Enhance the efficiency of your Python-trained ML fashions by serving them over your Kafka streaming platform in a Scala software
Suppose you may have a sturdy streaming platform primarily based on Kafka, which cleans and enriches your prospects’ occasion knowledge earlier than writing it to some warehouse. At some point, throughout an off-the-cuff planning assembly, your product supervisor raises the requirement to make use of a machine studying mannequin (developed by the information science staff) over incoming knowledge and generate an alert for messages marked by the mannequin. “No drawback”, you reply. “We will choose any knowledge set we would like from the information warehouse, after which run no matter mannequin we would like”. “Not precisely”, the PM replies. “We would like this to run as real-time as attainable. We would like the outcomes of the ML mannequin to be accessible for consumption in a Kafka subject in lower than a minute after we obtain the occasion”.
It is a widespread requirement, and it’ll solely get extra standard. The requirement for actual time ML inference on streaming knowledge turns into vital for a lot of prospects that should make time-sensitive selections on the results of the mannequin.
Plainly large knowledge engineering and knowledge science play properly collectively and will have some simple answer, however typically that isn’t the case, and utilizing ML for close to actual time inference over heavy workloads of knowledge includes fairly just a few challenges. Amongst these challenges, for instance, is the distinction between Python, which is the dominant language of ML, and the JVM atmosphere (Java/Scala) which is the dominant atmosphere for large knowledge engineering and knowledge streaming. One other problem pertains to the information platform we’re utilizing for our workloads. If you’re already working with Spark then you may have the Spark ML lib at your service, however generally it won’t be ok, and generally (as in our case) Spark is just not a part of our stack or infra.
Its true that the ecosystem is conscious of those challenges and is slowly addressing them with new options, although our particular and customary situation presently leaves you with just a few widespread choices. One, for instance, is so as to add Spark to your stack and write a pySpark job that can add the ML inference stage to your pipeline. That is will provide higher assist for Python in your knowledge science staff but it surely additionally implies that your knowledge processing stream may take longer and that you just additionally want so as to add and preserve a Spark cluster to your stack. Another choice could be to make use of some third-party mannequin serving platform that can expose an inference service endpoint primarily based in your mannequin. This may aid you retain your efficiency however may additionally require the price of further infra whereas being an overkill for the some duties.
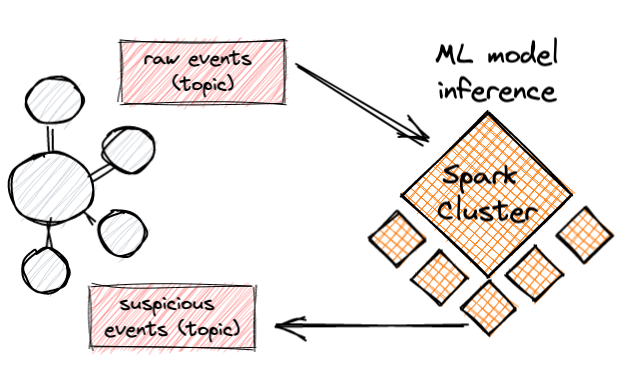
On this submit, I need to present one other strategy to this activity utilizing Kafka Streams. The benefit of utilizing Kafka Streams for this activity is that in contrast to Flink or Spark, it doesn’t require a devoted compute cluster. Fairly, it might run on any software server or container atmosphere you’re already utilizing, and in case you are already utilizing Kafka for stream processing, then it may be embedded in your stream fairly seamlessly.
Whereas each Spark and Flink have their machine studying libraries and tutorials, utilizing Kafka Streams for this activity looks like a much less widespread use case , and my aim is to point out how simple it’s to implement. Particularly, I present how we will use an XGBoost mannequin — a manufacturing grade machine studying mannequin, skilled in a Python atmosphere, for actual time inference over a stream of occasions on a Kafka subject.
