The collection of areas and strategies is closely influenced by my very own pursuits; the chosen matters are biased in direction of illustration and switch studying and in direction of pure language processing (NLP). I attempted to cowl the papers that I used to be conscious of however seemingly missed many related ones—be at liberty to focus on them within the feedback beneath. In all, I focus on the next highlights:
- Scaling up—and down
- Retrieval augmentation
- Few-shot studying
- Contrastive studying
- Analysis past accuracy
- Sensible issues of enormous LMs
- Multilinguality
- Picture Transformers
- ML for science
- Reinforcement studying
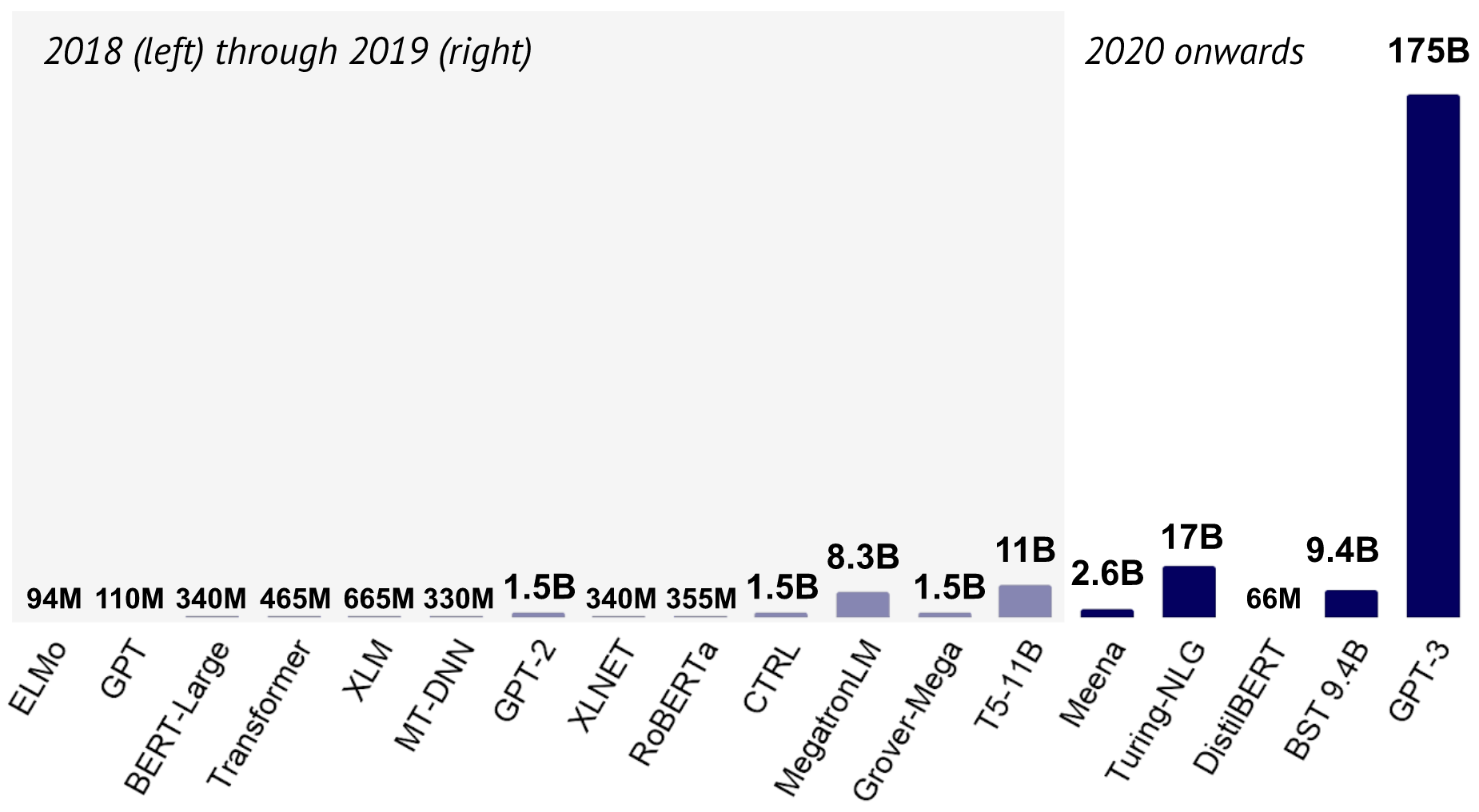
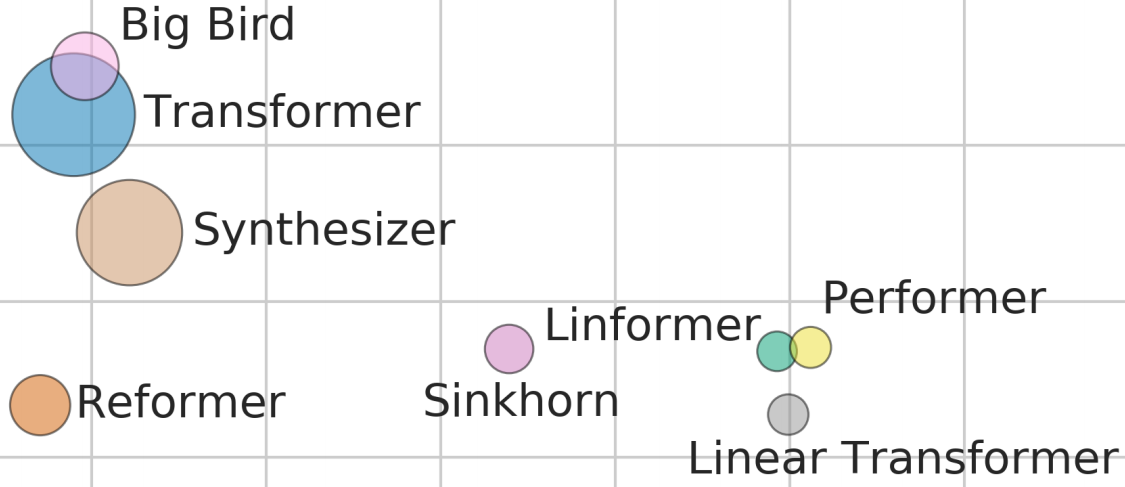
What occurred? 2020 noticed the event of ever bigger language and dialogue fashions resembling Meena (Adiwardana et al., 2020), Turing-NLG, BST (Curler et al., 2020), and GPT-3 (Brown et al., 2020). On the similar time, researchers have change into extra conscious of how costly and energy-hungry these fashions may be (Strubell et al., 2019) and work that focuses on making them smaller has gained momentum: Latest approaches depend on pruning (Sajjad et al., 2020; Fan et al., 2020a; Sanh et al., 2020), quantization (Fan et al., 2020b), distillation (Sanh et al., 2019; Solar et al., 2020), and compression (Xu et al., 2020). Different approaches centered on making the Transformer structure itself extra environment friendly. Fashions on this line embody the Performer (Choromanski et al., 2020) and