In my final submit, I strongly inspired monitoring Machine Studying (ML) fashions with streaming databases. On this submit, I’ll exhibit an instance of how to do that with Materialize. If you want to skip to the code, I’ve put all the pieces on this submit into AIspy, a repo on GitHub.
DTCase Research
Let’s assume that we’re a machine studying practitioner who works for Down To Clown, a Direct To Shopper (DTC) firm that sells clown provides. A brand new consumer who lands on our web site is named a lead. When that consumer purchases their first product, we are saying that they transformed.
We constructed a conversion chance mannequin to foretell the chance {that a} lead will convert. We mannequin this as a binary classification downside, and the end result that we’re predicting is whether or not or not the lead transformed.
If the conversion chance is under some threshold, then we provide the lead a coupon to entice them to transform.
What to Monitor?
For monitoring this mannequin, at a naked minimal we want to observe normal supervised studying efficiency metrics reminiscent of accuracy, precision, recall, and F1 rating. In apply, we must always care about some metric that’s higher correlated with the enterprise goal that we try to optimize. One of many nice issues about deciding to watch your mannequin is that it forces you to truly take into consideration the metrics that matter and the way your mannequin exists and influences its ecosystem.
So yeah, what precisely are we attempting to optimize? We most likely ought to have considered that when constructing the mannequin, however that not often occurs.
Let’s begin with cash; cash’s often an excellent factor to maximise. On this case, we’ll give attention to web income which is the full worth of the conversion buy minus the coupon. How does the mannequin issue into web income? As with most binary classification fashions, it may be useful to assume by means of what occurs in every factor of the confusion matrix.
- True Optimistic
- The mannequin predicts the lead will convert.
- Thus, no coupon is obtainable.
- The consumer converts.
- Internet income is the full conversion quantity.
- True Detrimental:
- The mannequin thinks the lead won’t convert.
- A coupon is obtainable.
- The lead doesn’t convert.
- Internet income is zero.
- False Optimistic:
- The mannequin predicts the lead will convert.
- A coupon is obtainable.
- The lead doesn’t convert.
- Internet income is zero.
- False Detrimental:
- The mannequin predicts the lead won’t convert.
- A coupon is obtainable.
- The lead does convert.
- Internet income is the full conversion quantity minus the coupon quantity.
When you lay out the situations like this, you understand that we’ve got an odd relationship between “normal” classification metrics and the web income. If we wish to maximize web income, then we really wish to maximize the variety of True Positives and False Positives. Though, if we solely maximized False Positives by providing a coupon to everyone, then we may even have much less web income than if we had not had any mannequin or coupon in any respect, relying on the scale of the coupons.
Who knew coupons may very well be so difficult? Let’s keep away from coping with coupon causal inference and as a substitute simply run an experiment. For some small % of customers, we’ll intentionally not provide them a coupon. This can be our management group. We are able to then evaluate the web income per consumer between the management group and the group that may obtain coupons, in addition to normal supervised ML metrics.
Now that we’ve got our faux DTC firm setup, let’s construct a simulation. A believable “information producing” situation may very well be:
- I’ve a backend service that writes leads, conversions, and coupon information to a relational database.
- Conversion predictions are despatched as occasions by the entrance finish to some system that drops them right into a queue, reminiscent of Kafka, for downstream processing.
Assuming this situation, we begin by creating two Postgres tables to retailer leads and coupons.
CREATE TABLE leads (
id SERIAL PRIMARY KEY,
e mail TEXT NOT NULL,
created_at TIMESTAMP NOT NULL DEFAULT NOW(),
converted_at TIMESTAMP,
conversion_amount INT
);
CREATE TABLE coupons (
id SERIAL PRIMARY KEY,
created_at TIMESTAMP NOT NULL DEFAULT NOW(),
lead_id INT NOT NULL,
-- quantity is in cents.
quantity INT NOT NULL
);
When customers land on our web site, we create a brand new lead with null converted_at and conversion_amount fields. Later, if leads do convert, then we replace these fields.
For predictions, we’ll ship these on to a RedPanda* queue as JSON occasions with a type like:
{
"lead_id": 123,
"experiment_bucket": "experiment",
"rating": 0.7,
"label": true,
"predicted_at": "2022-06-09T02:25:09.139888+00:00"
}
*I’m utilizing a RedPanda queue moderately than a Kafka queue because it’s simpler to setup domestically. FWIW, the API is identical.
