
No último artigo vimos o funcionamento básico do Prometheus e como configurar um servidor Prometheus em um cluster Kubernetes.
(lembrando que estou utilizando um cluster native com Docker Desktop for Mac)
Neste artigo, vamos explorar mais métricas para monitoramento:
- porcentagem de uso da CPU no cluster
- porcentagem de uso da memória no cluster
Prometheus Sources
Existem diversas fontes (sources) de dados para o Prometheus, mas vamos resumir aqui as principais para um cluster Kubernetes, nomeadamente:
- cAdvisor
- node-exporter
- kube-state-metrics
cAdvisor
cAdvisor é um agente de monitoramento para containers e tem suporte nativo ao Docker.
Em um cluster Kubernetes, temos a opção de instalar o cAdvisor como uma pod que coleta métricas dos containers.
Entretanto não precisamos disto, uma vez que o componente kubelet do Kubernetes já utiliza e exporta métricas do cAdvisor em um endpoint do cluster.
node-exporter
O node-exporter é um agente para monitoramento dos recursos do nó (máquina), tais como CPU, memória e armazenamento persistente.
Pode ser instalado em um cluster Kubernetes como uma pod que coleta métricas dos nodes do cluster.
kube-state-metrics
Este agente é um add-on que fica à escuta de todos os eventos do Kubernetes API Server, ou seja, qualquer coisa que acontece no cluster é coletada e exportada como métrica.
Tal como os outros agentes, kube-state-metrics pode ser instalado no cluster através de uma pod que fica coletando métricas do API Server.
Qual deles utilizar?
Após o resumo dos diferentes tipos de sources, vamos neste artigo focar no cAdvisor, deixando os outros para futuros artigos.
É extremamente importante conhecer os tipos de métricas que cada um oferece e fazer o balanço correto de quais sources o Prometheus deve fazer o scraping.
Coletando métricas com cAdvisor
Recapitulando a configuração “estática” que vem por padrão no Prometheus:
- job_name: prometheus
static_configs:
- targets: ['localhost:9090']
No caso do cAdvisor, que já é utilizando pelo kubelet, vamos criar outro job e utilizar uma configuração dinâmica que muda as labels em tempo de scraping, de forma a deixar mais simples nossas queries.
Como o kubelet exporta as métricas by way of https, precisamos definir o schema de acesso bem como configuração de tls_config e token de acesso:
- job_name: kubernetes-nodes-cadvisor
scheme: https
tls_config:
ca_file: /var/run/secrets and techniques/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets and techniques/kubernetes.io/serviceaccount/token
Nota: /var/run/secrets and techniques/kubernetes.io/serviceaccount/ é o caminho padrão de secrets and techniques e certificados de acesso para componentes internos do Kubernetes.
Próximo passo é escolher o position, que é basicamente o tipo de “uncover” que o Prometheus deve fazer nas métricas. O Kubernetes oferece vários tipos de roles:
- node: informações de containers agrupados por nós (máquinas)
- service: containers agrupados por service, bem como informações extras dos providers
- pod: informações dos containers das pods em si
- endpoint: agrupamento por endpoint
- ingress: e por fim, agrupamento por ingress, muito útil para monitoramento blackbox
Nosso exemplo passa por criar apenas uma position node, pois queremos informações baseadas no node (% de CPU, % de memória):
kubernetes_sd_configs:
- position: node
Isto ainda não basta, pois precisamos das configurações de relabel, que é uma function do Prometheus que faz labeling de métricas em tempo de scraping. Com relabel, somos permitidos a escolher labels específicas e trocá-las por variáveis que o Prometheus usa durante o scraping.
relabel_configs:
- motion: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
alternative: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
alternative: /api/v1/nodes/${1}/proxy/metrics/cadvisor
Importante: temos que colocar este yaml num configmap e montar no quantity da Pod, mas este passo vou deixar como exercício para que o artigo não fique enorme.