Huge Hen (Zaheer et al., 2020), which may be seen within the cowl picture above. The picture reveals efficiency (y axis), pace (x axis) and reminiscence footprint (circle dimension) of various fashions on the Lengthy Vary Area benchmark (Tay et al., 2020).
Instruments such because the experiment-impact-tracker (Henderson et al., 2020) have made it simpler to trace the vitality effectivity of fashions. They’ve additionally facilitated competitions and benchmarks that consider fashions based on their effectivity such because the SustaiNLP workshop at EMNLP 2020, the Environment friendly QA competitors at NeurIPS 2020, and HULK (Zhou et al., 2020).
Why is it essential? Scaling up fashions permits us to maintain pushing the boundaries of what present fashions can do. So as to deploy and use them in real-world situations, nonetheless, they should be environment friendly. Finally, each instructions profit one another: Compressing giant fashions yields environment friendly fashions with sturdy efficiency (Li et al., 2020) whereas extra environment friendly strategies might result in stronger, bigger fashions (Clark et al., 2020).
What’s subsequent? I’m hopeful that—in gentle of the rising curiosity in effectivity and the supply of instruments—it is going to change into extra frequent not solely to report a mannequin’s efficiency and variety of parameters but in addition its vitality effectivity. This could contribute to a extra holistic analysis which will assist to bridge the hole to real-world ML use instances.