That is meant to be a really hands-on submit. In Part 2, we prepare an XGBoost classifier on a fraud detection dateset. We accomplish that in a Jupyter pocket book in a Python atmosphere. Part 3 is an instance for the way the mannequin’s binary may be imported and wrapped in a Scala class, and Part 4 reveals how this may be embedded in a Kafka Stream software and generate actual time prediction on streaming knowledge. On the finish of the submit you could find a hyperlink to a repo with the total code described right here.
( Word that in lots of circumstances I take advantage of Scala in a really non-idiomatic method. I accomplish that for the sake of readability as idiomatic Scala can generally be complicated. )
For this instance, we begin by coaching a easy classification mannequin primarily based on the Kaggle credit score fraud knowledge set.¹ Yow will discover the total mannequin coaching code right here. The vital bit (beneath) is that after we (or our knowledge scientists) are happy with the outcomes of our mannequin, we merely reserve it in its easy binary kind. This binary is all we have to load the mannequin in our Kafka Streams app.
On this part we begin implementing our Kafka Streams software by first wrapping our machine studying mannequin in a Scala object (a singleton), which we are going to use to run inference on incoming data. This object will implement a predict() technique that our stream processing software will use over every of the streaming occasions. The strategy will obtain a file ID and an array of fields or options and can return a tuple that consists of the file id and the rating the mannequin gave it.
XGBoost mannequin loading and prediction in Scala is fairly simple (although it needs to be famous that assist in newer Scala variations is perhaps restricted). After preliminary imports, we begin by loading the *skilled* mannequin to a Booster variable.
Implementing the predict() technique can be pretty easy. Every of our occasions accommodates an array of 10 options or fields that we might want to present as enter to our mannequin.
The article sort that XGboost makes use of to wrap the enter vector for prediction is a DMatrix, which may be constructed in quite a lot of methods. I’ll use the dense matrix format, which relies on offering a flat array of floats that represents the mannequin options or fields; the size of every vector (nCols); and the numbers of vectors within the knowledge set (nRows). For instance, if our mannequin is used to run inference on a vector with 10 options or fields, and we need to predict one vector at a time, then our DMatrix will probably be instantiated with an array of floats with size = 10, nCols = 10, and nRows = 1 (as a result of there is just one vector within the set).
That can do the work for our Classifier object that wraps a skilled XGboost ML mannequin. There will probably be one Classifier object with a predict() technique that will probably be known as for every file.
Earlier than we get into the code and particulars of our streaming software and present how we will use our Classifier on streaming knowledge, its vital to focus on the benefit and motivation of utilizing Kafka Streams in such a system.
With Spark, only for instance, distribution of compute is finished by a cluster supervisor, that receives directions from a driver software and distributes compute duties to executors nodes in a devoted cluster. Every Spark executor is accountable to course of a set of partitions of the information. The facility of Kafka Streams (KS) is that though it equally achieves scale with parallelism — i.e., by working a number of replicas of the stream processing app, it doesn’t rely upon a devoted cluster for that, however solely on Kafka. In different phrases, the lifecycle of the compute nodes may be managed by any container orchestration system (akin to K8S) or some other software server whereas leaving the coordination and administration to Kafka (and the KS library). This may increasingly appear to be a minor benefit, however that is precisely Spark’s best ache.
Certainly, in contrast to Spark, KS is a library that may be imported into any JVM-based software and, most significantly, run on any software infrastructure. A KS software sometimes reads streaming messages from a Kafka subject, performs its transformations, and writes the outcomes to an output subject. State and stateful transformations, akin to aggregations or windowed computations, are persevered and managed by Kafka, and scale is achieved by merely working extra cases of your software (restricted by the variety of partitions the subject has and the patron coverage).