Não há motivo para pânico entretanto, tudo o que faço aqui é compartilhado no Github_
Visualizando
$ kubectl -n monitoring port-forward deploy/prometheus-pod 9090:9090
$ open localhost:9090
Uh oh 
A página não abre. Mas vamos olhar os logs da pod:
Failed to observe *v1.Node: did not listing *v1.Node: nodes is forbidden: Person "system:serviceaccount:monitoring:default" can not listing useful resource "nodes" in API group │
│ "" on the cluster scope"
Esta pod não tem permissão de acesso às métricas de “nodes” no cluster. Vamos então criar uma ClusterRole que permita acesso às métricas dos recursos do cluster e associá-la a qualquer recurso do namespace monitoring através de ServiceAccount:
apiVersion: rbac.authorization.k8s.io/v1
variety: ClusterRole
metadata:
identify: prometheus
guidelines:
- apiGroups: [""]
assets:
- nodes
- nodes/proxy
- providers
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups:
- extensions
assets:
- ingresses
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1
variety: ClusterRoleBinding
metadata:
identify: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
variety: ClusterRole
identify: prometheus
topics:
- variety: ServiceAccount
identify: default
namespace: monitoring # <---- importante
And now:
$ kubectl apply -f cluster-role.yml
Iniciar port-forward novamente e abrir a interface net buscando pela métrica machine_cpu_cores.

Que dia maravilhoso!
Mais métricas no cAdvisor
Poderíamos ficar o dia todo experimentando métricas, dentre elas:
container_cpu_usage_seconds_total
Traz de forma multi-dimensional os segundos de utilização da CPU. Isto dá um poder enorme para agruparmos por soma:
sum(container_cpu_usage_seconds_total{namespace="monitoring"})
5.702207
container_memory_working_set_bytes
Quantidade de bytes reservados para determinado recurso no namespace monitoring:
sum(container_memory_working_set_bytes{namespace="monitoring"})
89485312 (valor em bytes)
E a lista não pára…
Mas como podemos mostrar estas métricas em dashboards mais bonitas com gráficos e persistidas, podendo assim sempre consultá-las?
Prazer, Grafana
Grafana é uma ferramenta de analytics desenvolvida pela Grafana Labs, que permite a criação de widgets em dashboards a partir de “conectores” que trazem métricas.
Atualmente esta ferramenta suporta diversos conectores, dentre eles nosso amigo Prometheus, portanto esta combinação é poderosa para criarmos dashboards avançadas de monitoramento.
Configurando o Grafana
Vamos também rodar o Grafana dentro do cluster, portanto:
$ kubectl create deployment
prometheus-pod
--namespace=monitoring
--image=grafana/grafana
--replicas=1
--port=3000
--dry-run=consumer
--output=yaml > ./grafana-pod.yml
$ kubectl apply -f ./grafana-pod.yml
Precisamos também de um configmap que será colocando dentro da pod, que representa nosso “conector” do Prometheus:
apiVersion: v1
knowledge:
grafana.json: |
{
"apiVersion": 1,
"datasources": [
{
"name": "Prometheus",
"type": "prometheus",
"access":"server",
"editable": true,
"url": "http://prometheus-svc.monitoring.svc.cluster.local",
"version": 1
}
]
}
variety: ConfigMap
metadata:
creationTimestamp: null
identify: grafana-config
namespace: monitoring
E claro, não podemos esquecer de criar um Service para o Prometheus, pois assim a pod do Grafana consegue “conversar” com a pod do Prometheus.
Nota: lembrando que Companies no Kubernetes resolvem problema de discovery de Pods, okay?
apiVersion: v1
variety: Service
metadata:
identify: prometheus-svc
labels:
app: prometheus-svc
spec:
kind: NodePort
selector:
app: prometheus-pod
ports:
- protocol: TCP
port: 80
targetPort: 9090
Após o devido apply, vamos subir o Grafana:
$ kubectl -n monitoring port-forward deploy/grafana-pod 3000:3000
Forwarding from 127.0.0.1:3000 -> 3000
Forwarding from [::1]:3000 -> 3000
Abra localhost:300, coloque as credenciais (inicialmente são admin | admin), mas no passo seguinte o app irá pedir para mudar de password.