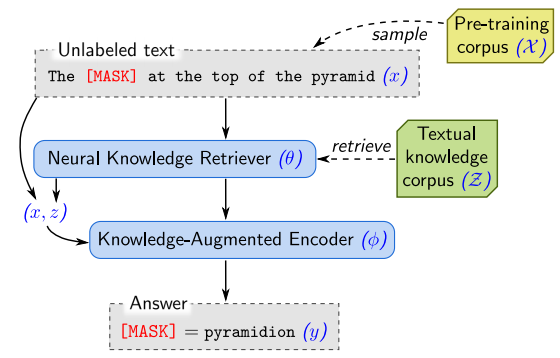
What occurred? Massive fashions have been proven to have realized a shocking quantity of world data from their pre-training knowledge, which permits them to breed details (Jiang et al., 2020) and reply questions even with out entry to exterior context (Roberts et al., 2020). Nonetheless, storing such data implicitly within the parameters of a mannequin is inefficient and requires ever bigger fashions to retain extra info. As a substitute, current approaches collectively educated retrieval fashions and huge language fashions, which led to sturdy outcomes on knowledge-intensive NLP duties resembling open-domain query answering (Guu et al., 2020; Lewis et al., 2020) and language modelling (Khandelwal et al., 2020). The primary benefit of those strategies is that they combine retrieval instantly into language mannequin pre-training, which permits language fashions to be rather more environment friendly by with the ability to off-load the recall of details and concentrate on studying the tougher facets of pure language understanding. Consequently, the most effective methods within the NeurIPS 2020 EfficientQA competitors (Min et al., 2020) all relied on retrieval.
Why is it essential? Retrieval was the usual in lots of generative duties, resembling textual content summarization or dialogue and has largely been outmoded by abstractive era (Allahyari et al., 2017). Retrieval-augmented era permits combining the most effective of each worlds: the factual correctness and faithfulness of retrieved segments and the relevancy and composition of generated textual content.
What’s subsequent? Retrieval-augmented era ought to be notably helpful for coping with failure instances which have plagued generative neural fashions up to now, resembling coping with hallucinations (Nie et al., 2019). It might additionally assist make methods extra interpretable by instantly offering proof for his or her prediction.

What occurred? During the last years, pushed by advances in pre-training, the variety of coaching examples to carry out a given process has progressively gone down (Peters et al., 2018; Howard et al., 2018). We are actually at a stage the place tens of examples can be utilized to show a given process (Bansal et al., 2020). A really pure paradigm for few-shot studying is to reframe a process as language modelling. Probably the most distinguished instantiation of this, the in-context studying method of GPT-3 (Brown et al., 2020) performs a prediction based mostly on a couple of demonstrations of enter–output pairs within the mannequin’s context and a immediate with none gradient updates. This setting, nonetheless, has a couple of limitations: It requires an enormous mannequin—with none updates the mannequin must depend on its present data—, the quantity of data that the mannequin can use is restricted by its context window, and prompts should be hand-engineered.
Latest work has sought to make such few-shot studying simpler through the use of a smaller mannequin, integrating fine-tuning, and mechanically producing pure language prompts (Schick and Schütze, 2020; Gao et al., 2020; Shin et al., 2020). Such work is carefully associated to the broader space of controllable neural textual content era, which broadly seeks to leverage the generative capabilities of highly effective pre-trained fashions. For a superb overview, take a look at Lilian Weng’s weblog publish.
Few-shot studying permits fast adaptation of a mannequin to many duties. Nonetheless, updating all mannequin parameters for every process is wasteful. As a substitute, it’s preferable to carry out localized updates that focus adjustments in a small set of parameters. There have been a couple of approaches that make such environment friendly fine-tuning extra sensible together with utilizing adapters (Houlsby et al., 2019; Pfeiffer et al., 2020a,b; Üstün et al., 2020), including a sparse parameter vector (Guo et al., 2020), and solely modifying bias values (Ben-Zaken et al., 2020).
Why is it essential? Having the ability to educate a mannequin a process based mostly on just a few examples enormously reduces the barrier to entry for making use of ML and NLP fashions in observe. This opens up functions the place knowledge may be very costly to gather and permits adapting fashions swiftly to new domains.
