
Creating scalable, reproducible, strong and effectively monitored machine studying pipelines

The aim of this venture is to make use of a knowledge pushed method and machine studying to supply personalised and contextualised companies and a clean journey expertise to Ruter’s prospects. We wish our prospects to know the way full a automobile goes to be for the journey they’re planning to take, in order that they will make extra knowledgeable selections primarily based on the data we offer.
Ruter offers public transportation companies, by way of busses, trams, metros and boats, round Oslo and Viken areas in Norway. It serves round half 1,000,000 departures every day, masking about 300,000 km and transporting round 1,000,000 passengers every day. We gather uncooked information from the IoT sensors on board our buses, trams, and metros. These sensors repeatedly report totally different sorts of information, together with the variety of boarding and alighting passengers, inside/outdoors temperatures, and the pace and place of automobiles in real-time. All this real-time streaming information from the whole fleet of Ruter is ingested, processed, and saved in real-time by in-house developed backend programs.

This huge quantity of information collected tells solely half the story, i.e., what has occurred previously. To realize our aim of offering personalised and contextualised companies and a clean journey expertise, we should be capable of inform our prospects about what’s more likely to occur sooner or later as effectively. We leverage huge information, machine studying and AI to forecast and predict these future occasions.
Ruter makes use of AI in a number of areas, for instance, to foretell capability, passenger counts, and journey patterns. AI can be used to deal with buyer inquiries and to optimise site visitors routes for our on-demand service. To maximise the achieve from utilizing AI, we must always be capable of transfer past PowerPoint shows and feasibility stories and should be capable of flip concepts into value-generating functions rapidly.
We use AWS as our public cloud supplier and software and machine studying platform. We leverage Kafka and EKS (Amazon Elastic Kubernetes Service) for our real-time programs and S3, Glue, Athena and SageMaker for our historic, analytical, and AI use instances. We’re going to dive into the latter.
Based on VentureBeat, round 87% of machine studying fashions by no means make it to manufacturing. A lot of those who make it, don’t stay in manufacturing for lengthy as a result of they cannot adapt to the altering atmosphere quick sufficient. One of many causes for this limitation is the dearth of a sturdy machine studying(ml) platform. In Ruter, we’ve invested in a contemporary cloud (AWS) primarily based machine studying platform which allows us to ship our ml fashions at pace and with high quality. It’s constructed round MLOps ideas and allows us to supply strong, scalable, reproducible and monitored ml pipelines.
On this article, we’re going to focus on what our typical machine studying pipeline appears like.
The machine studying group in Ruter is liable for the end-to-end lifecycle of its machine studying fashions, all the best way from information ingestion to mannequin deployment and inference and making these insights and predictions out there to different groups by way of Kafka. We comply with the “we construct it — we function it” mindset. Since we’re those who develop these machine studying fashions, we all know how they need to be monitored and stuck, and the way their efficiency ought to be measured. Therefore, it’s best that we function and handle the machine studying pipelines ourselves as an alternative of handing them over to an exterior IT group for deployment. This fashion we keep away from including superfluous dependencies.
As talked about earlier, we use AWS as our machine studying platform. We use further instruments to implement our ml pipelines: GitLab, Terraform, Python and GreatExpectations to call a couple of. We use GitLab for model management, growth and CI/CD, Terraform for implementing infrastructure-as-code, Python to outline pipeline definitions and GreatExpectations for information high quality monitoring.
We began with our first machine studying pipeline within the first quarter of 2021. The pipeline would spin off AWS EC2’s (AWS digital machines) cases for mannequin coaching, batch predictions and publishing these predictions on Kafka. As you might need observed, this pipeline was the naked minimal. It was not reproducible, scalable, strong or monitored. We wanted one thing higher than this to extend pace, add robustness and improve the developer expertise. After going again to the drafting board and going by means of a couple of iterations, we got here up with the pipeline proven beneath.

The pipeline consisted of the next elements.
Occasion Bridge: Amazon EventBridge is a serverless occasion bus that makes it simpler to construct event-driven functions at scale utilizing occasions generated from functions. We used it to set off our ml pipelines at particular occasions. Primarily based on the set time, it begins a lambda.
AWS Lambda: AWS Lambda is a serverless, event-driven compute service which triggered AWS step features with {custom} enter parameters.
AWS Step Features: AWS Step Features is a low-code workflow service which we used to orchestrate steps in our machine studying pipelines.