What’s left now’s to truly simulate all of this. I wrote a Python script to do exactly that, full with delayed conversions and all the pieces. Within the curiosity of not having to attend days for metrics to return in, I assume that conversions occur inside a 30 second window after leads are created.
Moreover, we assume that the conversion prediction mannequin is nicely correlated with conversions, the edge is 0.5, each conversion and coupon quantities are random semi-plausible values, and the displaying of the coupon does enhance the possibility of conversion.
What about Materialize?
What about Materialize? How about – what even is Materialize?
Let’s assume again to what we wish to calculate: web income for each the management group and the “experimental” group that’s eligible for coupons, in addition to normal supervised ML metrics. We might additionally most likely wish to calculate these metrics in relation to time ultimately. Mannequin metrics are essentially mixture capabilities, so we sometimes must outline a while window over which we’ll calculate them. Maybe we wish to calculate the mannequin’s accuracy at every second for a trailing 30 second window.
Okay, so we have to calculate mixture metrics as a operate of time, and our information comes from a number of sources (Postgres + RedPanda). Materialize handles each of those necessities fairly properly.
By way of information sources, I’ve strategically chosen information sources that play very properly with Materialize. Very properly. You possibly can instantly replicate Postgres tables to Materialize, and, so far as I’ve been capable of inform, it simply works. You possibly can setup the replication with some SQL statements in Materialize:
CREATE MATERIALIZED SOURCE IF NOT EXISTS pg_source FROM POSTGRES
-- Fill in with your personal connection credentials.
CONNECTION 'host=postgres consumer=postgres dbname=default'
PUBLICATION 'mz_source'
WITH (timestamp_frequency_ms = 100);
-- From that supply, create views for all tables being replicated.
-- It will embody the leads and coupons tables.
CREATE VIEWS FROM SOURCE pg_source;
Connecting to the RedPanda queue shouldn’t be too dangerous both. I’m logging prediction occasions to a conversion_predictions matter, so you may create a view on prime to transform from JSON into one thing like a daily, queryable SQL desk:
-- Create a brand new supply to learn conversion predictions
-- from the conversion_predictions matter on RedPanda.
CREATE SOURCE IF NOT EXISTS kafka_conversion_predictions
FROM KAFKA BROKER 'redpanda:9092' TOPIC 'conversion_predictions'
FORMAT BYTES;
-- Conversion predictions are encoded as JSON and consumed as uncooked bytes.
-- We are able to create a view to decode this right into a nicely typed format, making
-- it simpler to make use of.
CREATE VIEW IF NOT EXISTS conversion_predictions AS
SELECT
CAST(information->>'lead_id' AS BIGINT) AS lead_id
, CAST(information->>'experiment_bucket' AS VARCHAR(255)) AS experiment_bucket
, CAST(information->>'predicted_at' AS TIMESTAMP) AS predicted_at
, CAST(information->>'rating' AS FLOAT) AS rating
, CAST(information->>'label' AS INT) AS label
FROM (
SELECT
CONVERT_FROM(information, 'utf8')::jsonb AS information
FROM kafka_conversion_predictions
);
BTW, you’ll discover that my Materialize “code” is simply SQL. Materialize is a database, and it follows the Postgres SQL dialect with some further “issues”.
A very powerful further “factor” is the materialized view. A materialized view lets you write a SQL question that creates one thing like a daily desk (though it’s a view), and that “desk” will keep updated as the info modifications. Each time new information is available in (e.g. a prediction occasion into our RedPanda queue) or present information is up to date (e.g. a lead converts), materialized views that rely on predictions or conversions will robotically be up to date. Whereas this will sound easy, and it is easy to make use of, making certain that materialized views could be maintained performantly and with low latency is not any trivial matter; however, Materialize does simply this.
As soon as my information sources have been hooked into Materialize, I can then question them or create materialized views on prime (after which question these views). Importantly, I can write joins between completely different information sources. This was one of many key necessities that I discussed in my final submit, and it’s a requirement not simply met by many fashionable databases.
To begin, I create a non-materialized view of my conversion_predictions_dataset. It will function my canonical dataset of predictions joined with outcomes. This view is non-materialized which signifies that it will get computed on the fly once we run a question towards it moderately than being repeatedly up to date and saved.