What’s subsequent? For a lot of real-world situations, it’s attainable to gather hundreds of coaching examples. Fashions ought to thus be capable of scale seamlessly from studying from a couple of to studying from hundreds of examples and shouldn’t be restricted by e.g. their context size. Provided that fashions have achieved super-human efficiency on many in style duties resembling SuperGLUE when fine-tuned on complete coaching datasets, enhancing their few-shot efficiency is a pure space for enchancment.
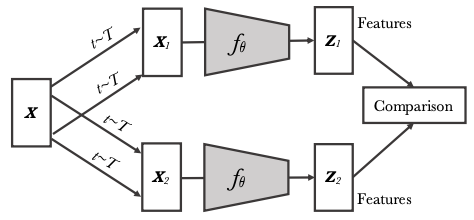
What occurred? Contrastive studying—studying to distinguish a constructive instance from destructive samples, usually from a noise distribution—resembling utilizing destructive sampling or noise contrastive estimation is a staple of illustration studying and self-supervised studying and a distinguished a part of basic approaches resembling word2vec (Mikolov et al., 2013). Extra just lately, contrastive studying gained recognition in self-supervised illustration studying in pc imaginative and prescient and speech (van den Oord, 2018; Hénaff et al., 2019). The current era of more and more highly effective self-supervised approaches for visible illustration studying depend on contrastive studying utilizing an occasion discrimination process: totally different pictures are handled as destructive pairs and views of the identical picture are handled as constructive pairs. Latest approaches have additional refined this basic framework: SimCLR (Chen et al., 2020) defines the contrastive loss over augmented examples, Momentum Distinction (He et al., 2020) seeks to make sure a big and constant set of pairs, SwAV (Caron et al., 2020) leverages on-line clustering, and BYOL solely employs constructive pairs (Grill et al., 2020). Chen and He (2020) have moreover proposed an easier formulation that pertains to the earlier strategies.
Not too long ago, Zhao et al. (2020) discover that knowledge augmentation is important for contrastive studying. This may point out why unsupervised contrastive studying has not been profitable with giant pre-trained fashions in NLP the place knowledge augmentation is much less frequent. In addition they hypothesize that the rationale occasion discrimination may match higher than supervised pre-training in pc imaginative and prescient is that it doesn’t attempt to make the options of all situations from a category comparable however retains the knowledge from every occasion. That is much less of an issue in NLP the place unsupervised pre-training includes classification over hundreds of phrase sorts. In NLP, Gunel et al. (2020) just lately make use of contrastive studying for supervised fine-tuning.
Why is it essential? The cross-entropy goal between one-hot labels and a mannequin’s output logits generally utilized in language modelling has a number of limitations resembling generalizing poorly to imbalanced courses (Cao et al., 2019). Contrastive studying is another, complementary paradigm which will assist ameliorate a few of these deficits.
What’s subsequent? Contrastive studying mixed with masked language modelling might allow us to study representations which might be richer and extra strong. It might assist mannequin outliers and uncommon syntactic and semantic phenomena, that are a problem for present NLP fashions.

What occurred? State-of-the-art fashions in NLP have achieved superhuman efficiency throughout many duties. Whether or not or not we imagine that such fashions can obtain true pure language understanding (Yogatama et al., 2019; Bender and Koller, 2020), we all know that present fashions are usually not near this elusive purpose. Nonetheless, the easy efficiency metrics of our duties fail to seize the restrictions of present fashions. There are two key themes on this space: a) curating examples which might be troublesome for present fashions; and b) going past easy metrics resembling accuracy in direction of extra fine-grained analysis.
Concerning the previous, the frequent methodology is to make use of adversarial filtering (Zellers et al., 2018) throughout dataset creation to filter out examples which might be predicted accurately by present fashions. Latest work proposes extra environment friendly adversarial filtering strategies (Sakaguchi et al., 2020; Le Bras et al., 2020) and an iterative dataset creation course of (Nie et al., 2020; Bartolo et al., 2020) the place examples are filtered and fashions are re-trained over a number of rounds. A subset of such evolving benchmarks can be found in Dynabench.