The idea of a KS app is a Topology, which defines the stream processing logic of the appliance or how enter knowledge is remodeled into output knowledge. In our case, the topology will run as follows
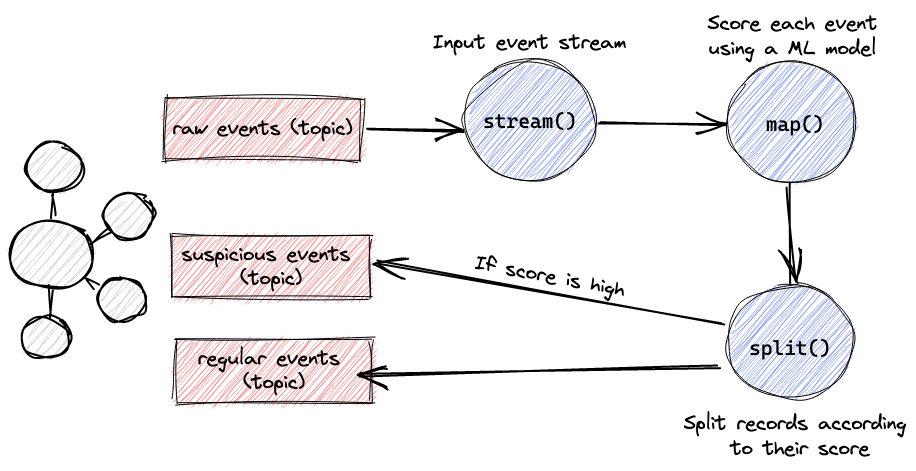
The topology right here is pretty easy. It begins by studying streaming data from the enter subject on Kafka, then it makes use of a map operation to run the mannequin’s predict technique on every file, and eventually it splits the stream, and sends file ids that recived a excessive rating from the mannequin to a “suspicious occasions” output subject and the remaining to a different. Lets see how this seems to be in code.
Our start line is the builder.stream technique which begins studying messages from inputTopic subject on Kafka. I’ll shortly clarify it extra, however notice that we’re serializing every kafka file key as String and its payload as an object of sort PredictRequest. PredictRequest is a Scala case class that corresponds to the protobuf schema beneath. This ensures that integration with message producers is straight ahead but additionally makes is less complicated to generate the de/serialization strategies that we’re required to offer when coping with customized objects.
message PredictRequest{
string recordID = 1;
repeated float featuresVector = 4;
}
Subsequent, we use map() to name our classifier’s predict() technique on the array that every message carries. Recall that this technique returns a tuple of recordID and rating, which is streamed again from the map operation. Lastly, we use the cut up() technique to create 2 branches of the stream — one for outcomes larger than 0.5 and one for the others. We then ship every department of the stream to their very own designated subject. Any shopper subsribed to the output subject will now recieve an alert for a suspicious file id (hopefully) close to actual time
One final touch upon serialization:
Utilizing customized lessons or objects in a KS app written in Scala, both for the important thing or the worth of the Kafka file, requires you to make accessible an implicit Serde[T] for the kind (which incorporates its serializer and deserializer). Since I used a proto object because the message payload, a lot of the heavy lifting was performed by scalapbc which “compiles” a proto schema to a Scala class that already accommodates the vital strategies to de/serialize the category. Making this implicit val accessible to the stream technique (both in scope or by import ) allow this.
implicit val RequestSerde: Serde[PredictRequest] = Serdes.fromFn( //serializer
(request:PredictRequest) => request.toByteArray, //deserializer
(requestBytes:Array[Byte]) =>
Choice(PredictRequest.parseFrom(requestBytes)))
The requirement for ML prediction in actual time turns into increasingly standard, and infrequently it imposes fairly just a few challenges on knowledge streaming pipelines. The widespread and most stable approaches are often to make use of both Spark or Flink, principally as a result of they’ve assist for ML and for some Python use circumstances. One of many disadvantages of those approaches, nevertheless, is that they often require to take care of a devoted compute cluster and that can generally be too expensive or an overkill.
On this submit I attempted to sketch a special strategy, primarily based on Kafka Streams, which doesn’t required an extra compute cluster apart from your software server and the streaming platform that you’re already utilizing. For example for a manufacturing grade ML mannequin I used XGBoost classifier and confirmed how a mannequin skilled in a Python atmosphere may be simply wrapped in a Scala object and used for inference on streaming knowledge. When Kafka is used as a streaming platform, then utilizing a KS software would nearly all the time be aggressive when it comes to required growth, upkeep, and efficiency efforts.
Hope this will probably be useful!
*** All pictures, until in any other case famous, are by the creator ***