Criando Dashboards no Grafana
Adicionar panels, widgets e dashboards é uma tarefa que requer bastante paciência e atenção ao detalhe, uma vez que os dados serão a “fonte da verdade”.
Entretanto a comunidade do Grafana vem fazendo um ótimo trabalho desenvolvendo dashboards com várias visualizações e tipos de widgets diferentes, facilitando a importação de dashboards apenas utilizando ID.
Para poupar tempo neste artigo, eu criei uma dashboard do zero com alguns widgets que mostram utilização de CPU e memória, e felizmente é possível exportar uma versão json completa do dashboard, que deixei neste Gist.
Importando uma Dashboard
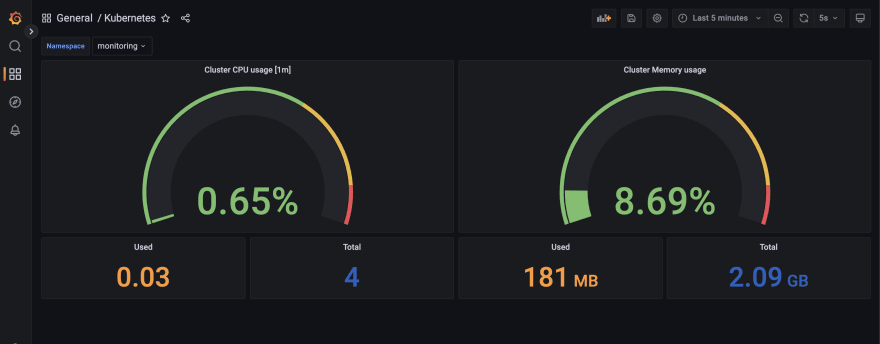
Precisamos então, na área de criação de dashboards, importar bastando copiar e colar o json que está no gist, conforme imagem abaixo:

E voilà! Temos uma dashboard prontinha com métricas de CPU e memória do nosso cluster!
Passo additional: persistência
Lembra que falei sobre ter uma dashboard persistida? Pois é, por padrão, containers não compartilham storage com o host, mas Kubernetes permite resolver isto com PersistentVolumes, para então atribuir estes PVs a containers.
Parece complicado, mas não é. Vamos primeiro criar um StorageClass que representa o tipo de armazenamento.
Cada ambiente tem um tipo de storage provisioner, e no meu caso estou utilizando o Docker for Mac, que tem um provisioner chamado docker.io/hostpath.
apiVersion: storage.k8s.io/v1
variety: StorageClass
metadata:
identify: normal
provisioner: docker.io/hostpath
E vamos supor que queremos atribuir 1GB de storage para que o Grafana guarde os dados persistidos.
apiVersion: v1
variety: PersistentVolumeClaim
metadata:
identify: grafana-pvc
spec:
storageClassName: normal
accessModes:
- ReadWriteMany
assets:
requests:
storage: 1Gi
Um PersistentVolumeClaim serve para, a partir de um Storage Class, “declarar” o modo de acesso, capacidade, and so forth.
And nowww (com sotaque do Supla), “montar” o PVC como quantity na Pod:
...
spec:
volumes: <------ declaração dos volumes
- identify: grafana-persistent-volume
persistentVolumeClaim:
claimName: grafana-pvc <---- PVC
containers:
- picture: ...
identify: grafana
ports:
- ...
volumeMounts: <--- montar volumes declarados na Pod
- identify: grafana-persistent-volume
mountPath: /var/lib/grafana
Apply na coisa toda e…tudo funciona lindamente, né?
Conclusão
Este artigo foi um overview básico nas métricas do cAdvisor. Podemos fazer muito mais coisas, que serão adicionadas ao longo dos próximos artigos.

{kind=link}