SageMaker Processing and Coaching Jobs: We used SageMaker processing jobs for numerous information processing jobs. For instance, information loading from S3 and our information warehouse, information cleansing and have extraction, information high quality management, batch inference and publishing outcomes on Kafka. We used SageMaker coaching jobs for mannequin coaching.
S3: We used S3 for artefact storage. There we saved snapshots of uncooked enter information, extracted options, information high quality outcomes and stories and fashions.
Whereas AWS Step Features is an efficient software for orchestrating common workflows and state machines, we discovered it to be non-ideal for the machine studying pipelines as a result of
- AWS Step Features are applied utilizing Amazon Stage Language. It’s a JSON-based structured language used to outline a state machine. This meant we had so as to add yet one more language in our toolset to implement and preserve pipelines utilizing AWS Step Features. Since Amazon State Language lowers complexity for its customers, it additionally reduces flexibility and management.
- AWS step features dealing with of pipeline failures is suboptimal. If a step within the pipeline fails, you can’t simply rerun the failed step and begin the place you left off. You would need to restart the entire pipeline.
- AWS step features don’t present machine learning-specific options, corresponding to experiment monitoring, mannequin registry and endpoints out of the field.
We migrated our pipelines to SageMaker pipelines which offer the lacking options and deal with the restrictions of StepFunctions:
- You’ll be able to outline a whole pipeline in Python, which feels at dwelling for Information scientists and ML Engineers.
- If a step fails within the pipeline, you may retry the pipeline, and it could begin from the place it left off on failure.
- SageMaker pipeline offers options like experiment monitoring, mannequin registry and endpoints out of the field.
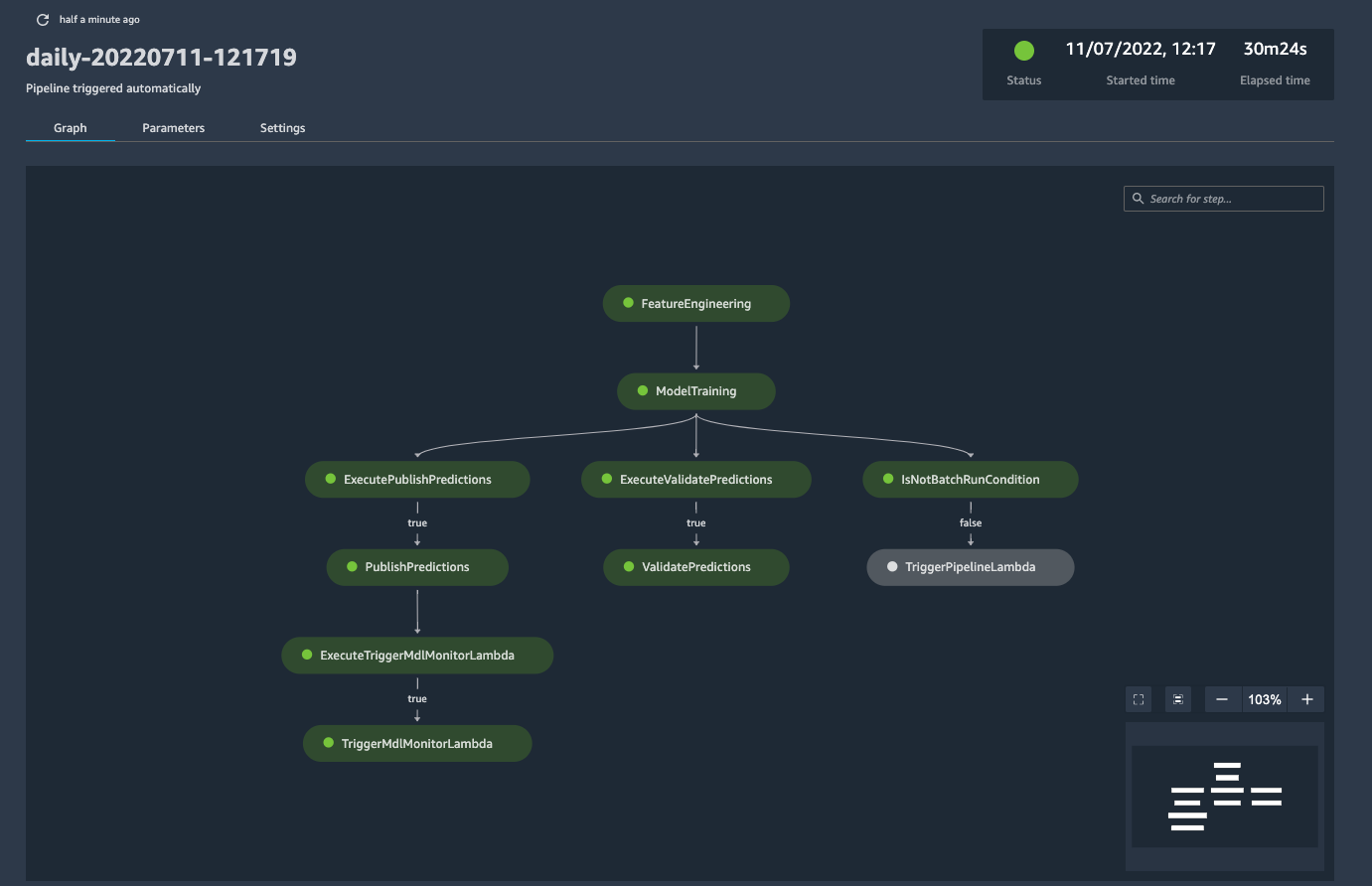
Our present typical pipeline with batch inference appears like this.