The strategies that regard the second level are comparable in spirit. Nonetheless, somewhat than creating examples that concentrate on a selected mannequin, examples are used to probe for phenomena frequent to a process of curiosity. Generally, minimal pairs—also referred to as counterfactual examples or distinction units—(Kaushik et al., 2020; Gardner et al., 2020; Warstadt et al., 2020) are created, which perturb examples in a minimal approach and infrequently change the gold label. Ribeiro et al. (2020) formalized a number of the underlying intuitions of their CheckList framework, which permits the semi-automatic creation of such take a look at instances. Alternatively, examples may be characterised based mostly on totally different attributes, which permit a extra fine-grained evaluation of a mannequin’s strengths and weaknesses (Fu et al., 2020).
Why is it essential? So as to make significant progress in direction of constructing extra succesful fashions machine studying fashions, we have to perceive not provided that a mannequin outperforms a earlier system however what sort of errors it makes and which phenomena it fails to seize.
What’s subsequent? By offering fine-grained diagnostics of mannequin behaviour, it will likely be simpler to determine a mannequin’s deficiencies and suggest enhancements that handle them. Equally, a fine-grained analysis would permit a extra nuanced comparability of the strengths and weaknesses of various strategies.
What occurred? In comparison with 2019 the place the evaluation of language fashions (LMs) primarily centered on the syntactic, semantic, and world data that such fashions seize—see (Rogers et al., 2020) for an incredible overview—current analyses revealed quite a lot of sensible issues. Pre-trained language fashions had been discovered to be liable to producing poisonous language (Gehman et al., 2020) and leak info (Track & Raghunathan, 2020), to be vulnerable to backdoors after fine-tuning, which let an attacker manipulate the mannequin prediction (Kurita et al., 2020; Wallace et al., 2020), and to be weak to mannequin and knowledge extraction assaults (Krishna et al., 2020; Carlini et al., 2020). As well as, pre-trained fashions are well-known to seize biases with regard to protected attributes resembling gender (Bolukbasi et al., 2016; Webster et al., 2020)—see (Solar et al., 2019) for a superb survey on mitigating gender bias.
Why is it essential? Massive pre-trained fashions are educated by many establishments and are actively deployed in real-world situations. It’s thus of sensible significance that we aren’t solely conscious of their biases however what behaviour might have truly dangerous penalties.
What’s subsequent? As bigger and extra highly effective fashions are developed, it is crucial that such sensible issues in addition to points round bias and equity are a part of the event course of from the beginning.
What occurred? 2020 had many highlights in multilingual NLP. The Masakhane organisation whose mission is to strengthen NLP for African languages gave the keynote on the Fifth Convention on Machine Translation (WMT20), one of the crucial inspiring displays of the final yr. New general-purpose benchmarks for different languages emerged together with XTREME (Hu et al., 2020), XGLUE (Liang et al., 2020), IndoNLU (Wilie et al., 2020), IndicGLUE (Kakwani et al., 2020). Current datasets that had been replicated in different languages—along with their non-English variants—embody:
- SQuAD: XQuAD (Artetxe et al., 2020), MLQA (Lewis et al., 2020), FQuAD (d’Hoffschmidt et al., 2020);
- Pure Questions: TyDiQA (Clark et al., 2020), MKQA (Longpre et al., 2020);
- MNLI: OCNLI (Hu et al., 2020), FarsTail (Amirkhani et al., 2020);
- the CoNLL-09 dataset: X-SRL (Daza and Frank, 2020); and
- the CNN/Every day Mail dataset: MLSUM (Scialom et al., 2020).
Many of those datasets and plenty of others in several languages are simply accessible through Hugging Face datasets. Highly effective multilingual fashions that cowl round 100 languages emerged together with XML-R (Conneau et al., 2020), RemBERT (Chung et al., 2020), InfoXLM (Chi et al., 2020), and others (see the XTREME leaderboard for an outline). A plethora of language-specific BERT fashions have been educated for languages past English resembling AraBERT (Antoun et al., 2020) and IndoBERT (Wilie et al., 2020); see (Nozza et al., 2020; Rust et al., 2020) for an outline. With environment friendly multilingual frameworks resembling AdapterHub (Pfeiffer et al., 2020), Stanza (Qi et al., 2020) and Trankit (Nguyen et al., 2020) it has change into simpler than ever to use and construct fashions for most of the world’s languages.
