utilizing our information.
However first, we should always prepare a naive classifier to make use of as a baseline mannequin.
Baseline Mannequin
The obvious selection for a baseline classifier is to tag each token with essentially the most frequent entity all through the whole coaching dataset— the O entity:
The baseline classifier turns into much less naive if we tag every token with essentially the most frequent label of the sentence it belongs:
Subsequently, we use the second mannequin as a baseline.
BERT for Named Entity Recognition
The Knowledge Collator batches coaching examples collectively whereas making use of padding to make all of them the identical dimension. The collator pads not solely the inputs but in addition the labels:
Concerning analysis, since our dataset is imbalanced, we will’t rely solely on accuracy.
Subsequently, we may also measure precision and recall. Right here, we are going to load the seqeval metric which is included within the datasets library. This metric is often used for POS (Half-of-speech) tagging and NER duties.
Let’s apply it to our reference coaching instance and see how this works:
Word: Keep in mind, the loss perform ignores all tokens tagged with -100 throughout coaching. Our analysis perform also needs to consider this data.
Therefore, the compute_metrics perform is outlined a bit in a different way — we calculate precision, recall, f1-score, and accuracy by ignoring the whole lot tagged with -100:
Lastly, we instantiate the Coach class to fine-tune our mannequin. Discover the utilization of the EarlyStopping callback:
These are our coaching metrics:
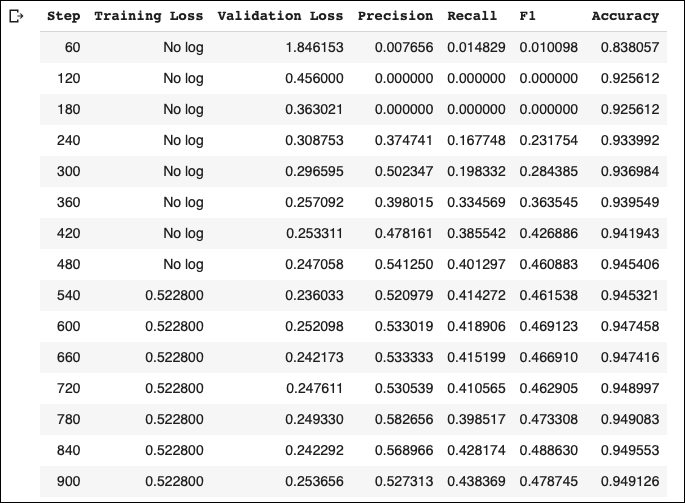
The mannequin achieves significantly better validation accuracy in comparison with the baseline mannequin. Additionally, we will obtain a greater f1-score if we use a bigger mannequin, or let the mannequin prepare for extra epochs with out making use of the EarlyStopping callback.
We use the identical methodology as earlier than for our take a look at set.
The seqeval metric additionally outputs the per-class metrics:
The location and individual entities obtain the very best scores, whereas group has the bottom rating.
Lastly, we create a perform that performs entity recognition on our personal sentences:
Let’s strive a couple of examples:
The mannequin has efficiently tagged the 2 nations! Check out the United States:
- “United” was appropriately tagged as
B-location. - “States” was appropriately tagged as
I-location.
Once more, Apple was appropriately tagged as a company. Additionally, our mannequin appropriately recognized and acknowledged the Apple merchandise.
Named Entity Recognition is a basic NLP activity that has quite a few sensible functions.
Despite the fact that the HugginFace library has created a super-friendly API for this course of, there are nonetheless a couple of factors of confusion.
I hope this tutorial has shed some mild on them. The supply code of this text could be discovered right here