Every step in these pipelines emits logs and metrics utilizing AWS CloudWatch, AWS’s default monitoring and observability service. From these logs and metrics, alerts are generated and forwarded to project-specific Slack channels. This ensures that we’re the primary to learn about any outage or failure. We both repair the problem earlier than our downstream customers discover it, or we will notify them prematurely if the repair takes time. The metrics are additionally displayed in dashboards (we use each Cloudwatch and DataDog) which helps us monitor the pipelines and debug the problems successfully. Moreover, every step is configured with exponential backoff and retries. If a step fails, it’ll retry a configurable variety of occasions earlier than it offers up and fails the entire pipeline.
One other good thing about utilizing SageMaker pipelines is the SageMaker Studio. It offers a single, web-based visible interface the place you may carry out all ML growth steps, bettering information science group productiveness. Utilizing the studio, we will have an outline of all our pipelines. We get the standing of present and all earlier executions, together with their begin and run occasions. We will additionally discover pipeline parameters, container variations and so on., for every execution. We will additionally retry failed pipeline executions, begin new executions or examine a earlier run. Every pipeline execution is locked to a snapshot of the info used for coaching and inference. Leveraging SageMaker and information snapshots, we will rerun a beforehand executed pipeline with the very same information, fashions and parameters.
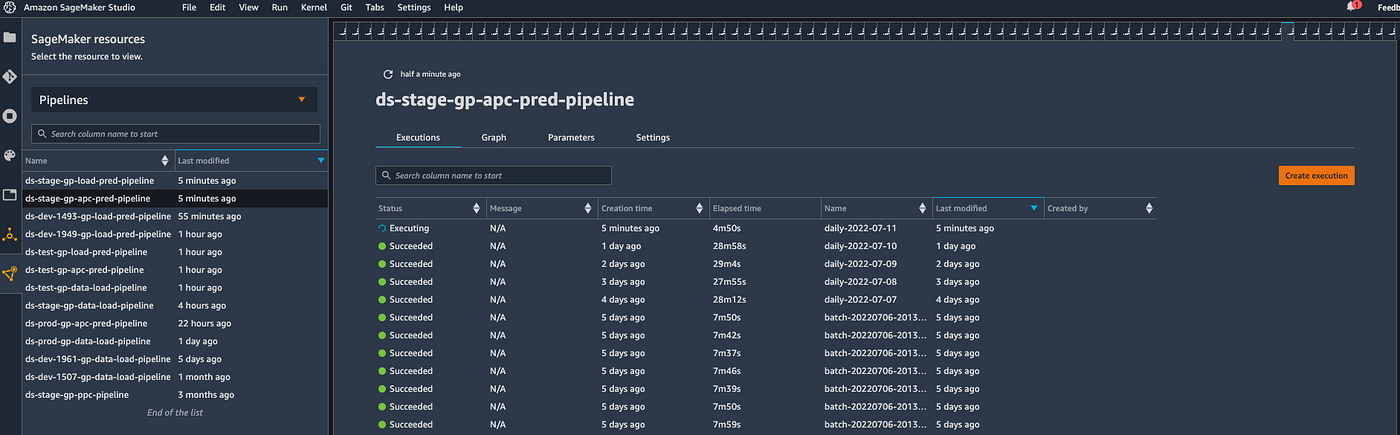
It’s price mentioning that regardless that SageMaker offers a lot of options, we use SageMaker pipelines soberly, solely utilizing the options we imagine add worth to our companies and use instances. There’s nonetheless rather a lot to discover and check out from the whole set of options it offers.