Lastly, two place papers that impressed a lot of my pondering on this space this yr are The State and Destiny of Linguistic Range and Inclusion within the NLP World (Joshi et al., 2020) and Decolonising Speech and Language Know-how (Hen, 2020). Whereas the primary highlights the pressing significance of engaged on languages past English, the second cautions towards treating language communities and their knowledge as a commodity.
Why is it essential? Engaged on NLP past English has quite a few advantages: It poses fascinating challenges for ML and NLP and permits having a big influence on society, amongst many others.
What’s subsequent? Given the supply of knowledge and fashions in several languages, the stage is ready to make significant progress on languages past English. I’m most enthusiastic about growing fashions that deal with probably the most difficult settings and figuring out wherein instances the assumptions that underlie our present fashions fail.
What occurred? Whereas Transformers have achieved giant success in NLP, they had been—up till just lately—much less profitable in pc imaginative and prescient the place convolutional neural networks (CNNs) nonetheless reigned supreme. Whereas fashions early within the yr resembling DETR (Carion et al., 2020) employed a CNN to compute picture options, later fashions had been utterly convolution-free. Picture GPT (Chen et al., 2020) utilized the GPT-2 recipe to pre-training instantly from pixels and outperforms a supervised Broad ResNet. Later fashions all reshape a picture into patches which might be handled as “tokens”. Imaginative and prescient Transformer (Dosovitskiy et al., 2020) is pre-trained on hundreds of thousands of labelled pictures—every consisting of such patches—outperforming state-of-the-art CNNs. The Picture Processing Transformer (Chen et al., 2020) pre-trains on corrupted ImageNet examples with a contrastive loss and achieves state-of-the-art efficiency on low-level picture duties. The Knowledge-efficient picture Transformer (Touvron et al., 2020) is pre-trained on ImageNet through distillation. Curiously, they observe that CNNs are higher academics. That is just like findings for distilling an inductive bias into BERT (Kuncoro et al., 2020). In distinction in speech, Transformers haven’t been utilized on to the audio sign—to my data—however usually obtain the output of an encoder resembling a CNN as enter (Moritz et al., 2020; Gulati et al., 2020; Conneau et al., 2020)
Why is it essential? Transformers have much less inductive bias in comparison with CNNs and RNNs. Whereas being much less theoretically highly effective than RNNs (Weiss et al., 2018; Hahn et al., 2020), given ample knowledge and scale Transformers have been proven to ultimately outperform their inductively biased rivals (cf. The Bitter Lesson).
What’s subsequent? We’ll seemingly see Transformers change into extra in style in pc imaginative and prescient. They are going to be utilized notably in situations the place sufficient compute and knowledge for unsupervised pre-training is on the market. In smaller scale settings, CNNs will seemingly nonetheless be the go-to method and a powerful baseline.