-- At every second, calculate the dataset of conversion predictions and outcomes over
-- the trailing 30 seconds.
CREATE VIEW IF NOT EXISTS conversion_prediction_dataset AS
WITH backbone AS (
SELECT
leads.created_at AS timestamp
, leads.id AS lead_id
FROM leads
WHERE
-- The under situations outline "hopping home windows" of interval 2 seconds and window measurement
-- 30 seconds. Mainly, each 2 seconds, we're taking a look at a trailing 30 second
-- window of information.
-- See https://materialize.com/docs/sql/patterns/temporal-filters/#hopping-windows
-- for more information
mz_logical_timestamp() >= 2000 * (EXTRACT(EPOCH FROM leads.created_at)::bigint * 1000 / 2000)
AND mz_logical_timestamp() < 30000 * (2000 + EXTRACT(EPOCH FROM leads.created_at)::bigint * 1000 / 2000)
)
, predictions AS (
SELECT
backbone.lead_id
, conversion_predictions.experiment_bucket
, conversion_predictions.predicted_at
, conversion_predictions.rating
, conversion_predictions.label::BOOL
FROM backbone
LEFT JOIN conversion_predictions
ON conversion_predictions.lead_id = backbone.lead_id
)
, outcomes AS (
SELECT
backbone.lead_id
, CASE
WHEN
leads.converted_at IS NULL THEN FALSE
WHEN
leads.converted_at <= (leads.created_at + INTERVAL '30 seconds')
THEN TRUE
ELSE FALSE
END AS worth
, CASE
WHEN
leads.converted_at IS NULL THEN NULL
WHEN
-- Be sure that to solely use conversion information that was recognized
-- _as of_ the lead created at second.
leads.converted_at <= (leads.created_at + INTERVAL '30 seconds')
THEN leads.converted_at
ELSE NULL
END AS lead_converted_at
, CASE
WHEN
leads.converted_at IS NULL THEN NULL
WHEN
leads.converted_at <= (leads.created_at + INTERVAL '30 seconds')
THEN leads.conversion_amount
ELSE NULL
END AS conversion_amount
, coupons.quantity AS coupon_amount
FROM backbone
LEFT JOIN leads ON leads.id = backbone.lead_id
LEFT JOIN coupons ON coupons.lead_id = backbone.lead_id
)
SELECT
date_trunc('second', backbone.timestamp) AS timestamp_second
, backbone.lead_id
, predictions.experiment_bucket
, predictions.rating AS predicted_score
, predictions.label AS predicted_value
, outcomes.worth AS outcome_value
, outcomes.conversion_amount
, outcomes.coupon_amount
FROM backbone
LEFT JOIN predictions ON predictions.lead_id = backbone.lead_id
LEFT JOIN outcomes ON outcomes.lead_id = backbone.lead_id
Lastly, we get to the materialized view. For this, I take advantage of the aforementioned view to calculate mannequin metrics at each second for a trailing 30-second window.
-- At every second, calculate the efficiency metrics of the
-- conversion prediction mannequin over the trailing 30 seconds.
CREATE MATERIALIZED VIEW IF NOT EXISTS classifier_metrics AS
WITH aggregates AS (
-- Calculate numerous efficiency metrics aggregations.
SELECT
timestamp_second
, experiment_bucket
, COUNT(DISTINCT lead_id) AS num_leads
, SUM((predicted_value AND outcome_value)::INT)
AS true_positives
, SUM((predicted_value AND not outcome_value)::INT)
AS false_positives
, SUM((NOT predicted_value AND not outcome_value)::INT)
AS true_negatives
, SUM((NOT predicted_value AND not outcome_value)::INT)
AS false_negatives
, SUM(conversion_amount)::FLOAT / 100 AS conversion_revenue_dollars
, (SUM(conversion_amount) - SUM(COALESCE(coupon_amount, 0)))::FLOAT / 100
AS net_conversion_revenue_dollars
FROM conversion_prediction_dataset
GROUP BY 1, 2
)
-- Ultimate metrics
SELECT
timestamp_second
, experiment_bucket
, num_leads
, true_positives
, false_positives
, true_negatives
, false_negatives
, conversion_revenue_dollars
, net_conversion_revenue_dollars
, true_positives::FLOAT
/ NULLIF(true_positives + false_positives, 0)
AS precision
, true_positives::FLOAT
/ NULLIF(true_positives + false_negatives, 0)
AS recall
, true_positives::FLOAT
/ NULLIF(
true_positives
+ 1.0 / 2.0 * (false_positives + false_negatives)
, 0
)
AS f1_score
FROM aggregates
Visualizing
So I’ve my simulation creating information in each Postgres and RedPandas, I’ve hooked these information sources into Materialize, and I’m now regularly updating a materialized view of mixture efficiency metrics. What do I do with this materialized view? How a couple of dashboard?