We use Terraform, an open supply infrastructure as a code (IAC) software, for all our cloud infrastructure and pipeline implementations. We comply with commonplace DevOps practices, and Terraform allows us to have a precise copy of infrastructure in our dev, take a look at, stage and prod environments.
Sadly, the AWS Terraform supplier doesn’t (as of August 2022) have a SageMaker pipeline useful resource. To avoid this challenge, we use the AWSCC Terraform supplier, which does have a SageMaker pipeline useful resource, to deploy our pipelines.
As talked about above, we outline our pipelines utilizing Python, i.e. the SageMaker Pipelines Python SDK. We create a Python script with the pipeline definition, which returns a pipeline definition as JSON when run. This script is executed by Terraform by means of an exterior information supply, and the returned pipeline definition is shipped to the AWSCC SageMaker pipeline useful resource. This fashion, we maintain our SageMaker pipelines managed by Terraform whereas concurrently permitting us to put in writing the pipeline definition utilizing Python.

We use GitLab CI/CD with Terraform to construct, change and handle our infrastructure and pipelines. We’ve designed the setup in such a method that when a developer creates a brand new growth department, GitLab CI/CD robotically creates a wholly remoted and sandboxed growth infrastructure for that venture. Builders can then use this dev infrastructure for growth and experimentation functions with out worrying about sources or affecting some other companies. As soon as the event is accomplished, and the dev department is merged into the take a look at department (we use take a look at, stage and foremost branches for infrastructure), the dev infrastructure, together with all of its sources and information, is destroyed by the GitLab CI/CD. This provides our builders the flexibleness and pace they should work in a modular vogue and reduces the brink for experimentation and attempting out new concepts.
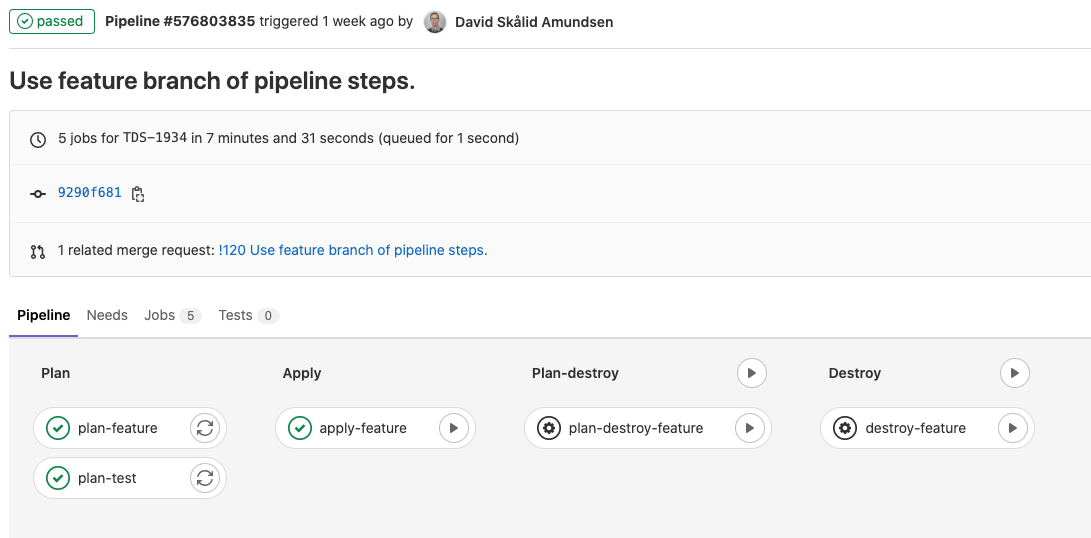
To date, so good. We’ve full management of our pipelines and workflows. If one thing goes fallacious, whether or not it’s an exterior API failure, information high quality challenge or failing jobs, we’ve programs to inform us instantly by way of Slack channels and electronic mail. However as soon as the mannequin will get deployed and is out within the wild, how do we all know if it produces good high quality predictions and beneficial data?