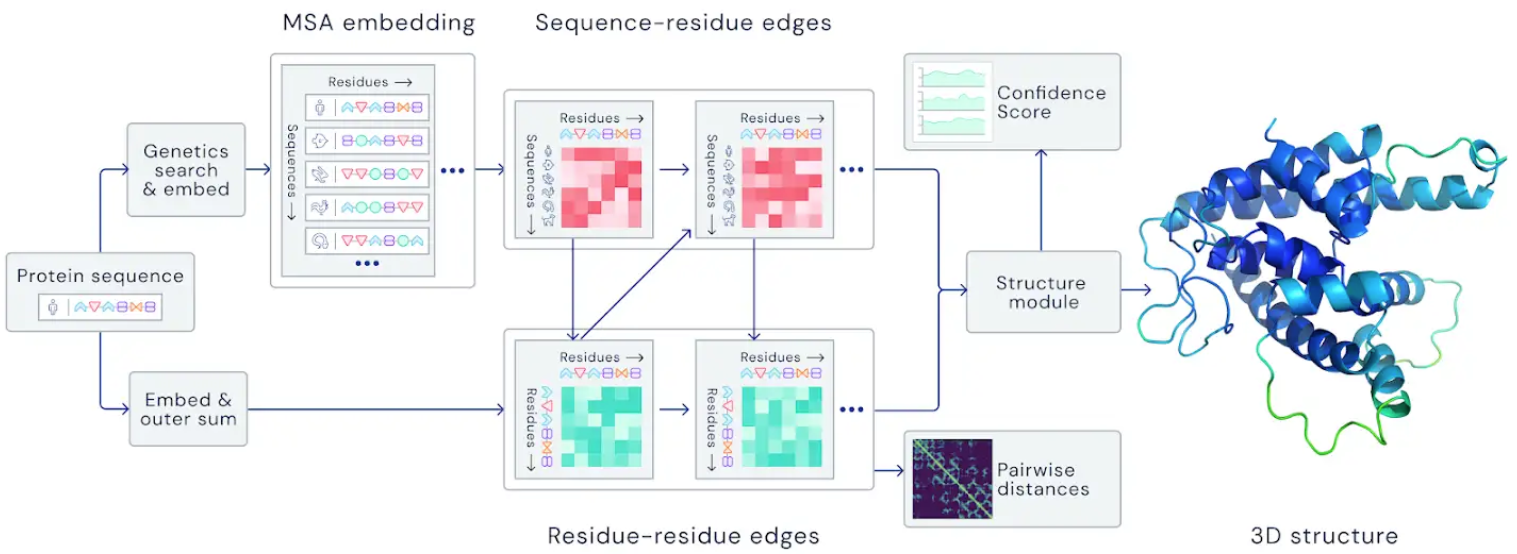
What occurred? One of many highlights was AlphaFold demonstrating ground-breaking efficiency within the biannual CASP problem for protein folding. Past that, there have been a number of different notable developments in making use of ML to issues within the pure sciences. MetNet (Sønderby et al., 2020) outperformed numerical climate prediction for precipitation forecasting, Lample and Charton (2020) solved differential equations utilizing neural networks higher than business pc algebra methods, and Bellemare et al. (2020) used reinforcement studying to navigate balloons within the stratosphere.
As well as, ML has been used extensively to assist with the continuing COVID-19 pandemic, e.g. to forecast COVID-19 unfold (Kapoor et al., 2020), predict constructions related to COVID-19, translate related knowledge into 35 totally different languages (Anastasopoulos et al., 2020), and reply questions on COVID-19 in real-time (Lee et al., 2020). For an outline of COVID-19 associated functions of NLP, take a look at the Proceedings of the first Workshop on NLP for COVID-19.
Why is it essential? The pure sciences are arguably probably the most impactful utility space for ML. Enhancements contact many facets of life and may have a profound influence on the world.
What’s subsequent? With progress in areas as central as protein folding, the pace of utility of ML to the pure sciences will solely speed up. I’m trying ahead to many extra basic advances which have a constructive influence on the planet.
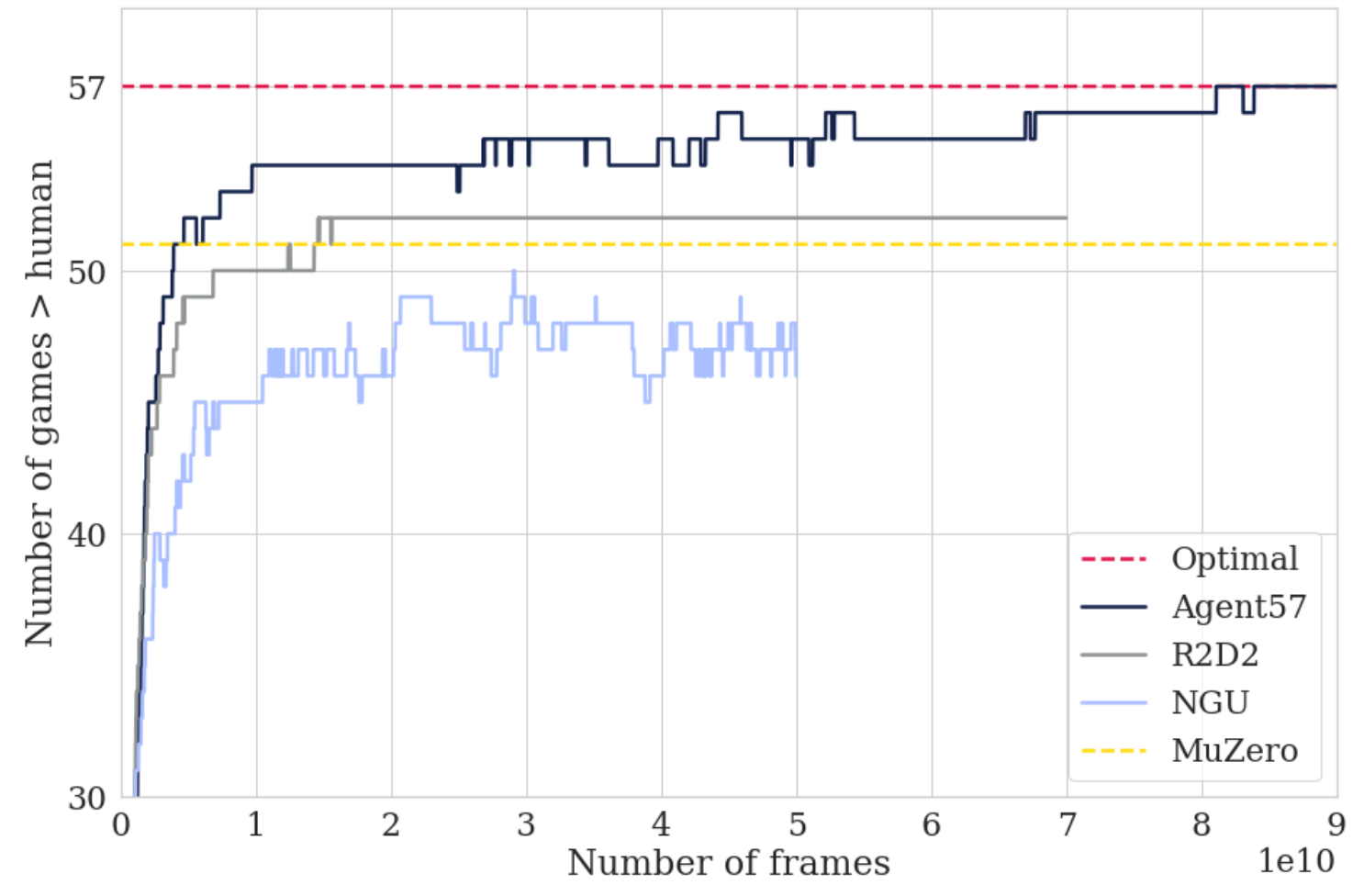
