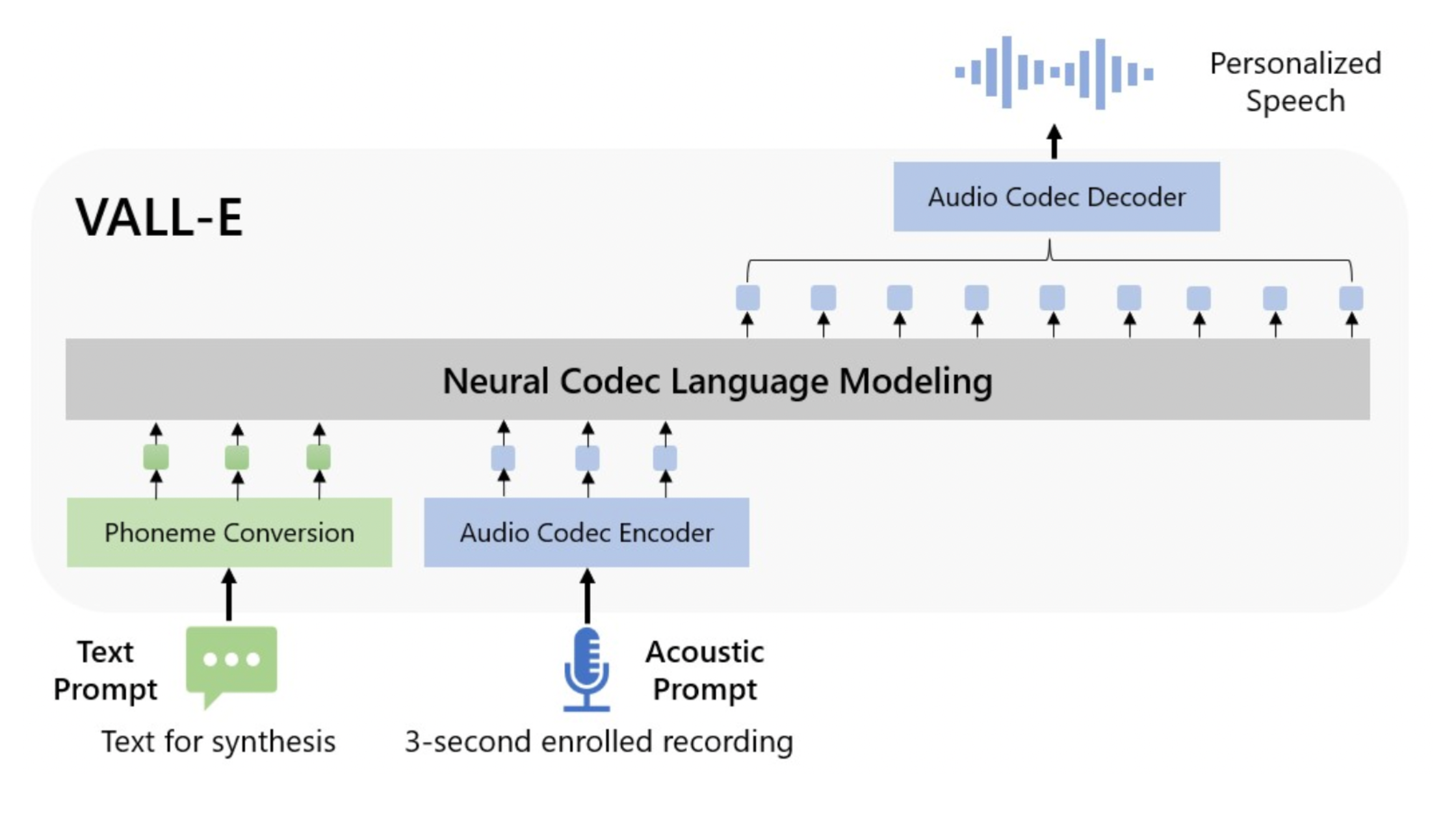
Microsoft just lately launched VALL-E, a brand new language mannequin method for text-to-speech synthesis (TTS) that makes use of audio codec codes as intermediate representations. It demonstrated in-context studying capabilities in zero-shot situations after being pre-trained on 60,000 hours of English speech information.
With only a three-second enrolled recording of an indirect speaker serving as an acoustic immediate, VALL-E can create high-quality personalised speech. It helps contextual studying and prompt-based zero-shot TTS strategies with out extra structural engineering, pre-designed acoustic options, and fine-tuning. Microsoft has leveraged a considerable amount of semi-supervised information to develop a generalised TTS system within the speaker dimension, which signifies that the scaling up of semi-supervised information for TTS has been underutilised.
Learn the paper right here.
VALL-E can generate varied outputs with the identical enter textual content whereas sustaining the speaker’s emotion and the acoustical immediate. VALL-E can synthesise pure speech with excessive speaker accuracy by prompting within the zero-shot situation. In accordance with analysis outcomes, VALL-E performs a lot better on LibriSpeech and VCTK than essentially the most superior zero-shot TTS system. VALL-E even achieved new state-of-the-art zero-shot TTS outcomes on LibriSpeech and VCTK.
It’s attention-grabbing to notice that individuals who have misplaced their voice can ‘speak’ once more by means of this text-to-speech methodology if they’ve earlier voice recordings of themselves. Two years in the past, a Stanford College Professor, Maneesh Agarwala, additionally instructed AIM that they had been engaged on one thing comparable, the place that they had deliberate to report a affected person’s voice earlier than the surgical procedure after which use that pre-surgery recording to transform their electrolarynx voice again into their pre-surgery voice.
Options of VALL-E:
- Synthesis of Variety: VALL- E’s output varies for a similar enter textual content because it generates discrete tokens utilizing the sampling-based methodology. So, utilizing varied random seeds, it might synthesise totally different personalised speech samples.
- Acoustic Setting Upkeep: Whereas retaining the speaker immediate’s acoustic surroundings, VALL-E can generate personalised speech. VALL-E is educated on a large-scale dataset with extra acoustic variables than the information utilized by the baseline. Samples from the Fisher dataset had been used to create the audio and transcriptions.
- Speaker’s emotion upkeep: Based mostly on the Emotional Voices Database for pattern audio prompts, VALL-E can construct personalised speech whereas preserving the speaker immediate’s emotional tone. The speech correlates to a transcription and an emotion label in a supervised emotional TTS dataset, which is how conventional approaches practice a mannequin. In a zero-shot setting, VALL-E can keep the emotion within the immediate.
VALL-E is but to beat shortcomings like synthesis robustness, information protection and mannequin construction.
Final yr, the Microsoft-supported AI analysis lab OpenAI launched Level-E, a way to generate 3D level clouds from complicated factors. Level-E seeks to alter 3D area in the identical means that DALL-E did for text-to-image technology.

{kind=link}