Whereas perusing the Materialize demos on GitHub (which I’ve very liberally relied upon to create my very own demo for this submit), I noticed that there are a variety of examples that visualize materialized views with Metabase. Metabase is type of like an open supply Looker. For our functions, we are able to use Metabase to create a plot of our materialized view’s fields as a operate of time, and we are able to even setup the plot to replace each second.
You see, the good factor about utilizing one thing very, conventionally database-y like Materialize is that we get to benefit from the complete ecosystem of instruments which were constructed round databases.
I received’t bore you with particulars round organising the Metabase dashboard, however I’ll present you a screenshot of what this dashboard appears like for posterity:
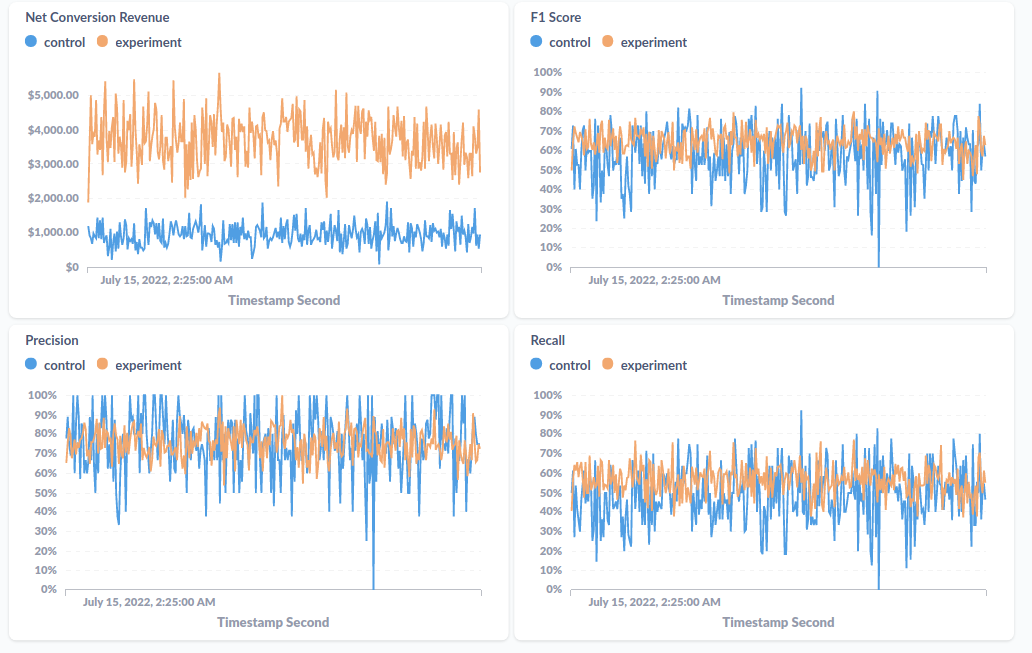
What Subsequent?
It’d be cool to construct a light-weight framework round this. One thing like:
You join your information to Materialize and get it right into a single view just like my conversion_predictions_dataset view above. So long as you try this, the framework will construct good materialized views for traditional supervised ML metrics, customized metrics, and many others… together with assist for slicing and dicing metrics alongside no matter dimensions you embody.
That’s the place issues would begin at the very least. The hope can be that it’s fast to rise up and working, however then the extra you set in, the extra you get out. Ship your mannequin names and model with the predictions, and these develop into pure dimensions. Add assist for experimentation and plugins for third occasion libraries. Who is aware of, possibly even add a function retailer.
…
I would love thank Really, no person learn this weblog submit earlier than it was printed, so I might not prefer to thank anyone. All blame rests on my shoulders.

{kind=link}