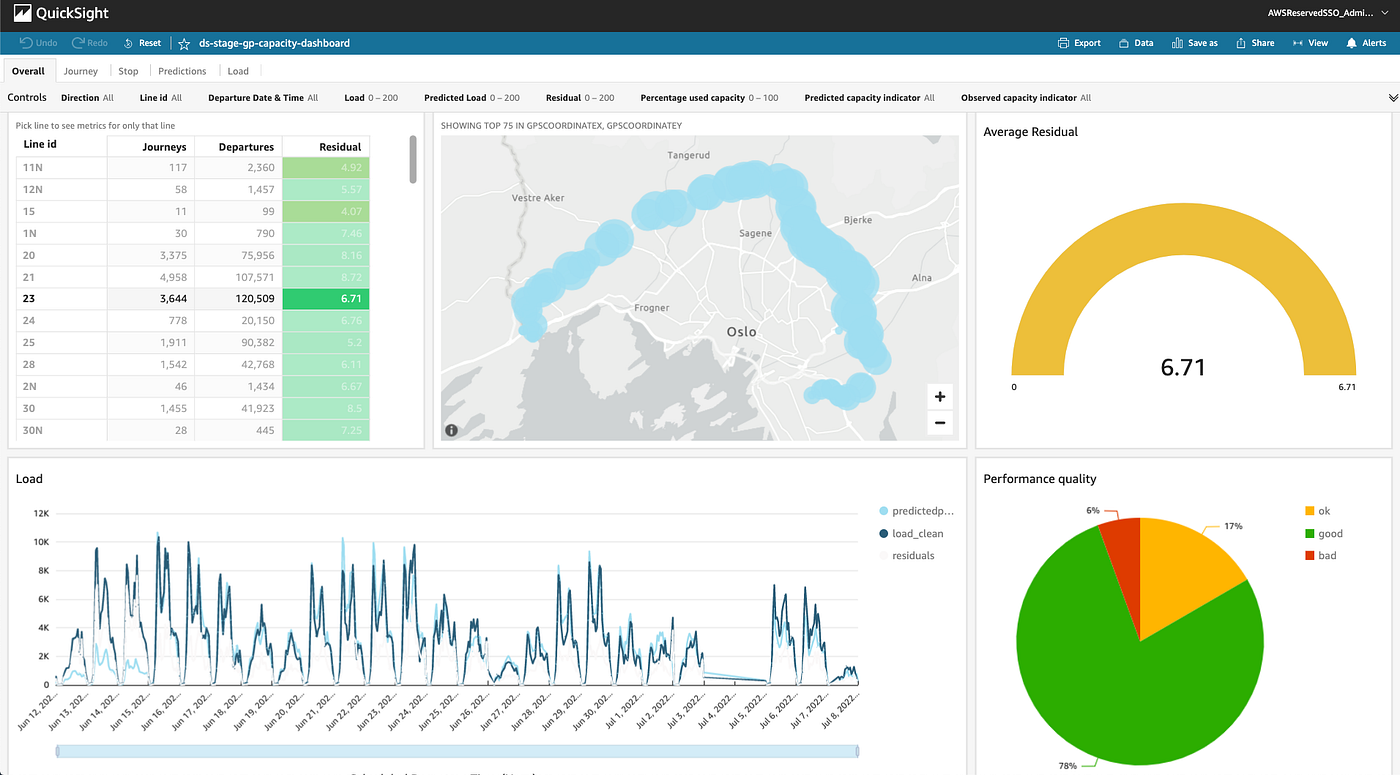
To reply this query, we’ve used one more AWS service. We use Amazon QuickSight to energy our mannequin efficiency monitoring dashboards. These dashboards show the predictions produced by our ml fashions and the bottom fact (because it arrives) together with custom-generated metrics, which helps us consider the efficiency of the ml fashions dwell in motion. Utilizing this dashboard, we will, for instance, drill right down to the person departures and examine if the mannequin predicted the right variety of onboard passengers for these departures. We additionally monitor mannequin drift, and QuickSight triggers an alarm if the mannequin drifts past an outlined threshold. Since all of the backend processing for these dashboards is applied in Terraform, we will carry out A/B testing by having growth dashboards auto-generated for our growth branches. This brings lots of energy to our builders, who can work with a number of experiments, every with its related dashboard to watch the efficiency of their ml fashions dwell in manufacturing.
We’re fairly content material with the present state of our the platform and pipelines, however there’s room for enchancment. We’re at the moment not utilizing SageMaker to its full potential and there are nonetheless some options which we imagine might add worth to our current pipelines and workflows. For instance, we want to use SageMaker extra actively for experiment monitoring. One other characteristic which we want to check out is utilizing Amazon SageMaker Function Retailer, which is a totally managed, purpose-built repository to retailer, share, and handle options for machine studying (ML) fashions. Enhancing developer’s expertise (including pace and decreasing complexity) is a main focus for our future developments and enhancements.

{kind=link}