What occurred? For the primary time, a single deep RL agent—Agent57 (Badia et al., 2020)—has achieved superhuman efficiency on all 57 Atari video games, a long-standing benchmark within the deep reinforcement studying literature. The agent’s versatility comes from a neural community that enables it to change between exploratory and exploitative insurance policies. One other milestone was the event of MuZero (Schrittwieser et al., 2020), which predicts the facets of the surroundings which might be most essential for correct planning. With none data of the sport dynamics, it achieved state-of-the-art efficiency on Atari in addition to superhuman efficiency on Go, chess, and shogi. Lastly, Munchausen RL brokers (Vieillard et al., 2020) improved on state-of-the-art brokers through a easy, theoretically based modification.
Why is it essential? Reinforcement studying algorithms have a mess of sensible implications (Bellemare et al., 2020). Enhancements over the basic algorithms on this space can have a big sensible influence by enabling higher planning, surroundings modelling, and motion prediction.
What’s subsequent? With basic benchmarks resembling Atari primarily solved, researchers might look to tougher settings to check their algorithms resembling generalizing to out-of-distribution duties, enhancing sample-efficiency, multi-task studying, and so forth.
Quotation
For attribution in tutorial contexts, please cite this work as:
@misc{ruder2021researchhighlights,
creator = {Ruder, Sebastian},
title = {{ML and NLP Analysis Highlights of 2020}},
yr = {2021},
howpublished = {url{http://ruder.io/research-highlights-2020}},
}Due to Sameer Singh whose Twitter thread reviewing NLP analysis in 2020 offered inspiration for this publish.

{kind=link}